ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.11.2023
Просмотров: 86
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Трёхуровневое хранилище данных
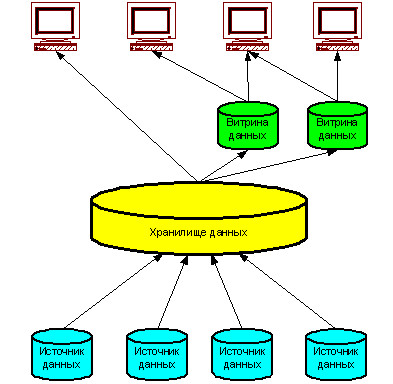
Хранилище данных представляет собой единый централизованный источник корпоративной информации. Витрины данных представляют подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса.
Преимущества:
-
Создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных -
Витрины данных синхронизированы и совместимы с корпоративным представлением. Имеется корпоративная модель данных. Существует возможность сравнительно лёгкого расширения хранилища и добавления новых витрин данных
Недостатки:
-
Существует избыточность данных, ведущая к росту требований на хранение данных -
Требуется согласованность с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу)
10. Информация хранится в базах данных, базах знаний и должна быть соответствующим образом структурирована.
База данныхможет быть определена как совокупность различных типов записей и отношений между элементами, записями и сегментами данных. Банк данных содержит информацию о характеристиках и признаках ситуаций, в том числе признаках появления, возможных причинах возникновения, важности, директивном времени и т.д. Каждый представленный в базе данных объект должен имел определенную совокупность описывающих его атрибутов. Кроме того, требуется, чтобы существовали правила, позволяющие сопоставить эти атрибуты. Структурирование данных связано с использованием одной из трех моделей данных: реляционной, иерархической и сетевой.
База знаний создается на этапе обучения создаваемая на основе обработки экспертной информации. Подсистема знаний представляет собой организованную совокупность знаний системы в проблемной области. Эти знания содержат большие объёмы фактов и отношений между ними.
Цель подсистемы знаний - получение выводов, представляющих собой эффективные рекомендации по принятию решения. Насколько качественно
-
будут структурированы исходные данные и профессиональные знания; -
сформированы новые знания, положенные в основу баз знаний; -
подобрана математическая модель представления данных и знаний
зависит оперативность и качество принимаемых решений СППР.
В рамках СППР можно выделить 3 типа знаний:
- структурированные статические знания о предметной области (декларативные (экстенсиональные) знания) после того, как эти знания выявлены они уже не изменяются. Эти знания представляют собой свойства, события, эмпирические факты, хорошо известные в исследуемой предметной области.
- структурированные динамические знания – изменяемые знания о предметной области, которые обновляются по мере выявления новой информации. Обычно эти знаний основываются на собственном опыте эксперта, накопленном в результате многолетней практики, в силу этого они являются эвристическими, экспериментальными, неопределенными и оперируют абстрактными объектами, событиями и отношениями. Но, тем не менее, специалисты отмечают, что именно эта категория знаний играет решающую роль в повышении эффективности систем принятия решений.
- текущие знания – используются для решения конкретных задач и проведения консультаций
При разработке СППР неизбежно возникает о выборе модели представления данных и знаний.
Представление знаний – это формализация и структурирование (в целях облегчения решения задачи) знаний, с помощью которых отражаются основные характерные признаки: внутренняя интерпретируемость, структурированность,связность», семантическая метрика и др.
Модель представления знаний определяется выбранными средствами, с помощью которых можно адекватно описать предметную область. В настоящее время наиболее проработанными и традиционно используемыми моделями представления данных являются иерархическая, сетевая и реляционная модели, а для представления знаний – семантические сети, фреймы, логические модели и системы продукций.
Иерархическая модель данных – это модель представления элементов данных и связей между элементами данных в виде древовидных структур.
Сетевая модель данных реализуется на основе ориентированных графов, где вершинам графа соответствуют специальным образом организованные данные, а дугам – типы связей между этими данными.
Реляционная модель данных базируется на теоретико-множественном понятии отношения, то есть множества кортежей фиксированной длины. Где каждый кортеж задает описание объекта в виде множества значений признаков, а связи между элементами данных задаются путем включения одинаковых признаков в разные отношения. На логическом уровне реляционная модель представляется набором связанных между собой таблиц с данными.
В представлении знаний семантическая сеть – это ориентированный граф, вершины которого – понятия (абстрактные или конкретные объекты), а дуги – отношения между ними.
Помимо произвольных отношений, специфических для предметной области, семантические сети включают следующие характерные типы отношений: класс - подкласс (человек - студент); часть - целое (книга - обложка); класс - экземпляр (пример) класса (человек - Иван Петров); свойство - значение: название (цвет - красный).
