ВУЗ: Казахская Национальная Академия Искусств им. Т. Жургенова
Категория: Книга
Дисциплина: Не указана
Добавлен: 03.02.2019
Просмотров: 21705
Скачиваний: 19

7-16 Compression Technologies for Audio
Auxiliary data up to 9.6 kbits/s can also be imbedded into the data stream without incurring a
bit overhead penalty. When this function is enabled, an audio bit in one of the higher frequency
subbands is replaced by an auxiliary data bit, again with no audible effect.
An important feature of this algorithm is its inherent robustness to random bit errors. No
audible distortion is apparent for normal program material at a bit error rate (BER) of 1:10,000,
while speech is still intelligible down to a BER of 1:10.
Distortions introduced by bit errors are constrained within each subband and their impact on
the decoder subband predictors and quantizers is proportional to the magnitude of the differential
signal being decoded at that instant. Thus, if the signal is small—which will be the case for a low
level input signal or for a resonant, highly predictable input signal—any bit error will have mini-
mal effect on either the predictor or quantizer.
The 16 bit linear PCM signal is processed in time blocks of four samples at a time. These are
filtered into four equal-width frequency subbands; for 20 kHz, this would be 0–5 kHz, 5–10
kHz, and so on. The four outputs from the quadrature mirror filter (QMF) tree are still in the 16
bit linear PCM format, but are now frequency-limited.
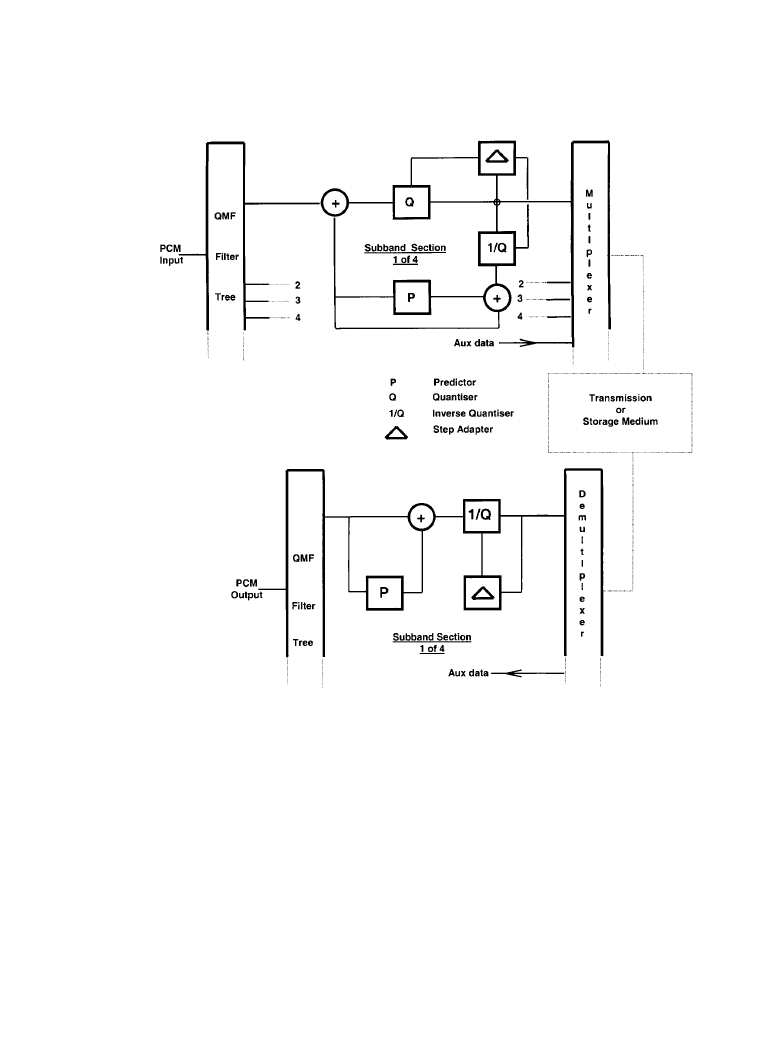
As shown in Figure 7.1.4, the compression process can be mapped by taking, for example, the
first and lowest frequency subband. The first step is to create the difference signal. After the sys-
tem has settled down on initiation, there will be a reconstructed 16 bit difference signal at the
output of the inverse quantizer. This passes into a prediction loop that, having analyzed 122 pre-
vious samples, will make a prediction for the level of the next full level sample arriving from the
filter tree. This prediction is then compared with the actual level.
The output of the comparator is the resulting 16-bit difference signal. This is requantized to a
new 7-bit format, which in turn is inverse quantized back to 16 bits again to enable the prediction
loop.
The output from the inverse quantizer is also analyzed for energy content, again for the same
122 previous samples. This information is compared with on-board look up tables and a decision
is made to dynamically adjust, up or down as required, the level of each step of the 1024 intervals
in the 7-bit quantizer. This ensures that the quantizer will always have adequate range to deal
with the varying energy levels of the audio signal. Therefore, the input to the multiplexer will be
a 7 bit word but the range of those bits will be varying in relation to the signal energy.
