Файл: Задачи данной работы изучение технического задания, полученного от предприятия.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.11.2023
Просмотров: 73
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Модель базы данных призвана отражать реальные и виртуальные объекты окружающего мира, информацию о которых мы планируем хранить и обрабатывать в разрабатываемых информационных системах. Чем точнее модель отражает действительность, тем она полезнее и, как следствие, лучше база данных [5].
На рисунке 1.1 отражены этапы развития моделей данных. Это так называемые модели реализации, т. е. модели, ориентированные на получение ответа на вопрос: «Каким образом следует описывать структуры данных?». Единственное исключение составляет понятийная модель «сущность-связь», это ближайший союзник реляционной модели, но отвечающей не за реализацию, а за логику будущей БД. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
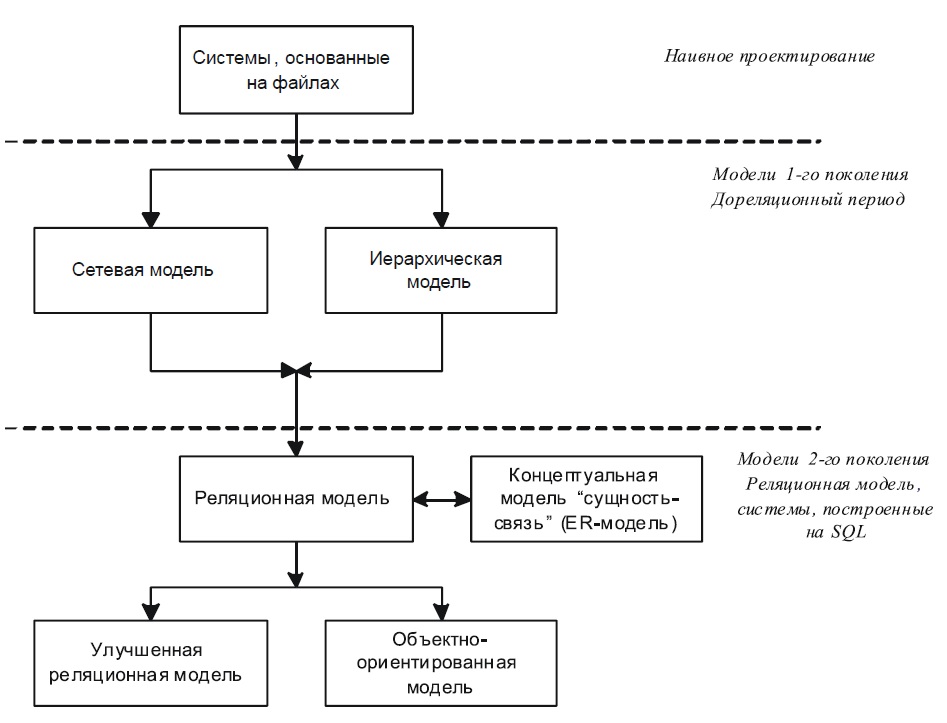
Рисунок 1.1 – Этапы развития моделей данных
1.2.2.1 Иерархическая модель
Иерархическая модель данных представляет собой совокупность элементов данных, расположенных в порядке их подчинения и образующих по структуре перевернутое дерево. С наглядной схемой можно ознакомиться взглянув на рисунок 1.2. К основным понятиям иерархической модели данных относятся: уровень, узел и связь [4].
Узел - это совокупность атрибутов данных, описывающих информационный объект.
Все узлы связывались друг с другом благодаря сложной системе указателей. Каждый из узлов, в свою очередь, мог являться родительским по отношению к одному или нескольким нижерасположенным узлам, но у дочернего узла не могло быть более одного родителя. Таким образом, в иерархической модели реализована одна из самых встречающихся в реальном мире связей между сущностями связь «один ко многим».
Иерархическая модель данных имеет некоторые недостатки:
ограничения в организации отношений между сущностями. Иерархическая модель позволяет организовать последовательную связь «один ко многим» между данными, но не в состоянии реализовать отношения «многие ко многим»;
структурная зависимость. Иерархическая структура предполагала, что физические данные также станут храниться в виде дерева;
сложность разработки программного обеспечения. Разработчик программ должен знать особенности физического хранения данных, иначе он мог просто заблудиться в запутанной системе указателей.
Ко всему прочему иерархическая модель не была стандартизирована. Как следствие всегда существовала проблема переносимости данных между приложениями различных разработчиков [4].
