ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 04.12.2023
Просмотров: 193
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
1. Классификация возможных архитектур информационных систем
7. Функциональная логика приложений
8. Различная физическая реализация логической модели
3. HTTP-аутификация средствами PHP.
4. Создание GIF-файлов с помощью PHP.
5. Поддержка file upload. Поддержка HTTP cookie. Поддержка баз данных.
КОНСПЕКТ ЛЕКЦИЙ
междисциплинарного курса
МДК.03.04. WEB-ПРОГРАММИРОВАНИЕ
Специальность 09.02.03 Программирование в компьютерных системах
Квалификация выпускника – Техник-программист
Форма обучения – Очная
2016 г
Содержание
Тема 1.Архитектуры информационных приложений. Взаимодействие типа «клиент-сервер» 4
Файл-серверные приложения 4
Клиент-серверные приложения 6
2. Архитектуры корпоративных информационных систем 10
3. Архитектура, предназначенная для построения глобальных распределенных информационных приложений 12
4. Архитектура информационной системы основывается на концепции "склада данных" 14
5. Логическая трехзвенная модель Web-приложений 17
6. Представления данных 18
Обработка данных в системах клиент/сервер 19
Принципы обмена данными 19
7. Функциональная логика приложений 19
Неформальное описание АРI-интерфейса 20
Определение АРI-интерфейса 21
Сводные данные по АРI-интерфейсу 22
8. Различная физическая реализация логической модели 23
9. Трехзвенная система. Тонкий клиент. Толстый клиент 24
Тема 2.Принципы гипертекстовой разметки. Структура документов HTML 25
1. Язык гипертекстовой разметки HTML 25
2. Группы тэгов НТМL 28
3. Контейнеры HTML-документа 30
4. Контейнеры документа НТМL – HEAD, НТМL – BODY 30
Контейнеры тела документа НТМL - BODY 32
5. Тэги управления отображением символов 33
Таги управления отображением символов 36
Таги, управляющие формой отображения 36
Верхние и нижние индексы [НТМL 3.0] 36
Тэги, управляющие формой отображения 36
Таги, характеризующие тип информации 37
Табуляция 38
Списки 39
Атрибуты маркеров в ненумерованном списке39
Гипертекстовые ссылки 41
Графика 43
Ограничивающие прямоугольники и атрибуты АLТ= 45
Как задать размеры графики 45
Активные изображения 46
Где помещать активное изображение: на сервере или у клиента? 46
Как сделать активное изображение 47
Как поместить активное изображение на НТМL-страницу 47
Активные изображения на сервере 47
Активные изображения у клиента 48
Активные изображения, работающие и на сервере, и у клиента 49
Изображения в миниатюре 49
Средства описания таблиц в HTML 49
Создание разноцветных таблиц 58
Цветные границы в Netscape Navigator 58
6. Фреймы. Формы. DHTML. 59
Что такое фрейм? 59
Для чего можно использовать фреймы 60
Как работают фреймы 60
Создание простой страницы с фреймами 60
Задание фреймовой структуры 60
Подготовка содержимого фрейма 61
Подготовка фрейма main 62
Специфические таги и атрибуты фреймов 63
"Волшебные" целевые фреймы 65
Вложенные и множественные кадровые структуры 65
Формы 66
Как сделать так, чтобы ваша форма хорошо смотрелась 66
Как заставить формы работать 67
Тема 3.Управление просмотром страниц Web-узла. JavaScript 68
2. Описание иерархии классов 68
3. Методы объектов и свойства объектов 69
Типы данных 69
Выражения 71
Операции 71
Операции сравнения 73
Строковые операции 73
Булевы операции 74
Приоритет операций 74
4. Управление потоком вычислений 74
5. События. Массивы. Графика. 75
События 75
Массивы 76
Графика 76
6. Стеки гипертекстовых ссылок 78
7. Java, JavaScript и Plug-ins. Встраивание в HTML-документ 78
Java, JavaScript и Plug-ins 78
Встраивание в HTML-документ 79
Тема 4.Технология PHP 80
1. Введение в PHP. 80
2. Возможности PHP3. 80
3. HTTP-аутификация средствами PHP. 81
4. Создание GIF-файлов с помощью PHP. 82
5. Поддержка file upload. Поддержка HTTP cookie. Поддержка баз данных. 82
Поддержка file upload 82
Поддержка HTTP cookie 83
Поддержка баз данных 83
6. Регулярные выражения. 83
7. Обработка ошибок. 84
-
Архитектуры информационных приложений. Взаимодействие типа «клиент-сервер»
1. Классификация возможных архитектур информационных систем
В данном разделе приводится классификация возможных архитектур информационных систем. Мы начинаем с традиционных архитектурных решений, основанных на использовании выделенных файл-серверов или серверов баз данных. Затем рассматриваются варианты архитектур корпоративных информационных систем, базирующихся на технологии Internet (Intranet-приложения). Следующая разновидность архитектуры информационной системы основывается на концепции "склада данных" (DataWarehouse) - интегрированной информационной среды, включающей разнородные информационные ресурсы. Наконец, последняя выделяемая нами архитектура предназначена для построения глобальных распределенных информационных приложений с интеграцией информационно-вычислительных компонентов на основе объектно-ориентированного подхода.
