ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 352
Скачиваний: 5
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Вспомним одно из основных положений теории вероятностей. Независимость двух событий означает, что вероятность наступления обоих событий вместе равна произведению вероятностей наступления каждого из них в отдельности. Учитывая это, нетрудно видеть, что в нашем случае независимость двух признаков с номерами i и j означает, что
Pt=P,Pj- (?-2>
Однако в действительности, если предположить, что признаки упорядочены в нашем смысле (и / < j), то окажется, что р.= = pi(для нашего примера со шкалой Богардуса — вероятность того, что респондент согласен допустить рассматриваемого человека одновременно и в качестве соседа, и в качестве согражданина, равна вероятности того, что он допустит этого человека в качестве соседа, поскольку второе требование само собой будет выполнено). Поскольку соотношение (7.2) не выполняется, то признаки зависимы.
Если же взять только тех людей, которые имеют одно и то же значение латентной переменной, то, как нетрудно проверить, для них однозначно восстанавливается картина их ответов на рассматриваемые вопросы: скажем, балл 5 респондент может иметь только в том случае, если он дал положительные ответы на последние 5 вопросов. Другими словами, респонденты с одним и тем же значением латентной переменной имеют одни и те же значения рассматриваемых признаков. Ни о какой связи тут говорить не приходится.
Гуттман предложил простой алгоритм, позволяющий либо привести матрицу к диагональному виду, либо показать, что это сделать в принципе невозможно. Прежде чем описать этот алгоритм, заметим, что мы должны учитывать еще одно обстоятельство.
Выше в действительности был описан некий идеальный случай. Мы уже говорили, что в социологии практически никакая теоретическая схема никогда не проходит в совершенно "чистом" виде, никакая гипотеза не может стопроцентно выполняться, никакие данные не бывают без ошибок. И всегда встает вопрос
, в каких пределах эти ошибки допустимы.
В нашем случае это означает, что даже при самом тщательном подборе суждений всегда найдутся респонденты, для которых они не будут упорядочены предполагаемым нами образом (в подтвер-" ждение того, что ошибки всегда будут, напомним, как уже мы говорили, что человек, ответивший положительно на третий вопрос, почти наверняка, но не наверняка (!) даст положительный ответ на четвертый и пятый). То есть наша матрица хотя бы в малой мере, но практически всегда не будет точно диагональной. Необходимо, как всегда в подобных случаях, установить предел допустимых ошибок (напомним, что мы так же поступили, например, когда говорили о возможных нарушениях транзитивности в матрицах парных сравнений). В ситуации, когда этот предел не будет превышен, считать, что матрица диагональна, и, следовательно, наши условия, обеспечивающие возможность использования тестовой традиции, выполняются. Если ошибки превы-
сят допустимый предел, то будем полагать, что матрицу нельзя привести к диагональному виду и, стало быть, нельзя описанным образом измерять латентную переменную.
Ошибки будут проявляться в том, что даже в самом хорошем варианте у нас в области плюсов будут одиночные минусы, и наоборот. Оценим количество таких смешений. Их ниже мы и называем ошибками. Введем критерий:
R= 1 — (количество ошибок)/(количество клеток в таблице).
Будем полагать, что мы привели матрицу к диагональному виду, если R< 0,9. Теперь на примере покажем, в чем состоит алгоритм Гуттмана и как можно оценить качество его работы.
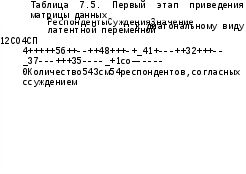
Итак, пусть исходная матрица данных имеет вид (табл. 7.4).
Таблица 7.4. Фрагментгипотетическойматрицыданных, полученныхспомощьюшкалыГуттмана
| Респонденты | Суждения | Значение латентной переменной | |||||
| 1 | 2 | со | 4 | 5 | 6 | ||
| 1 | + | - | - | - | + | + | 3 |
| см | + | + | + | - | - | - | со |
| со | - | - | - | - | - | - | 0 |
| 4 | + | + | + | + | + | - | 5 |
| СП | - | - | - | - | - | + | 1 |
| 6 | + | + | - | - | + | + | 4 |
| 7 | - | - | - | + | + | + | 3 |
| 8 | + | + | + | - | + | - | 4 |
В соответствии с упомянутым алгоритмом сначала надо таким образом переставить строки, чтобы соответствующие им значения измеряемой переменной расположились по убыванию (табл. 7.5).