The three other subbands will go through the same process, but the number of bits allocated
to the quantizers are much less than for the first subband.
The output of the multiplexer or bit stream formatter is a new 16-bit word that represents four
input PCM samples and is, therefore, one quarter of the input rate; a reduction of 4:1.
The decoding process is the complete opposite of the coding procedure. The incoming 16-bit
compressed data word is demultiplexed and used to control the operation of four subband
decoder sections, each with similar predictor and quantizer step adjusters. A QMF filter tree
finally reconstructs a linear PCM signal and separates any auxiliary data that may be present.
7.1.2b
ISO/MPEG-1 Layer 2
This algorithm differs from Layer 1 by adopting more accurate quantizing procedures and by
additionally removing redundancy and irrelevancy on the generated scale factors [1]. The ISO/
MPEG-1 Layer 2 scheme operates on a block of 1152 PCM samples, which at 48 kHz sampling
represents a 24 ms time block of the input audio signal. Simplified block diagrams of the encod-
ing/decoding systems are given in Figure 7.1.5.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems
Audio Compression Systems 7-17
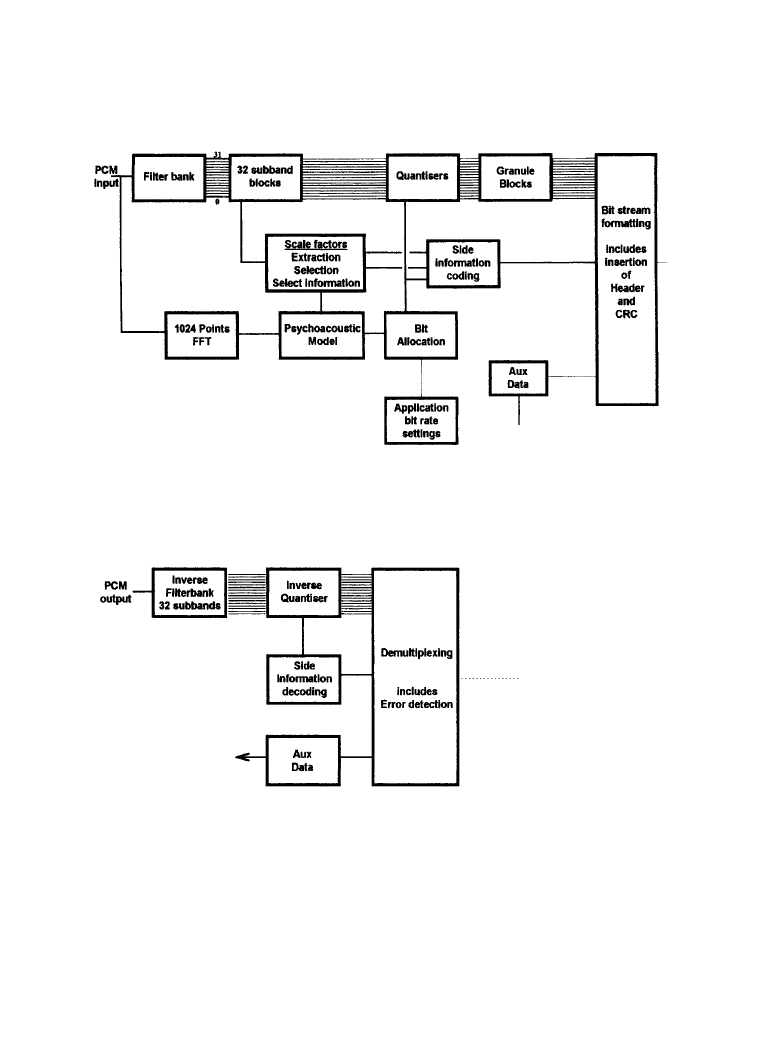
The incoming linear PCM signal block is divided into 32 equally spaced subbands using a
polyphase analysis filter bank (Figure 7.1.5a). At 48 kHz sampling, this equates to the band-
width of each subband being 750 Hz. The bit allocation for the requantizing of these subband
samples is then dynamically controlled by information derived from analyzing the audio signal,
measured against a preset psychoacoustic model.
The filter bank, which displays manageable delay and minimal complexity, optimally adapts
each block of audio to achieve a balance between the effects of temporal masking and inaudible
pre-echoes.
(
a)
(
b)
Figure 7.1.4
apt-X100 audio coding system: (
a) encoder block diagram, (b) decoder block dia-
gram. (
Courtesy of Audio Processing Technology.)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems

7-18 Compression Technologies for Audio
The PCM signal is also fed to a fast Fourier transform (FFT) running in parallel with the filter
bank. The aural sensitivities of the human auditory system are exploited by using this FFT pro-
cess to detect the differences between the wanted and unwanted sounds and the quantization
noise already present in the signal, and then to adjust the signal-to-mask thresholds, conforming
to a preset perceptual model.
