ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 04.12.2023
Просмотров: 195
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
1. Классификация возможных архитектур информационных систем
7. Функциональная логика приложений
8. Различная физическая реализация логической модели
3. HTTP-аутификация средствами PHP.
4. Создание GIF-файлов с помощью PHP.
5. Поддержка file upload. Поддержка HTTP cookie. Поддержка баз данных.
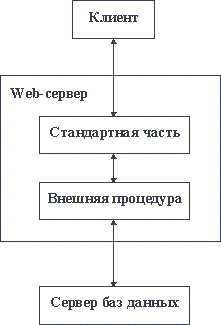
Рисунок 8 – Доступ к базе данных в Intranet-системе
Конечно, мы привели только грубую схему организации доступа к базам данных. Более детальное обсуждение содержится в пятой части курса.
На принципах использования внешних процедур основывается также возможность модификации документов, поддерживаемых Web-сервером, а также создание временных "виртуальных" HTML-страниц.
Даже начальное введение в Intranet было бы неполным, если не упомянуть про возможности языка Java. Java - это интерпретируемый объектно-ориентированный язык программирования, созданный на основе языка Си++ с удалением из него таких "опасных" средств как адресная арифметика. Мобильные коды (апплеты), полученные в результате компиляции Java-программы, могут быть привязаны в HTML-документу. В этом случае они поступают на сторону клиента вместе с документом и выполняются либо автоматически, либо по явному указанию. Апплет может быть, в частности, специализирован как шлюз к серверу баз данных (или к какому-либо другому серверу). При применении подобной техники доступа к базам данных схема организации Intranet-системы (Рисунок 9).
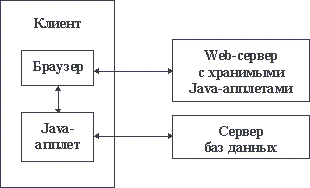
Рисунок 9 – Доступ к базе данных на стороне клиента Intranet-системы
На наш взгляд, Intranet является удобным и мощным средством разработки и использования информационных систем. Как мы уже отмечали, единственным относительным недостатком подхода можно считать постоянное изменение механизмов и естественное отсутствие стандартов. С другой стороны, если информационная система будет создана с использованием текущего уровня технологии и окажется удовлетворяющей потребностям корпорации, то никто не будет обязан что-либо менять в системе по причине появления более совершенных механизмов.
3. Архитектура, предназначенная для построения глобальных распределенных информационных приложений
Нет никаких проблем, если с самого начала информационное приложение проектируется и разрабатывается в духе подхода открытых систем: все компоненты являются мобильными и интероперабельными, общее функционирование системы не зависит от конкретного местоположения компонентов, система обладает хорошими возможностями сопровождаемости и развития. К сожалению, на практике этот идеал является трудно достижимым. По разным причинам (мы перечислим некоторые из них ниже) возникают потребности в интеграции независимо и по-разному организованных информационно-вычислительных ресурсов. Видимо, ни в одной действительно серьезной распределенной информационной системе не удастся обойтись без применения некоторой технологии интеграции. К счастью, теперь существует путь решения этой проблемы, который сам лежит в русле открытых систем, - подход, предложенный крупнейшим международным консорциумом
OMG (Object Management Group).
Остановимся на некоторых факторах, стимулирующих использование методов интеграции разнородных информационных ресурсов (здесь используются материалы статьи Л.А.Калиниченко и др. из журнала "СУБД" N 4, 1995 г.).