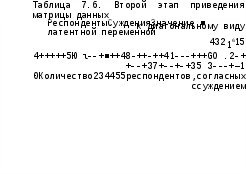
Не зря мы ввели в таблицу еще одну строку. Теперь надо переставить столбцы таблицы таким образом, чтобы возрастали ранги, стоящие в ее нижней, как бы маргинальной, строке (табл. 7.6).
Строго диагонального (ступенчато-диагонального) вида у нас не получилось. Теперь требуется оценить, можно ли все же считать, что полученная матрица достаточно близка к диагональному виду.
R = I - (6 + 3)/ 48 = 0,81
(6 — количество плюсов, "заблудившихся" в минусовой области; 3 — количество минусов, находящихся в плюсовой области). Если такое значение критерия представляется неприемлемым (19% "неправильных" клеток в таблице), то приходим к выводу, что наша гипотеза о наличии латентной переменной, проявляющейся в рассматриваемых наблюдаемых признаках, не верна.
Итак, наша работа начинается с того (имеется в виду этап работы после предварительного формирования анкеты), что мы проводим пробное исследование, собираем данные и переставляем столбцы и строки полученной матрицы до тех пор, пока она либо приобретет диагональный вид, либо мы убедимся в том, что это сделать невозможно. В первом случае мы полагаем, что одномерная латентная переменная существует, признаки и способ выражения через них латентной переменной выбраны удачно, и переходим к основному исследованию. Во втором — вообще говоря, отказываемся от построения одномерной шкалы. Однако в отдельных случаях исправить положение можно с помощью некоторой корректировки данных. Скажем, может оказаться, что привести матрицу к диагональному виду нам мешает какой-то ее столбец. Тогда выбросим из рассмотрения соответствующее суждение: оно не укладывается в наше упорядочение (может быть, не так понимается респондентами, как мы рассчитывали, и т.д.). Затем перейдем к основному исследованию. В приведенном выше примере таким суждением можно считать шестое (правда, убрав его, мы уменьшим долю "неправильных" клеток не до 10%, а только до 12% (стало быть, Rбудет равно 0,88).
Может оказаться и так, что нам "мешает" строка матрицы, т.е. какой-то респондент. Можно отбросить и его и двигаться дальше. Но здесь надо быть осторожными, о чем мы уже говорили.
Перейдем к рассмотрению еще одного метода одномерного шкалирования — метода, предложенного Лазарсфельдом и представляющегося нам вершиной тестового подхода, поскольку здесь поставленные выше задачи решаются своеобразным и, на наш взгляд, более адекватным образом, чем при использовании других шкал. Объясняется это, вероятно, тем, что Лазарсфельд, будучи сторонником внедрения естественнонаучных методов в социологические исследования, взглянул на процесс построения шкалы с теоретико-вероятностной точки зрения, столь распространенной в естественных науках.
7.6. Латентно-структурный анализ (ЛСА) Лазарсфельда
7.6.1. ПростейшийвариантЛСА: входивыход
Рассмотрим частный случай ЛСА — тот, который в свое время был предложен самим Лазарсфельдом. Перейдем к его описанию, подчеркнув, что тех ограничений, к перечислению которых мы переходим, при настоящем состоянии техники ЛСА можно и не делать (о развитии ЛСА можно прочесть в [Гибсон, 1973; Дегтярев, 1981, Ι995; Лазарсфельд, 1966, 1973; Осипов, Андреев, 1977, с. 140—151; Статистические методы анализа..., 1979, с. 249—266; Типология и классификация..., 1982, с. 99— 111; Lazarsfeld, Henry, 1968]; о некоторых аспектах применения этого подхода в социологии см. также [Батыгин, 1990; Социальные исследования..., 1978, с. 15]).
В своих работах Лазарсфельд неоднократно упоминает о том, что его подход имеет самое непосредственное отношение к теории тестов. Начнем описание ЛСА в соответствии со сформулированными выше принципами тестовой традиции.