This psychoacoustic model is only found in the coder, thus making the decoder less complex
and permitting the freedom to exploit future improvements in coder design. The actual number
of levels for each quantizer is determined by the bit allocation. This is arrived at by setting the
signal-to-mask ratio (SMR) parameter, defined as the difference between the minimum masking
threshold and the maximum signal level. This minimum masking threshold is calculated using
the psychoacoustic model and provides a reference noise level of “just noticeable” noise for each
subband.
In the decoder, after demultiplexing and decyphering of the audio and side information data, a
dual synthesis filter bank reconstructs the linear PCM signal in blocks of 32 output samples (Fig-
ure 7.1.5b).
A scale factor is determined for each 12 subband sample block. The maximum of the absolute
values of these 12 samples generates a scale factor word consisting of 6 bits, a range of 63 differ-
ent levels. Because each frame of audio data in Layer 2 corresponds to 36 subband samples, this
process will generate 3 scale factors per frame. However, the transmitted data rate for these scale
factors can be reduced by exploiting some redundancy in the data. Three successive subband
scale factors are analyzed and a pattern is determined. This pattern, which is obviously related to
the nature of the audio signal, will decide whether one, two or all three scale factors are required.
The decision will be communicated by the insertion of an additional scale factor select informa-
tion data word of 2 bits (SCFSI).
In the case of a fairly stationary tonal-type sound, there will be very little change in the scale
factors and only the largest one of the three is transmitted; the corresponding data rate will be (6
+ 2) or 8 bits. However, in a complex sound with rapid changes in content, the transmission of
two or even three scale factors may be required, producing a maximum bit rate demand of (6 + 6
+ 6 + 2) or 20 bits. Compared with Layer 1, this method of coding the scale factors reduces the
allocation of data bits required for them by half.
The number of data bits allocated to the overall bit pool is limited or fixed by the data rate
parameters. These parameters are set out by a combination of sampling frequency, compression
ratio, and—where applicable—the transmission medium. In the case of 20 kHz stereo being
transmitted over ISDN, for example, the maximum data rate is 384 kbits/s, sampling at 48kHz,
with a compression ratio of 4:1.
After the number of side information bits required for scale factors, bit allocation codes,
CRC, and other functions have been determined, the remaining bits left in the pool are used in
the re-coding of the audio subband samples. The allocation of bits for the audio is determined by
calculating the SMR, via the FFT, for each of the 12 subband sample blocks. The bit allocation
algorithm then selects one of 15 available quantizers with a range such that the overall bit rate
limitations are met and the quantization noise is masked as far as possible. If the composition of
the audio signal is such that there are not enough bits in the pool to adequately code the subband
samples, then the quantizers are adjusted down to a best-fit solution with (hopefully) minimum
damage to the decoded audio at the output.
If the signal block being processed lies in the lower one third of the 32 frequency subbands, a
4-bit code word is simultaneously generated to identify the selected quantixer; this word is,
again, carried as side information in the main data frame. A 3-bit word would be generated for
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems
Audio Compression Systems 7-19
processing in the mid frequency subbands and a 2-bit word for the higher frequency subbands.
When the audio analysis demands it, this allows for at least 15, 7, and 3 quantization levels,
respectively, in each of the three spectrum groupings. However, each quantizer can, if required,
(
a)
(
b)
Figure 7.1.5
ISO/MPEG-1 Layer 2 system: (
a) encoder block diagram, (b) decoder block diagram.
(
After [1].)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems

7-20 Compression Technologies for Audio
cover from 3 to 65,535 levels and additionally, if no signal is detected then no quantization takes
place.
As with the scale factor data, some further redundancy can be exploited, which increases the
efficiency of the quantising process. For the lowest quantizer ranges (i.e., 3, 5, and 9 levels),
three successive subband sample blocks are grouped into a “granule” and this—in turn—is
defined by only one code word. This is particularly effective in the higher frequency subbands
where the quantizer ranges are invariably set at the lower end of the scale.
Error detection information can be relayed to the decoder by inserting a 16 bit CRC word in
each data frame. This parity check word allows for the detection of up to three single bit errors or
a group of errors up to 16 bits in length. A codec incorporating an error concealment regime can
either mute the signal in the presence of errors or replace the impaired data with a previous, error
free, data frame. The typical data frame structure for ISO/MPEG-1 Layer 2 audio is given in Fig-
ure 7.1.6.
7.1.2c
MPEG-2 AAC
Also of note is MPEG-2 advanced audio coding (AAC), a highly advanced perceptual code, used
initially for digital radio applications. The AAC code improves on previous techniques to
increase coding efficiency. For example, an AAC system operating at 96 kbits/s produces the
same sound quality as ISO/MPEG-1 Layer 2 operating at 192 kbits/s—a 2:1 reduction in bit rate.
There are three modes (Profiles) in the AAC standard:
•
Main—used when processing power, and especially memory, are readily available.
•
Low complexity (LC)—used when processing cycles and memory use are constrained.
•
Scaleable sampling rate (SSR)—appropriate when a scalable decoder is required. A scalable
decoder can be designed to support different levels of audio quality from a common bit
stream; for example, having both high- and low-cost implementations to support higher and
lower audio qualities, respectively.
Figure 7.1.6
ISO/MPEG-1 Layer 2 data frame structure. (
After [1].)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems