ВУЗ: Казахская Национальная Академия Искусств им. Т. Жургенова
Категория: Книга
Дисциплина: Не указана
Добавлен: 03.02.2019
Просмотров: 21707
Скачиваний: 19
Audio Compression Systems 7-21
Different Profiles trade off encoding complexity for audio quality at a given bit rate. For exam-
ple, at 128 kbits/s, the Main Profile AAC code has a more complex encoder structure than the
LC AAC code at the same bit rate, but provides better audio quality as a result.
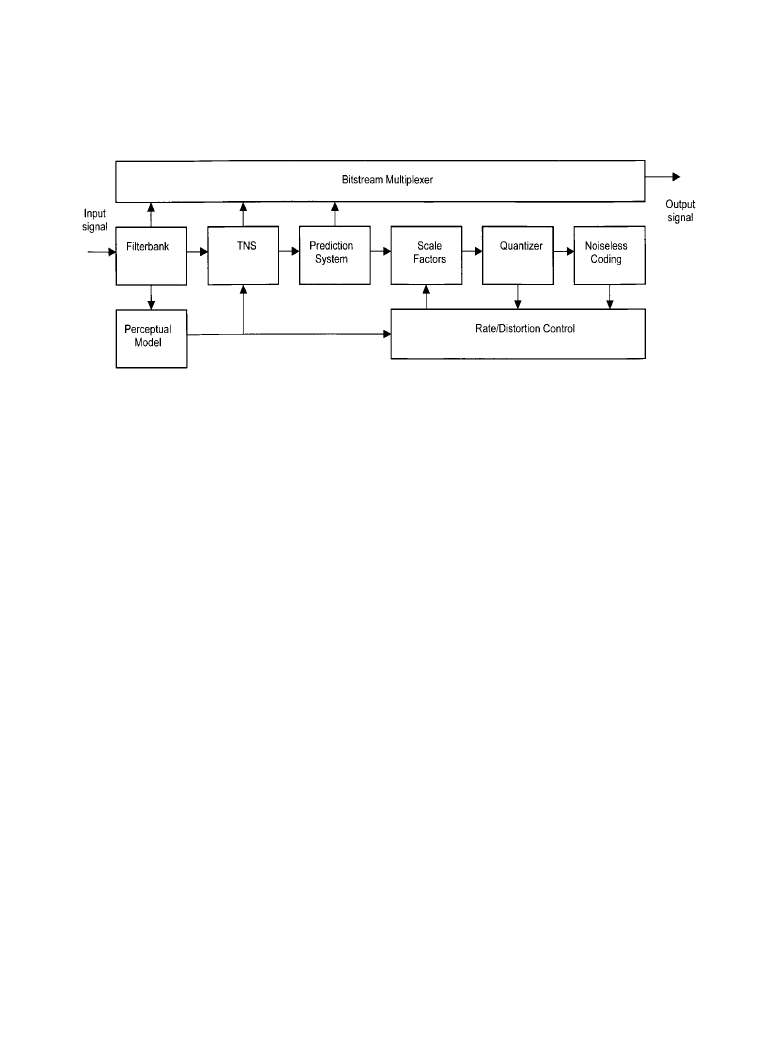
A block diagram of the AAC system general structure is given in Figure 7.1.7. The blocks in
the drawing are referred to as “tools” that the coding alogrithm uses to compress the digital audio
signal. While many of these tools exist in most audio perceptual codes, two are unique to AAC—
the temporal noise shaper (TNS) and the filterbank tool. The TNS uses a backward adaptive pre-
diction process to remove redundancy between the frequency channels that are created by the fil-
terbank tool.
MPEG-2 AAC provides the capability of up to 48 main audio channels, 16 low frequency
effects channels, 16 overdub/multilingual channels, and 10 data streams. By comparison, ISO/
MPEG-1 Layer 1 provides two channels and Layer 2 provides 5.1 channels (maximum). AAC is
not backward compatible with the Layer 1 and Layer 2 codes.
7.1.2d
MPEG-4
MPEG-4, as with the MPEG-1 and MPEG-2 efforts, is not concerned solely with the develop-
ment of audio coding standards, but also encompasses video coding and data transmission ele-
ments. In addition to building upon the audio coding standards developed for MPEG-2, MPEG-4
includes a revolutionary new element—synthesized sound. Tools are provided within MPEG-4
for coding of both natural sounds (speech and music) and for synthesizing sounds based on
structured descriptions. The representations used for synthesizing sounds can be formed by text
or by instrument descriptions, and by coding other parameters to provide for effects, such as
reverberation and spatialization.