Итак, мы предполагаем, что имеется совокупность респондентов, для которых существует одномерная латентная номинальная переменная с заданным числом градаций к. Пусть для определенности к = 2. Имеется анкета с N дихотомическими вопросами. Предполагается, что вопросы подобраны таким образом, что респонденты с разными значениями латентной переменной почти всегда по-разному будут отвечать на вопросы анкеты, а с одним и тем же значением — как правило, будут давать примерно одинаковые ответы. Предположим также, что за счет этого связь между наблюдаемыми переменными можно объяснить действием латент-ной переменной.
Приведем пример. Пусть наши респонденты — московские студенты, латентная переменная — их отношение к будущей специальности. Вопросы имеют примерно такой вид:
1) Часто ли Вы посещаете библиотеку (не реже раза в неделю)?
-
Имеется ли у Вас домашняя библиотека из книг по специальности (не менее 10 книг)? -
Читали ли Вы когда-нибудь книгу по специальности по собственной инициативе, без рекомендации ее преподавателем? -
Были ли у Вас двойки на экзаменах? -
Случалось ли Вам, присутствуя на лекции, слушать плейер? -
Часто ли Вы пропускаете лекции (более трех лекций в неделю)?
Ясно, что студенты, мечтающие о работе по приобретаемой специальности, будут на первые три вопроса давать, как правило, положительные ответы, а на последние три — отрицательные. А для студентов, равнодушно или негативно относящихся к выбранной специальности, будет иметь место обратная картина.
Ясно также, что между рассматриваемыми наблюдаемыми переменными будет иметься статистическая связь и что ее, всего вероятнее, можно будет объяснить действием латентной переменной. Это проявится в том, что при фиксации значения латентной переменной эта связь пропадет. Заметим, что это, уже неодно-кратно упоминаемое нами положение, Лазарсфельд первым четко сформулировал и назвал аксиомой локальной независимости.
Исходной информацией для ЛСА служат частотные таблицы произвольной размерности (размерность таких таблиц зависит от заданного числа значений латентной переменной). Обозначим через р.—вероятность положительного ответа наших респондентов на /'-й вопрос (долю респондентов, давших такой ответ); через р.. — вероятность положительных ответов одновременно и на /'-й, и на у'-й вопросы; через ρ к— вероятность положительных ответов одновременно на г'-й,у'-й и к-й вопросы и т.д.
Те же буквы с индексом 1 наверху (р/, />..', ρ к')будут обозначать соответствующие частоты для первого латентного класса, с индексом 2 наверху (pf, ρ 2 , pjjk) — то же для второго латентного класса.
р.-к — вероятность положительного ответа на /-й и к-й вопросы и одновременно — отрицательного ответа на у'-й вопрос.
V, V2 — доли латентных классов в общей совокупности респондентов.
Рассмотрим произвольный набор ответов на вопросы анкеты, например, +н—I—К Через Ρ (1/+-Ι—ι-—Н) обозначим вероятность того, что респондент, давший набор ответов +н—\— + , попал в первый латентный класс, а через Ρ (2/+Η—I—Η) — то же, для второго латентного класса.
Для описания исходных данных и результатов применения ЛСА прибегнем к "кибернетической" терминологии. Вход ЛСА.
Частоты любой размерности:p.,p..,pjjk.Другими словами, ЛСА работает с частотными таблицами. Это не может не привлекать социолога: метод может работать со шкалами любых типов.
Выход ЛСА.
а) Аналогичные частоты для каждого латентного класса. В нашем случае с двумя латентными классами это будут частоты вида Р/>Р,/,Р„к'"Р/,Р/,Р1]к2-
Эти совокупности частот могут рассматриваться как описания латентных классов. Анализ таких описаний может послужить для уточнения представлений о той латентной переменной, существование которой априори постулировалось, в частности, может привести исследователя к выводу о том, что ей следует дать другое название (ср. наши рассуждения о понятии "латентная переменная" в п. 1.1). Подчеркнем, что такая возможность, с одной стороны, выгодно отличает подход Лазарсфельда от остальных рассмотренных нами методов одномерного шкалирования (скажем, при использовании шкал Лайкерта или Терстоуна даже не ставится вопрос о том, что переменная может быть другой), а с другой, приближает к таким методам поиска латентных переменных, как факторный анализ и многомерное шкалирование (там проблема интерпретации осей одна из центральных). Представляется, что это характеризует ЛСА как более адекватный подход, чем другие методы одномерного шкалирования. В процессе использования последних мы фактически не считаем ту переменную, значения которой ищем, латентной — мы знаем, что это за переменная, не умеем только ее измерять "в лоб". А в случае ЛСА мы допускаем' неадекватность наших априорных представлений о сути (названии) латентной переменной. И это, на наш взгляд, ближе к тем реальным ситуациям, с которыми обычно имеет дело социолог.