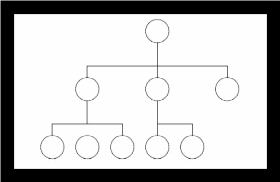
Рисунок 1.2 – Иерархическая модель
1.2.2.2 Сетевая модель
Сетевая модель данных основана на тех же основных понятиях (уровень, узел, связь), что и иерархическая модель, но в сетевой модели каждый узел может быть связан с любым другим узлом. С наглядной схемой можно ознакомиться взглянув на рисунок 1.3.
По сравнению с иерархической, сетевая модель имеет одно серьезное преимущество: она позволяет назначить произвольное количество связей между узлами графа. Поэтому можно создавать базы данных, более точно отражающие связи реального мира, в частности, в сетевых БД без особого труда можно было формировать отношения «многие ко многим» или замыкать связь узла на себя самого [4].
При удалении записи в сетевой БД уничтожается только конкретная запись и связи с ней, все остальное остается на месте. Это разительное отличие от иерархически организованной БД, ведь здесь при удалении одной записи удалению подлежала вся нижерасположенная ветвь дочерних элементов или требовалось провести относительно сложную процедуру переподчинения дочерних узлов. Впрочем, простота перестроения структуры графа имеет и свои подводные камни, ведь любое непродуманное изменение связей может привести к нарушению целостности данных. Благодаря системной информации достигается архиважный для базы фактор физической независимости приложений от данных.
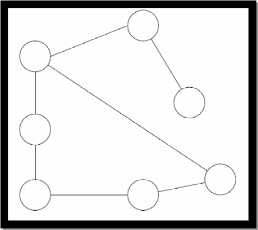
Рисунок 1.3 – Сетевая модель
К сожалению, сетевая модель также не свободна от недостатков:
большое количество произвольных связей повышает сложность схемы БД и, как следствие, вызывает дополнительные трудности при обеспечении целостности данных;
-
сложность разработки прикладного программного обеспечения.
1.2.2.3 Реляционная модель
Реляционная модель данных использует организацию данных в виде двумерных таблиц. Каждая такая таблица, называемая реляционной таблицей или отношением, представляет собой двумерный массив и обладает следующими свойствами:
все столбцы в таблице однородные, то есть все элементы в одном столбце имеют одинаковый тип и максимально допустимый размер;
-
каждый столбец имеет уникальное имя; -
одинаковые строки в таблице отсутствуют; -
порядок следования строк и столбцов в таблице не имеет значения.
Реляционная модель данных далеко не идеальна. По существу, это компромиссное решение между потребностью отражать сущности реального мира и связи между ними и ограниченными возможностями математической теории множеств переложенной на программный код [4].
В соответствии с рисунком 1.4 основными структурными элементами реляционной таблицы являются поле и запись.
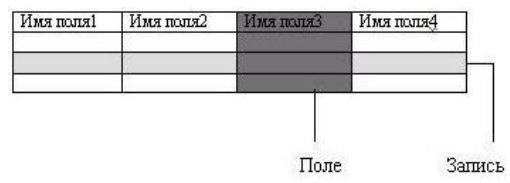
Рисунок 1.4 – Основные структурные элементы реляционной таблицы
Поле (столбец реляционной таблицы) – элементарная единица логической организации данных, которая соответствует конкретному атрибуту информационного объекта. Запись (строка реляционной таблицы) – совокупность логически связанных полей, соответствующая конкретному экземпляру информационного объекта.
Основными объектами любой базы данных являются таблицы. Таблицы базы данных создаются таким образом, чтобы каждая из них содержала информацию об одном информационном объекте. Между таблицами должны быть установлены реляционные связи. Установка таких связей делает возможным выполнение одновременной обработки данных из нескольких таблиц. Первичный ключ реляционной таблицы – это поле или группа полей, которые позволяют однозначно определить каждую запись (строку) в таблице. Первичный ключ должен обладать двумя свойствами:
однозначная идентификация. Запись должна однозначно определяться значением ключа;
отсутствие избыточности. Никакое поле нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации записи.
Если первичный ключ состоит из одного поля, то он называется простым ключом или ключевым полем. Если первичный ключ состоит из нескольких полей, то говорят, что таблица имеет составной ключ. Для установки связей между таблицами используются ключевые поля. Можно связать две реляционные таблицы, если ключ одной связываемой таблицы ввести в состав ключа другой таблицы (возможно совпадение ключей). Можно ключевое поле одной связываемой таблицы ввести в структуру другой таблицы так, что оно в этой таблице не будет ключевым. В этом случае это поле называется внешним ключом [6].