Natural audio coding is supported within MPEG-4 at bit rates ranging from 2–64 kbits/s, and
includes the MPEG-2 AAC standard (among others) to provide for general compression of audio
Figure 7.1.7
Functional block diagram of the MPEG-2 AAC coding system.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems

7-22 Compression Technologies for Audio
in the upper bit rate range (8–64 kbits/s), the range of most interest to broadcasters. Other types
of coders, primarily voice coders (or vocoders) are used to support coding down to the 2 kbits/s
rate.
For synthesized sounds, decoders are available that operate based on so-called structured
inputs, that is, input signals based on descriptions of sounds and not the sounds themselves. Text
files are one example of a structured input. In MPEG-4, text can be converted to speech in a text-
to-speech (TTS) decoder. Synthetic music is another example, and may be delivered at extremely
low bit rates while still describing an exact sound signal. The standard’s structured audio
decoder uses a language to define an orchestra made up of instruments, which can be down-
loaded in the bit stream, not fixed in the decoder.
TTS support is provided in MPEG-4 for unembellished text, or text with prosodic (pitch con-
tour, phoneme duration, etc.) parameters, as an input to generate intelligible synthetic speech. It
includes the following functionalities:
•
Speech synthesis using the prosody of the original speech
•
Facial animation control with phoneme information (important for multimedia applications)
•
Trick mode functionality: pause, resume, jump forward, jump backward
•
International language support for text
•
International symbol support for phonemes
•
Support for specifying the age, gender, language, and dialect of the speaker
MPEG-4 does not standardize a method of synthesis, but rather specifies a method of describing
synthesis.
Compared to previous MPEG coding standards, the goals of MPEG-4 go far beyond just
achieving higher coding efficiency [3]. Specifically, MPEG-4 is conceived as a set of interopera-
ble technologies implementing the following concepts:
•
Universality: Rather than serving specific application areas, MPEG-4 is an attempt to pro-
vide solutions for almost any conceivable scenario using audiovisual compression, ranging
from very low bit rates to studio-quality applications. Because there is currently no single
coding technology serving all these cases equally well, MPEG-4 Audio provides both a so-
called General Audio coder and a number of coders specifically targeting certain types of sig-
nals (e.g., speech or music) or bit rates.
•
Scalability: The MPEG-4 concept of scalable coding enables the transmission and decoding
of a scalable bitstream with a bit rate that can be adapted to dynamically varying require-
ments, such as the instantaneous transmission channel capacity. This capability offers signifi-
cant advantages for transmitting content over channels with a variable channel capacity (e.g.,
the Internet and wireless links) or connections for which the available channel capacity is
unknown at the time of encoding.
•
Object-based representation and composition: As suggested by the standard’s name
(“Generic Coding of Audiovisual Objects”), MPEG-4 represents audiovisual content as a set
of objects rather than a flat representation of the entire audiovisual scene. The relation of the
coded objects with each other and the way to construct the scene from these objects (“compo-
sition”) is described by a scene description.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems

Audio Compression Systems 7-23
•
Content-based interactivity: The combination of object-based representation and scene
description/composition allows exciting new capabilities. For example, during a presentation,
the user can interact with coded objects and control the way they are rendered by the compo-
sition unit. Examples of this so-called content-based interactivity include omitting reproduc-
tion for certain objects or controlling their scene composition parameters, such as spatial
coordinates and reproduction level.
•
Natural and synthetic representations: Synthetic content, such as computer graphics or
synthesized audio, has gained increasing importance and is widely deployed, fuelled by the
success of the personal computer. Converging both worlds, MPEG-4 defines representations
for both natural and synthetic objects and allows arbitrary combinations of these object types
within a scene.
7.1.2e
Dolby E Coding System
Dolby E coding was developed to expand the capacity of existing two channel AES/EBU digital
audio infrastructures to make them capable of carrying up to eight channels of audio plus the
metadata required by the Dolby Digital coders used in the ATSC DTV transmission system [4].
This allows existing digital videotape recorders, routing switchers, and other video plant equip-
ment, as well as satellite and telco facilities, to be used in program contribution and distribution
systems that handle multichannel audio. The coding system was designed to provide broadcast
quality output even when decoded and re-encoded many times, and to provide clean transitions
when switching between programs.