-
Неоднородность, распределенность и автономность информационных ресурсов системы. Неоднородность ресурсов может быть синтаксической (при их представлении используются, например, разные модели данных) и/или семантической (используются разные виды семантических правил, детализируются и/или агрегируются разные аспекты предметной области). Возможна и чисто реализационная неоднородность информационных ресурсов, обусловленная использованием разных компьютерных платформ, операционных систем, систем управления базами данных, систем программирования и т.д. -
Потребности в интеграционном комплексировании компонентов информационной системы. Очевидно, что наиболее естественным способом организации сложной информационной системы является ее иерархически-вложенное построение. Более сложные функционально-ориентированные компоненты строятся на основе более простых компонентов, которые могли проектироваться и разрабатываться независимо (что порождает неоднородность; ниже мы приведем примеры). -
Реинжинерия системы. После создания начального варианта информационной системы неизбежно последует процесс ее непрерывных переделок (реинжинерии), обусловленный развитием и изменением соответствующих бизнес-процессов корпорации. Реконструкция системы не должна быть революционной. Все компоненты, не затрагиваемые процессом реинжиниринга, должны сохранять работоспособность. -
Решение проблемы унаследованных (legacy) систем. Любая компьютерная система (надеюсь, что это не относится к открытым системам в теперешнем понимании; только надеюсь, поскольку неизвестно, как отнесутся к нашим взглядам будущие поколения) со временем становится бременем корпорации. Постоянно (и чем раньше, тем лучше) приходится решать задачу встраивания устаревших информационных компонентов в систему, основанную на новой технологии. Нужно, чтобы эта задача была разрешимой, т.е. чтобы компоненты унаследованных систем сохраняли интероперабельность. -
Повторно используемые (reusable) ресурсы. Технология разработки информационных систем должна способствовать использованию уже существующих компонентов, что в конечном итоге должно перевести нас от экстенсивного ручного программистского труда к интенсивным методам сборки ориентированной на конкретную область применения информационной системы. -
Продление жизненного цикла информационной системы. Чем дольше живет и приносит пользу информационная система, тем это выгоднее для корпорации. Естественно, что для этого должна существовать возможность добавления в нее компонентов, спроектированных и разработанных, вообще говоря, в другой технологии.
Решение проблемы интеграции неоднородных информационных ресурсов началось с попыток интеграции неоднородных баз данных. Направление интегрированных или федеративных систем неоднородных БД и мульти-БД появилось в связи с необходимостью комплексирования систем БД, основанных на разных моделях данных и управляемых разными СУБД.
Основной задачей интеграции неоднородных БД является предоставление пользователям интегрированной системы глобальной схемы БД, представленной в некоторой модели данных, и автоматическое преобразование операторов манипулирования БД глобального уровня операторы, понятные соответствующим локальным СУБД. В теоретическом плане проблемы преобразования решены, имеются реализации.
При строгой интеграции неоднородных БД локальные системы БД утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать локальную автономность, желая тем не менее иметь возможность работать со всеми локальными СУБД на одном языке и формулировать запросы с одновременным указанием разных локальных БД, развивается направление мульти-БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы именования для доступа к объектам локальных БД. Как правило, в таких системах на глобальном уровне допускается только выборка данных. Это позволяет сохранить автономность локальных БД.
Как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности. Как правило, для внешнего представления интегрированных и мульти-БД используется (иногда расширенная) реляционная модель данных. В последнее время все чаще предлагается использовать объектно-ориентированные модели, но на практике пока основой является реляционная модель. Поэтому, в частности, включение в интегрированную систему локальной реляционной СУБД существенно проще и эффективнее, чем включение СУБД, основанной на другой модели данных. Основным недостатком систем интеграции неоднородных баз данных является то, что при этом не учитываются "поведенческие" аспекты компонентов прикладной системы. Легко заметить, что даже при наличии развитой интеграционной системы, большинство из указанных выше проблем не решается. Естественным развитием взглядов на информационные ресурсы является их представление в виде набора типизированных объектов, сочетающих возможности сохранения информации (своего состояния) и обработки этой информации (за счет наличия хорошо определенного множества методов, применимых к объекту). Наиболее существенный вклад в создание соответствующей технологии внес международный консорциум OMG, выпустивший ряд документов, в которых специфицируются архитектура и инструментальные средства поддержки распределенных информационных систем, интегрированных на основе общего объектно-ориентированного подхода.
В базовом документе специфицируется эталонная модель архитектуры (OMA - Object Management Architecture) распределенной информационной системы (Рисунок 10).