Как и все в нашем мире, реляционная модель данных далеко не идеальна. По существу, это компромиссное решение между потребностью отражать сущности реального мира и связи между ними и ограниченными возможностями математической теории множеств переложенной на программный код. Любой компромисс предполагает появление множества малоприятных ограничений. Так, из-за борьбы с избыточностью данных в реляционной БД (процесс нормализации) информация «размазывается» по нескольким нужным отношениям (таблицам). Как следствие, для получения сводной информации приходится собирать данные по крохам и осуществлять множество соединений. Чем
больше соединений, тем больше временных и ресурсных затрат. Другая проблема реляционной модели заключается в особенностях организации связи между отношениями. Для моделирования всего многообразия взаимодействия между сущностями реального мира в нашем распоряжении имеется лишь одна конструкция «один ко многим». Для создания отношения «многие ко многим» приходится выкручиваться за счет введения дополнительной соединительной таблицы и применения двух типов связей «один ко многим». Но на этом проблема построения связей не исчерпывается. Реляционная модель попросту бессильна, когда следует отразить смысловую нагрузку связи.
1.2.3 Функции СУБД
Вне зависимости от того, на основе какого подхода спроектирована современная БД, ее существование немыслимо без системы управления базами данных. Прямо или косвенно СУБД используют администраторы, разработчики БД, программисты и обычные пользователи. Для этого СУБД предоставляет определенный набор инструментов, упрощающих проектирование, администрирование БД и обеспечивающих доступ к данным.
Система управления базами данных (Database Management System, DBMS) — это комплекс программных средств, с помощью которого можно создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ пользователей. Существует множество показателей, по которым можно классифицировать СУБД. Основной классификационный признак — модель реализации данных, существуют сетевая, иерархическая, реляционная модели. Различают персональные и многопользовательские СУБД. Персональные системы предназначены для создания небольших БД устанавливаемых на одном компьютере, поэтому их часто называют настольными. В противовес персональным, многопользовательские системы предназначены для обслуживания БД, находящихся в совместном использовании несколькими пользователями. Есть и другие классификационные признаки, например, по способам разработки приложений БД, по возможностям определения данных, особенностям обработки транзакций, используемой ОС, по экономическим параметрам [7].
Основополагающие функции СУБД:
-
доступность данных; -
управление параллельностью; -
транзакции; -
восстановление данных; -
контроль за доступом к данным.
Доступность данных - это системное описание данных. СУБД должна предоставлять системный каталог, в котором содержится: описание хранимых в базе данных данных, описание связей между данными,
ограничения целостности данных, регистрационные данные пользователей и другая служебная информация. Благодаря метаданным БД становится доступной внешним приложениям, упрощается понимание смысла данных, усиливаются меры безопасности, может выполняться аудит информации.
Управление параллельностью - реализация механизма для многопользовательского доступа к обрабатываемым данным с гарантией корректного обновления этих данных. Умение предоставить нескольким пользователям одновременный доступ к разделяемым ресурсам - едва ли не самая сложная задача, решаемая СУБД. СУБД должна суметь избежать конфликта совместного доступа двух или большего числа пользователей к одним и тем же строкам таблицы, или, по крайней мере, исключить какие-либо нежелательные последствия при возникновении конфликта.
СУБД гарантирует, что БД будет всегда находиться в непротиворечивом состоянии вне зависимости от любых сбоев при проведении операций обновления данных. Для этого операции с данными объединяются в единый блок, называемый транзакцией.
Все операторы транзакции должны быть выполнены корректно и полностью, только тогда в БД будут зафиксированы изменения, которые вводил пользователь. В противном случае система осуществляет автоматический откат транзакции, т. е. состояние БД будет восстановлено на момент времени, предшествующий вызову транзакции в базе данных системы.
Все данные, хранимые в БД, должны быть корректными и непротиворечивыми. Это означает, что данные в таблицах могут модифицироваться только в соответствии с установленными правилами.
В самом общем случае можно говорить о существовании трех правил поддержания целостности данных: целостность доменов, целостность отношений, целостность связей между отношениями. Кроме того, разработчик имеет возможность описывать свои собственные бизнес-правила, которые мы будем называть корпоративными ограничениями [8].
В случае непредвиденных ошибок и сбоев, приведших к повреждению или разрушению данных, СУБД должна обладать возможностью восстанавливать пострадавшие данные. В первую очередь эта функция реализуется с помощью процедур резервного копирования.
СУБД обязана поддерживать современные сетевые технологии и предоставлять доступ к БД удаленным персональным компьютерам.
Доступ к данным могут осуществлять только зарегистрированные в СУБД пользователи в соответствии с назначенными администратором СУБД им правами. Список обязанностей СУБД на этом далеко не заканчивается. Современные системы предоставляют нам средства мониторинга, сервисы статистического анализа, утилиты экспорта/импорта данных, развитые средства