Dolby E encodes up to eight audio channels plus the necessary metadata and inserts this
information into the payload space of a single AES digital audio pair. Because the AES protocol
is used as the transport mechanism for the Dolby E encoded signal, digital VTRs, routing switch-
ers, DAs, and all other existing digital audio equipment in a typical video facility can handle
multichannel programming. It is possible to do insert or assemble edits on tape or to make audio-
follow-video cuts between programs because the Dolby E data is synchronized with the accom-
panying video. The metadata is multiplexed into the compressed audio, so it is switched with and
stays in sync with the audio.
The main challenge in designing a bit-rate reduction system for multiple generations is to pre-
vent coding artifacts from appearing in the recovered audio after several generations. The coding
artifacts are caused by a buildup of noise during successive encoding and decoding cycles, so the
key to good multigeneration performance is to manage the noise optimally.
This noise is caused by the rate reduction process itself. Digitizing (quantizing) a signal leads
to an error that appears in the recovered signal as a broadband noise. The smaller the quantizer
steps (i.e., the more resolution or bits used to quantize the signal), the lower the noise will be.
This quantizing noise is related to the signal, but becomes “whiter” as the quantizer resolution
rises. With resolutions less than about 5 or 6 bits and no dither, the quantizing noise is clearly
related to the program material.
Bit rate reduction systems try to squeeze the data rates down to the equivalent of a few bits (or
less) per sample and, thus, tend to create quantizing noise in quite prodigious quantities. The key
to recovering signals that are subjectively indistinguishable from the original signals, or in which
the quantizing noise is inaudible, is in allocating the available bits to the program signal compo-
nents in a way that takes advantage of the ear's natural ability to mask low level signals with
higher level ones.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems

7-24 Compression Technologies for Audio
The rate reduction encoder sends information about the frequency spectrum of the program
signal to the decoder. A set of reconstruction filters in the decoder confines the quantizing noise
produced by the bit allocation process in the encoder to the bandwidth of those filters. This
allows the system designer to keep the noise (ideally) below the masking thresholds produced by
the program signal. The whole process of allocating different numbers of bits to different pro-
gram signal components (or of quantizing them at different resolutions) creates a noise floor that
is related to the program signal and to the rate reduction algorithm used. The key to doing this is
to have an accurate model of the masking characteristics of the ear, and in allocating the available
bits to each signal component so that the masking threshold is not exceeded.
When a program is decoded and then re-encoded, the re-encoding process (and any subse-
quent ones) adds its noise to the noise already present. Eventually, the noise present in some part
of the spectrum will build up to the point where it becomes audible, or exceeds the allowable
coding margin. A codec designed for minimum data rate has to use lower coding margins (or
more aggressive bit allocation strategies) than one intended to produce high quality signals after
many generations
The design strategy for a multigeneration rate reduction system, such as one used for Dolby
E, is therefore quite different than that of a minimum data rate codec intended for program trans-
mission applications.
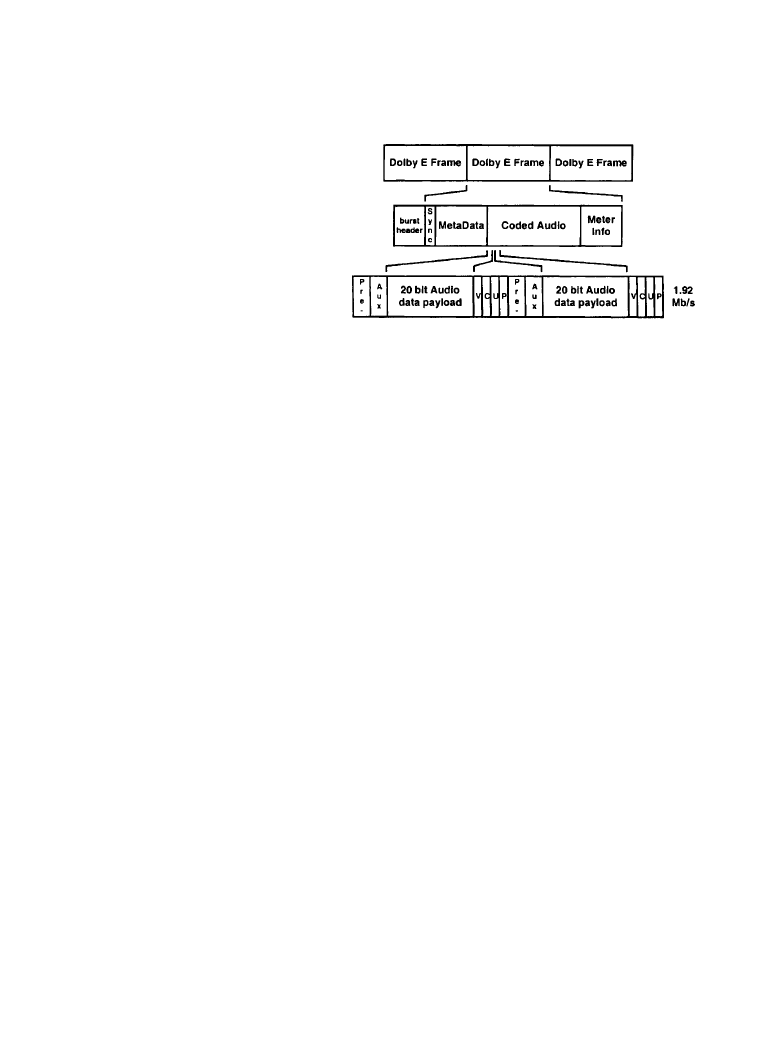
Dolby E signals are carried in the AES3 interface using a packetized structure [5]. The pack-
ets are based on the coded Dolby E frame, which is illustrated in Figure 7.1.8. Each Dolby E
frame consists of a synchronization field, metadata field, coded audio field, and a meter field.