Замечание по поводу терминологии. С терминологией в области информационных систем вообще, а русскоязычной терминологией в особенности дела обстоят неважно. Область информационных систем очень быстро развивается. Практически каждый год возникают новые технологии и архитектурные решения, для которых в маркетинговых целях придумываются оригинальные, привлекающие внимание названия, далеко не всегда точно отражающие смысл технологии и/или архитектуры. На самом деле, все подходы к организации информационных систем, рассматриваемые в этом курсе базируются на общей архитектуре "клиент-сервер". Различие состоит только в том, что делают клиенты и серверы. Тем не менее, чтобы не запутать читателя, далее мы вынуждены применять русскоязычные эквиваленты соответствующих англоязычных терминов.
Следует заметить, что, как и любая классификация, наша классификация архитектур информационных систем не является абсолютно жесткой. В архитектуре любой конкретной информационной системы часто можно найти влияния нескольких общих архитектурных решений. Тем не менее, при архитектурном проектировании системы кажется полезным иметь хотя бы частично ортогонализированный архитектурный базис. В следующих частях курса мы подробно рассмотрим особенности каждой архитектуры и остановимся на методологиях и инструментально-технологических средствах, поддерживающих проектирование и разработку информационных систем в соответствующей архитектуре.
Файл-серверные приложения
По всей видимости, организация информационных систем на основе использования выделенных файл-серверов все еще является наиболее распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Чем привлекает такая организация не очень опытных в области системного программирования разработчиков информационных систем? Скорее всего, тем, что при опоре на файл-серверные архитектуры сохраняется автономность прикладного (и большей части системного) программного обеспечения, работающего на каждой PC сети. Фактически, компоненты информационной системы, выполняемые на разных PC, взаимодействуют только за счет наличия общего хранилища файлов, которое хранится на файл-сервере. В классическом случае в каждой PC дублируются не только прикладные программы, но и средства управления базами данных. Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти (Рисунок 1Error: Reference source not found).
Не останавливаясь подробно на имеющихся на сегодняшнем рынке перспективных инструментальных средствах разработки файл-серверных приложений и не приводя анализа тенденций развития соответствующих технологий (этому посвящается третья часть курса), мы кратко перечислим основные достоинства и недостатки файл-серверных архитектур.
Конечно, основным достоинством является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS-DOS, Windows или какого-либо облегченного варианта Windows NT. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД. Но во многом эта простота является кажущейся. (Как гласит русская пословица, "Простота хуже воровства", а здесь мы, как правило, имеем простоту на основе воровства программных продуктов для PC.)
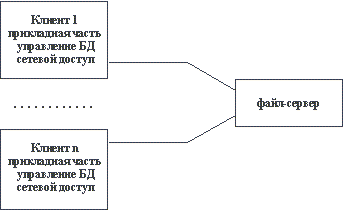
Рисунок 1– Классическое представление информационной системы в архитектуре "файл-сервер"
Во-первых, информационной системе предстоит работать с базой данных. Следовательно, эта база данных должна быть спроектирована. Почему-то часто разработчики файл-серверных приложений считают, что по причине простоты средств управления базами данных проблемой проектирования базы данных можно пренебречь. Конечно, это неправильно. База данных есть база данных. Чем качественнее она спроектирована, тем больше шансов впоследствии эффективно использовать информационную систему. Естественно, сложность проектирования базы данных определяется объективной сложностью моделируемой предметной области. Но, собственно, из чего должно следовать, что файл-серверные приложения пригодны только в простых предметных областях?
Во-вторых, как мы неоднократно подчеркивали в первой части курса, необходимыми требованиями к базе данных информационной системы являются поддержание ее целостного состояния и гарантированная надежность хранения информации. Минимальными условиями, при соблюдении которых можно удовлетворить эти требования, являются:
-
наличие транзакционного управления, -
хранение избыточных данных (например, с применением методов журнализации), -
возможность формулировать ограничения целостности и проверять их соблюдение.
В принципе, файл-серверная организация, как она показана на рисунке 2.1, не противоречит соблюдению отмеченных условий. В качестве примера системы, соблюдающей выполнение этих условий, но основанной на файл-серверной архитектуре, можно привести популярный в прошлом "сервер баз данных" Informix SE.
Длинноезамечание: Для сохранения четкости дальнейшего изложения нам необходимо несколько уточнить терминологию. Мы недаром написали "сервер баз данных" в кавычках применительно к СУБД Informix SE. При использовании этой системы копия программного обеспечения СУБД поддерживалась для каждого инициированного пользователем сеанса работы с СУБД. Грубо говоря, для каждого пользовательского процесса, взаимодействующего с базой данных создавался служебный процесс СУБД, который выполнялся на том же процессоре, что и пользовательский процесс (т.е. на стороне клиента). Каждый из этих служебных процессов вел себя фактически так, как если бы был единственным представителем СУБД. Вся синхронизация возможной параллельной работы с базой данных производилась на уровне файлов внешней памяти, содержащих базу данных. Условимся впредь называть такие СУБД не серверами баз данных, а системами управления базами данных, основанными на файл-серверной архитектуре (СУБД-ФС).
Под истинным сервером баз данных мы будем понимать программное образование, привязанное к соответствующей базе (базам) данных, существующее, вообще говоря, независимо от существования пользовательских (клиентских) процессов и выполняемое, вообще говоря (хотя и не обязательно) на выделенной аппаратуре (мы намеренно используем не очень конкретные термины "программное образование" и "выделенная аппаратура", потому что их конкретное воплощение различается в разных серверах баз данных).
Истинные серверы баз данных существенно сложнее по организации, чем СУБД-ФС, на зато обеспечивают более тонкое и эффективное управление базами данных. Везде далее в этом курсе при употреблении термина "сервер баз данных" мы будем иметь в виду истинные серверы баз данных.