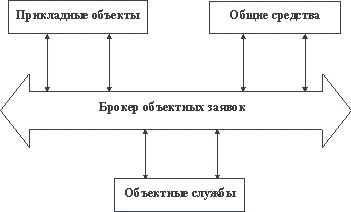
Рисунок 10 – Эталонная модель OMA
Согласованная с архитектурой OMA прикладная информационная система представляется как совокупность классов и экземпляров объектов, которые взаимодействуют при поддержке брокера объектных заявок (ORB - Object Request Broker). ORB, общие средства (Common Facilities) и объектные службы (Object Services) относятся к категории промежуточного программного обеспечения (middleware) и должны поставляться вместе. Объектные службы представляют собой набор услуг (интерфейсов и объектов), которые обеспечивают выполнение базовых функций, требуемых для реализации прикладных объектов и объектов категории "общие средства" (например, специфицированы служба именования объектов, служба долговременного хранения объектов, служба управления транзакциями и т.д.). Общие средства содержат набор классов и экземпляров объектов, поддерживающих функции, полезные в разных прикладных областях (например, средства поддержки пользовательского интерфейса, средства управления информацией и т.д.).
В основе OMA лежит базовая объектная модель COM (Core Object Model), в которой специфицированы такие понятия, как объект, операция, тип, подтипизация, наследование, интерфейс. Определены также способы согласованного расширения COM в разных объектных службах.
Интерфейсы объекта-клиента и объекта-сервера должны быть определены на специальном языке IDL (Interface Definition Language), который очень напоминает компонент спецификации класса (без реализации) языка Си++. Обращения к ORB могут быть сгенерированы статически при компиляции спецификаций IDL или выполнены динамически с использованием специфицированного в документах OMG API брокера объектных заявок. Правила построения и использования ORB определены в документе OMG CORBA (Common Object Request Broker Architecture).
В седьмой части курса мы рассмотрим более подробно все понятия, введенные в этом разделе.
Основным выводом из материала данного раздела является то, что проблемы интеграции неоднородных информационных ресурсов являются актуальными для корпораций и существуют технологии, позволяющие решать эти проблемы.
4. Архитектура информационной системы основывается на концепции "склада данных"
До сих пор мы рассматривали способы и возможные архитектуры информационных систем, предназначенных для оперативной обработки данных, т.е. для получения текущей информации, позволяющей решать повседневные проблемы корпорации. Однако у аналитических отделов корпорации и у высшего звена управляющего состава имеются и другие задачи: проанализировав поведение корпорации на рынке с учетом сопутствующих внешних факторов и спрогнозировав хотя бы ближайшее будущее, выработать тактику, а возможно, и стратегию корпорации. Понятно, что для решения таких задач требуются данные и прикладные программы, отличные от тех, которые используются в оперативных информационных системах. В последние несколько лет все более популярным становится подход, основанный на концепциях склада данных и системы оперативной аналитической обработки данных. Возможно, в российских условиях трудно производить долговременные прогнозы бизнес-деятельности (слишком изменчивы внешние факторы), но анализ прошлого и краткосрочные прогнозы будущего могут оказаться очень полезными.
Прежде чем перейти к обсуждению технических аспектов, коротко обсудим проблемы терминологии. Поскольку термины, связанные со складами данных не так давно появились и на английском языке, и смысл их постоянно уточняется, трудно найти правильные русскоязычные эквиваленты. На сегодняшний день "datawarehouse" разными авторами переводится на русский язык как "хранилище данных", "информационное хранилище", "склад данных". Поскольку термин "хранилище" явно перегружен (он соответствует и английским терминам "storage" и "repository"), в этом курсе мы будем использовать термин "склад данных". Еще хуже дела обстоят с термином "data mart". В четвертом номере журнала "СУБД" за 1996 г. в напечатанных подряд двух статьях авторы переводят этот термин как "витрина данных" и "секция данных" соответственно. Однако в Оксфордском толковом словаре единственным подходящем по смыслу толкованием смысла слова "mart" является "market place". Чтобы не умножать число требуемых сущностей мы будем использовать термин "рынок данных" (обсуждение этого понятия отложим до пятой части курса). Конечно, постепенно терминология будет согласована, но это произойдет только тогда, когда склады данных будут активно использоваться в России.
В этом разделе мы не будем рассматривать возможные технологические приемы реализации складов данных, а обсудим соответствующие вопросы на концептуальном уровне. Начнем с того, что главным образом различает оперативные и аналитические информационные приложения с точки зрения обеспечения требуемых данных.