Проблема поиска решения сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, представляющей ответ на поставленный вопрос. Основным преимуществом этой модели является то, что она достаточно хорошо согласуется ссовременным представлениям об организации долговременной памяти человека. Недостатком этой модели является сложность организации процедуры поиска вывода на семантической сети.
Фрейм - это представление знаний в виде объектов и отношений между объектами. Основными понятиями являются понятия структуры, объекта, слота, атрибута, значения.
Структурно состоят из имени фрейма и слотов, прнимающих конкретные значения атрибутов фрейма.
Имя фрейма:
Имя слота 1 (значение слота 1)
Имя слота 2 (значение слота 2)
... ... ... ... ... ... ...
Имя слота К (значение слота К).
При конкретизации фрейма ему и слотаему и слотам присваиваются конкретные имена и происходит заполнение слотов. Например, у фрейма с именем «комната» могут быть слоты с именами «высота», «ширина», «число окон» и т.д.
Существуют следующие разновидности фреймов, позволяющие отобразить достаточно многообразные знания о мире:
• фреймы-структуры, использующиеся для обозначения объектов и понятий (банк, комната, стол);
• фреймы-роли (администратор, машинист, студент);
• фреймы-сценарии (сдача экзамена, образование юридического лица, верстка газе-ты);
• фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных фактических ситуаций на основе поступающих данных.
Фреймы могут объединяться в сети наподобие семантических. Предметная область описывается некоторой иерархической структурой. Из теории семантических сетей фреймы также заимствовали наследование свойств: фреймы, занимающие более низкое положений, наследуют свойства фреймов более высокого уровня.
Логические модели Основная идея при построении логических моделей знаний заключается в том, что вся информация, необходимая для решения прикладных задач, рассматривается как совокупность фактов и утверждений, которые представляются как формулы в некоторой логике. Знания отображаются совокупностью таких формул, а получение новых знаний сводится к реализации процедур логического вывода.
Продукционная модель представления знаний оперирует с правилами импликативного вида «Если А, то В», называемыми продукциями и задающими элементарные шаги преобразований и умозаключений, где левая часть правил является посылкой (причиной), а правая – заключением (следствием).вместо логического вывода применяется вывод на знаниях. Достоинствами этой модели являются наглядность, высокая модульность, легкость внесения дополнений и изменений и простота механизма логического вывода.
11. Принятие решения базируется на анализе оперативных текущих данных с учетом информации, находящейся в хранилищах и выявлении зависимостей между данными. Можно выделить два основных подхода:
1) пользователь сам производит анализ и выдвигает гипотезы относительно зависимостей между данными. Такой подход реализован, например, в рамках такого развитого средства как OLAP, (см. п.11), поскольку в нем процесс поиска по-прежнему полностью контролируется человеком. Во многих системах при этом автоматизирована проверка достоверности гипотез, что позволяет оценить вероятность тех или иных зависимостей в базе данных. Типичным примером может служить, такой вывод: вероятность того, что рост продаж продукта А обусловлен ростом продаж продукта В, составляет 0,75;
2) поиск закономерностей возлагается на компьютер
. Для реализации такого подхода используются методы автоматического интеллектуального анализа данных. Этот подход, хотя и интенсивно развивающийся, находится еще на этапе становления
В настоящее время сложилась следующая ситуация:
- объемы подлежащих анализу данных для принятия эффективных решений обычно очень велики. Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности предприятия, корпорации, ведомственные структуры, органы государственной власти накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения;
- человеческий разум сам по себе не приспособлен для восприятия больших массивов разнородной информации. Человек к тому же не способен улавливать более двух-трех взаимосвязей даже в небольших выборках;
- созданы необходимые технические предпосылки для автоматизации подобного анализа - современные компьютеры по своим техническим характеристикам способны, в отличие от своих относительно недавних предшественников, решать очень трудоемкие (в частности, переборные) задачи
В такой ситуации большой интерес представляет автоматизация интеллектуального анализа данных, позволяющего провести наиболее полный и глубокий анализ проблемы, дающего возможность обнаружить скрытые взаимосвязи, принять наиболее обоснованное решение.
12. Комплексный взгляд на собранную информацию, ее обобщение и агрегация, многомерный анализ являются задачами систем оперативной аналитической обработки данных — OLAP (On-LineAnalyticalProcessing). Основное назначение OLAP-технологий – подготовка информацию для принятия решения на основе динамического многомерного анализа данных, моделирования и прогнозирования. Часто при этом используются различные статистические группировки данных
В основе концепции оперативной аналитической обработки OLAP лежит многомерное представление данных, позволяющее объединять, просматривать и анализировать данные с точки зрения множественности измерений, наблюдать данные в различных измерениях, направлениях или сечениях, что отражаетестественный взгляд аналитиков на объект управления.