Приведем пример. Положительные ответы на первые три приведенных выше вопроса могут отражать не любовь к будущей специальности, а послушание "пай-девочек" интеллигентных родителей, имеющих схожую специальность. Положительные же ответы на последние три вопроса — напротив, — самостоятельность сознательно выбравших будущую специальность молодых интеллектуалов, отрицающих необходимость для них прослушивания каких-то устаревших курсов, умеющих быстро наверстать пропущенные занятия, позволяющих себе иногда "расслабиться". Ясно, что в такой ситуации полное распределение ответов на все вопросы в найденных латентных классах может помочь исследователю скорректировать наименование латентной переменной.
Упомянем еще об одной возможной трактовке получаемых в результате применения ЛСА частотных распределений для каждого латентного класса. Каждое такое распределение можно интерпретировать как отражение той "плюралистичное™" мнений одного респондента, о которой мы говорили при обсуждении шкал Терстоуна. Можно считать, что это то самое распределение, которое отвечает одному респонденту, попавшему в соответствующий латентный класс (правда, как мы увидим ниже, ЛСА дает возможность судить лишь о вероятности такого попадания).
б) Относительные объемы классов. В нашем случае — V и V2.
Эта информация, помимо прочего, тоже может способствовать
корректировке представлений исследователя о латентной пере-
менной. Заметим (и это пригодится при решении приведенных
ниже уравнений), что V+V2= 1.
в) Вероятность Ρ (1/++-+-+) попадания объекта, давшего
набор ответов ++—I—Ь, в первый латентный класс и аналогичная
вероятность Ρ (2/++-+-+) — для второго латентного класса.
Это самое серьезное отличие ЛСА от других методов одномерного шкалирования. Представляется, что именно это отличие в наибольшей степени делает ЛСА более адекватным методом, чем другие рассмотренные подходы к построению шкал. Способ измерения с помощью анкетных опросов по своей сути довольно "груб", в силу чего даже самые "благоприятные" ответы респондента не обязательно означают его включенность в соответствующий этим ответам латентный класс. Лазарсфельд действует более тонко: говорит только о вероятности такой включенности. Именно здесь проявляется в наибольшей степени желание Лазарсфельда следовать критериям, принятым в естественных науках. Использование подобных вероятностных соотношений в этих науках общепринято. Такой подход является естественным и для самой математической статистики (социологу не мешает приглядываться к тому, что делают математики; иногда они вследствие профессиональной склонности к обобщениям предлагают более жизненные, хотя, может быть, и более сложные постановки задач, чем социолог).
7.6.2. МодельныепредположенияЛСА
Вернемся к не раз упомянутой выше "кибернетической" схеме, отражающей процесс производного измерения. Наши вход и выход связаны соотношением:
Итак, для того чтобы на базе данных величин (формирующих вход) получить искомые (выход), надо задать правила, выражающие вторые через первые (например, составить соответствующие уравнения). Каковы же соответствующие модельные представления? Сформулируем соотношения,'лежащие в основе ЛСА.
"Невооруженным" глазом видно, что количество неизвестных величин настолько превышает количество известных, что вряд ли в принципе возможно составление решаемых уравнений. Чтобы сократить количество неизвестных, вспомним аксиому локальной независимости: фиксация значения латентной переменной приводит к исчезновению связи между наблюдаемыми (это и означает, что латентная переменная объясняет связи между наблюдаемыми).
Как мы уже говорили, независимость наших/-й и у'-й переменных означает справедливость соотношения (7.2).
Ясно, что это равенство, вообще говоря, будет неверным, поскольку ответ на один вопрос (скажем, о том, имеет ли респондент библиотеку) зависит от его ответа на другой вопрос (скажем, читает ли он по собственному желанию книги по будущей профессии). А вот для лиц, принадлежащих к одному латентному классу, в соответствии с аксиомой локальной независимости подобное соотношение будет справедливым:
Pj^P'p', P?=pfpf.