The metadata field contains a complete set of parameters so that each Dolby E frame can be
decoded independently. The Dolby E frames are embedded into the AES3 interface by mapping
the Dolby E data into the audio sample word bits of the AES3 frames utilizing both channels
within the signal. (See Figure 7.1.9.) The data can be packed to utilize 16, 20, or 24 bits in each
AES3 sub-frame. The advantage of utilizing more bits per sub-frame is that a higher data rate is
available for carrying the coded information. With a 48 kHz AES3 signal, the 16 bit mode allows
a data rate of up to 1.536 Mbits/s for the Dolby E signal, while the 20 bit mode allows 1.92
Mbits/s. Higher data rate allows more generations and/or more channels of audio to be sup-
ported. However, some AES3 data paths may be restricted in data rate (e.g., some storage devices
will only record 16 or 20 bits). Dolby E therefore allows the user to choose the optimal data rate
for a given application.
Figure 7.1.8
Basic frame struc-
ture of the Dolby E coding sys-
tem. (
After [4].)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems
Audio Compression Systems 7-25
Architectural Overview
The basic architecture of the Dolby E encoder/decoder is shown in Figure 7.1.10 [6]. In the
encoder, the incoming multichannel PCM audio is first passed through a set of sample rate con-
verters (SRC), which convert the audio sample rate to a simple multiple of the video frame rate.
The sample rate converter clock is derived from the video reference signal via a phase-locked
loop (PLL).
The output of the sample rate converter is then fed to the encoder core, which includes the
audio data compression engine. In addition, incoming metadata parameters are also passed to the
encoder core. The output of this core is a series of coded data frames, each containing a combi-
nation of compressed multichannel audio and metadata, delivered at a rate that is synchronous
with the video signal.
The decoder architecture is a straightforward reversal of the encoder. The coded bitstream is
passed into the decoder core, which reconstructs the multichannel audio samples and the meta-
data. Because the reconstructed audio sample rate is a function of the video frame rate, a second
set of sample rate converters is used to convert the output audio to a standard 48 kHz rate.
The sample rate converters used in this design are a consequence of the need to support a
wide variety of video frame rates. Table 7.1.2 lists several of the most common video frame rates
used in current broadcast practice, as well as the number of 48 kHz PCM samples per frame
associated with each rate. Not only does the number of samples vary depending on the frame
rate, but for one case the number is not even an integer.
In order to simplify the design of the audio compression engine, sample rate converters were
introduced to ensure that the number of samples per frame was a constant. For this system, each
frame duration is the equivalent of 1792 audio samples. As a result, the sample rate seen at the
input of the encoder core is no longer 48 kHz, but rather varies with the video frame rate.
Table 7.1.3 lists the internal sample rates used by this system during audio data compression
encoding and decoding, as a function of the associated video frame rate.
Coded Frame Format
In order to meet certain compatibility requirements, the coded output frame is structured to look
in many ways like stereo PCM [6]. Specifically, the output bitstream sample rate is set to 48 kHz,
and the coded data is aligned in 20-bit words. This format is shown in Figure 7.1.11. Note that
system options also allow for 16-bit or 24-bit output formats, however 20-bit is the most com-
mon standard.
Figure 7.1.9
Overall coding
scheme of Dolby E. (
After [5].)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Audio Compression Systems