Нетрудно видеть, что использование этих соотношений позволяет резко сократить количество неизвестных: если мы найдем р!и р.1,то величину pJможно будет не искать, поскольку ее легко выразить через первые две вероятности (относительные частоты). То же можно сказать и о других многомерных частотах.
Для того чтобы понять, каким образом можно составить требующиеся уравнения, вспомним формулу полной вероятности:
Подчеркнем, что, пользуясь приведенной формулой, мы тем самым предполагаем, что каждый респондент в какой-то класс обязательно попадает и не может попасть в два класса сразу. Это тоже содержательные соображения, принятие которых требует согласия с ними социолога. Первое утверждение означает, что искомая система классов является полной: мы считаем, что для каждого человека найдется в ней место. Второе утверждение заставляет нас избегать "расплывчатых" классификаций, что, однако, может быть не адекватно реальности. Этот недостаток покрывается тем, что мы лишь указываем вероятность принадлежности того или иного респондента к определенному классу, а не вычисляем точное значение латентной переменной для этого респондента.
В системе (7.3) слева — известные величины, справа — неизвестные. Ее можно решить. Мы не будем заниматься этим, отослав читателя к упомянутой в начале предыдущего параграфа литературе.
Осталось описать способ, с помощью которого рассчитываются упомянутые вероятности. Этот способ опирается на так называемую формулу Байеса: P(a/b) = (Р(а)Р(Ь/а))/Р (Ь). Здесь она превращается в
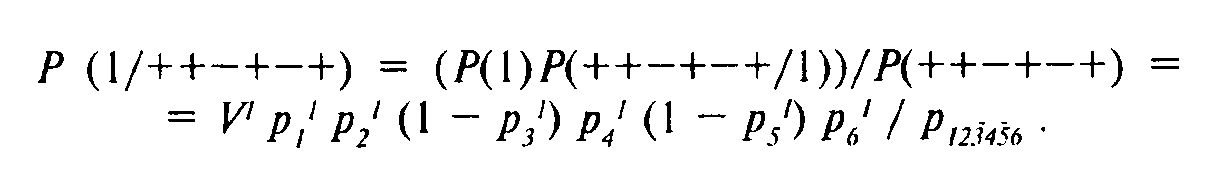
(Полагаем, что сказанное в настоящем параграфе лишний раз убедило читателя в том, что социологу необходимо знать элементы теории вероятностей).
В заключение обсудим, как же в случае ЛСА решаются сформулированные нами в п. 7.3.3 проблемы построения индексов (искомая с помощью ЛСА латентная переменная тоже своеобразный индекс).
Первую проблему ЛСА не решает: существование латентной переменной в ЛСА постулируется. Правда, представление о ней может быть скорректировано за счет анализа полученных в процессе применения метода описаний каждого латентного класса (совокупности людей, имеющих одно и то же значение латентной переменной), т.е. вычисления вероятностных распределений ответов попавших в класс респондентов на все рассматриваемые вопросы.
Наши второй и третий вопросы снимаются следующим образом. Точные значения латентной переменной для отдельных респондентов не вычисляются. Вместо этого: а) дается описание каждого латентного класса и б) для каждого возможного набора ответов на вопросы анкеты вычисляется вероятность попадания давшего эти ответы респондента в любой из латентных классов.
Тип шкалы латентной переменной в ЛСА постулируется. В рассмотренном простейшем варианте метода переменная была номинальной. Как мы уже оговаривали, в более современных (но и гораздо более сложных) вариантах метода латентная переменная может быть получена по шкале любого типа, предусматривается также ее многомерность.
1 ... 4 5 6 7 8 9 10 11 ... 14
Глава 8. ПСИХОСЕМАНТИЧЕСКИЕ МЕТОДЫ В СОЦИОЛОГИИ
8.1. Содержание методов
Мы уже говорили о том, что социолог, желающий адекватно оценивать мнение респондента, должен "дружить" с психологией. Надеемся, что читатель убедился в этом при рассмотрении в предыдущем разделе некоторых аспектов использования в социологии тестового подхода. Перейдем к изучению еще одного способа осуществления опроса, опирающегося на достижения психологии.
Прежде всего о том, что такое психосемантика. Как известно, семантика — это "раздел языкознания и логики, в котором исследуются проблемы, связанные со смыслом, значением и интерпретацией знаков и знаковых выражений". [Быстрое, 1991, с. 275]. Психосемантика же изучает психологическое восприятие человеком значений и смыслов разного рода объектов (в том числе понятий, а также знаков и знаковых выражений), процесса интерпретации им этих объектов. В нее входят разные направления, в определенной мере отличные друг от друга и по решаемым задачам, и по подходам к их решению. Наряду с методом семантического дифференциала (СД), подробно рассматриваемым в п. 8.3, сюда можно отнести метод репертуарных решеток [Дубицкая, Ионцева, 1997; Тарарухина, Ионцева, 1997; Толстова, 1997; Франселла, Баннистер, 1986] и некоторые другие подходы [Баранова, Ι993-1994; Петренко, 1983, 1988; Ка-чанов, Шматко, 1993; Шмелев, 1983]). Одна из основных задач психосемантики — построение так называемого семантического пространства, т.е. нахождение системы тех латентных факторов, в рамках которых респондент "работает", так или иначе оценивая какие-либо объекты. Необходимо подчеркнуть, что респондент, как правило, не дает себе отчета в существовании этих факторов. Семантическое пространство по существу является исследовательской моделью структуры индивидуального сознания, на основе которой происходит восприятие респондентом объектов, их классификация, сравнение и т.д.
Иногда психосемантические методы относят к проективной технике. "Особенность проективных процедур в том, что стимулирующая ситуация приобретает смысл не в силу ее объективного содержания, но по причинам, связанным с субъективными наклонностями и влечениями испытуемого, т.е. вследствие субъективированного, личностного значения, придаваемого ситуации испытуемым. Испытуемый как бы проецирует свои свойства в ситуацию" [Ядов, 1995, с. 190].
Наряду с методом СД к проективной технике относят и другие процедуры: метод незаконченных предложений, изучение разного рода ассоциаций респондентов по поводу заданного стимула и т.д. [Соколова, 1980; Ольшанский, 1994, с. 111 — 112; Ядов, 1995, с. 190-193].
Как отмечается в [Ядов, 1995, с. 193], "обоснованность проективных процедур определяется прежде всего теоретическими посылками, руководствуясь которыми исследователь истолковывает данные". Сделаем некоторые предварительные замечания соответствующего плана, касающиеся основного интересующего нас в данной работе психосемантического метода, — СД.
Метод СД направлен не только на поиск семантического пространства и анализ лежащих в его основе факторов, но и на изучение взаимного расположения объектов в этом пространстве (т.е. различий в восприятии объектов рассматриваемым респондентом). Для социолога круг задач, решаемых с помощью СД, более широк — его интересы требуют нахождения усредненных показателей соответствующего рода; выделение типов людей, обладающих сходным восприятием рассматриваемых объектов.
По существу мы здесь имеем дело с одним из частных случаев той глобальной задачи, о которой говорили в первом разделе-(п. 3.2): метод СД позволяет с помощью жесткого формализованного опроса получить более или менее адекватную информацию о довольно тонких психологических структурах восприятия человеком окружающего мира. И снова для того, чтобы в нашем "более или менее" было больше "более", чем "менее", требуется тщательное отслеживание той модели, которая дает нам возможность соединить несоединимое. Это мы и намереваемся сделать ниже.
Основой той психологической теории, на которой базируется метод СД, служат понятия "значение" и "смысл". Этим понятиям, а также их различению уделяется огромное внимание в психологической, психосемантической, психолингвистической литературе [Дридзе, 1984; Леонтьев, 1974, 1983; Ольшанский, 1994;
Соколова, 1994]. Мы не будем их подробно рассматривать. Отметим только, что оба понятия отражают общественный опыт, усваиваемый индивидом. Оба являются результатом определенной организации (классификации) сознанием человека того потока впечатлений, который последний получает от окружающего мира. Но первое отвечает коллективному опыту людей (так, ребенок присваивает готовые, исторически выработанные значения), а второе — опыту отдельного субъекта, это как бы внутренне мотивированное значение для субъекта. Первое в большей мере соответствует классификации когнитивного характера (логике ума), а второе — аффективного (логике чувств). Однако структуры и значений, и смыслов сложны. В частности, в обеих можно выделить и когнитивный, и аффективный компоненты. Нас в основном будет