ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 04.12.2023
Просмотров: 201
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
1. Классификация возможных архитектур информационных систем
7. Функциональная логика приложений
8. Различная физическая реализация логической модели
3. HTTP-аутификация средствами PHP.
4. Создание GIF-файлов с помощью PHP.
5. Поддержка file upload. Поддержка HTTP cookie. Поддержка баз данных.
Замечание: речь идет о так называемых OLAP-системах (от On-Line Analitical Processing), т.е. аналитических системах, помогающих принимать бизнес-решения за счет динамически производимых анализа, моделирования и/или прогнозирования данных.
С учетом приведенных замечаний общая архитектура склада данных и системы аналитической обработки данных может выглядеть (Рисунок 11).
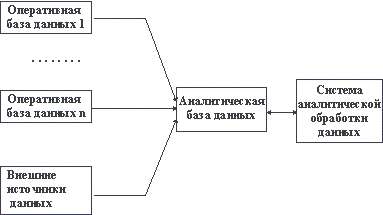
Рисунок 11 – Схематическое представление архитектуры аналитической информационной системы
В 1993 г. основоположник реляционного подхода к организации баз данных Эдвар Кодд, исходя из потребностей систем динамической аналитической обработки данных, сформулировал 12 основных требований к системам, поддерживающим аналитические базы данных. Мы приведем изложение этих требований, чтобы представить точку зрения проектировщика и разработчика системы аналитической обработки данных.
Основным выводом из материала этого раздела является то, что подход складов данных еще слишком молод, чтобы вокруг него сложился круг общепринятых понятий, терминов, технологических приемов. Тем не менее, он кажется настолько важным и перспективным, что многие компании (в том числе и ведущие производители СУБД) ведут активную работу, чтобы быть в авангарде этого направления. Существующие идеи и реализации мы рассмотрим в пятой части курса.
5. Логическая трехзвенная модель Web-приложений
Современный подход разработки web-приложений, работающих с базами данных, основан на так называемой трехзвенной модели. В соответствии с этой моделью приложение логически разделяется на три функциональных уровня (Рисунок 12).
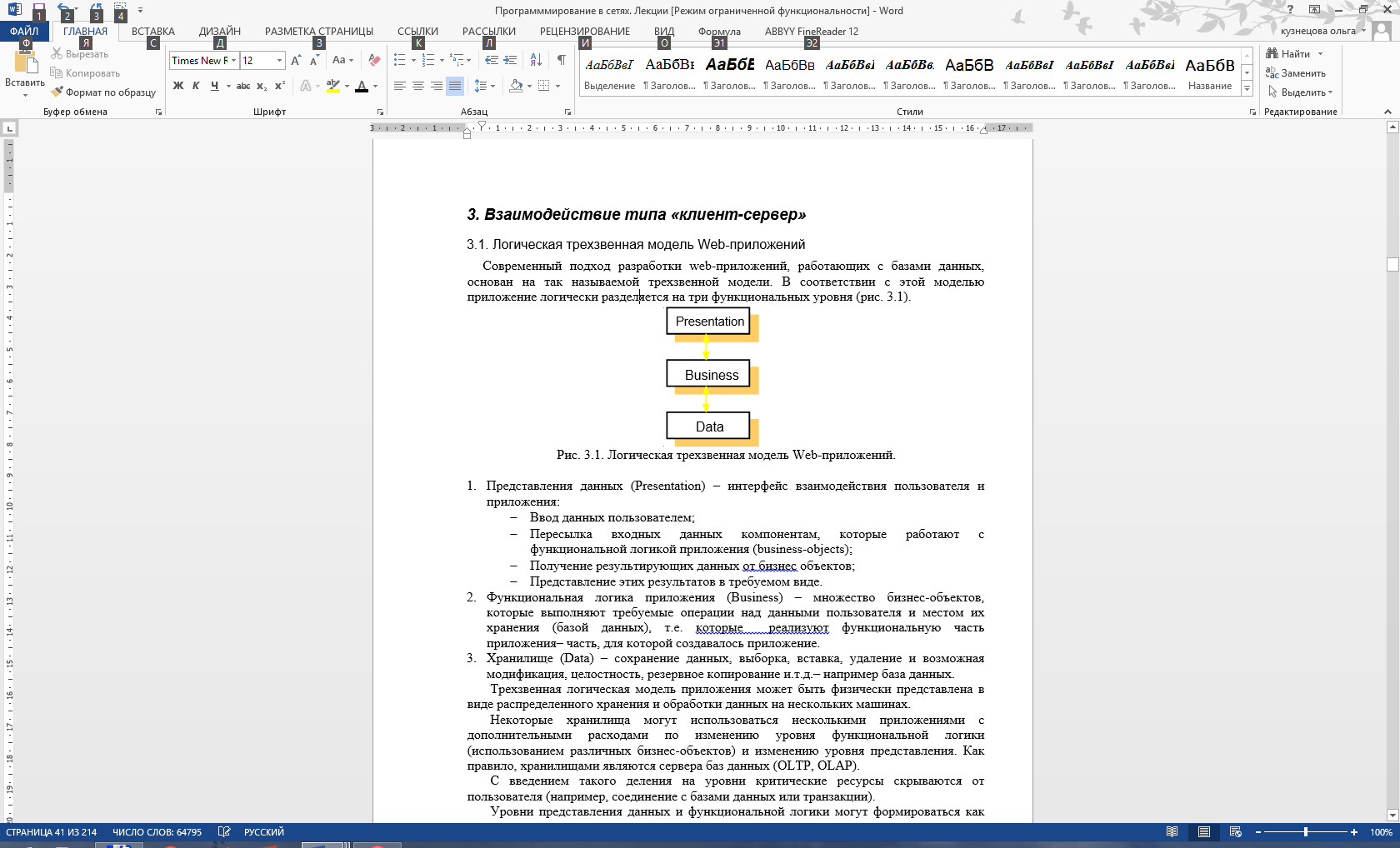
Рисунок 12
– Логическая трехзвенная модель Web-приложений.
Трехзвенная логическая модель приложения может быть физически представлена в виде распределенного хранения и обработки данных на нескольких машинах.
Некоторые хранилища могут использоваться несколькими приложениями с дополнительными расходами по изменению уровня функциональной логики (использованием различных бизнес-объектов) и изменению уровня представления. Как правило, хранилищами являются сервера баз данных (OLTP, OLAP).
С введением такого деления на уровни критические ресурсы скрываются от пользователя (например, соединение с базами данных или транзакции).
Уровни представления данных и функциональной логики могут формироваться как на стороне сервера, так и на стороне клиента, и зависят от того, где возможно использование различных технологий и инструментария.
Несмотря на, то, что сеть обеспечивает перемещение данных из одной точки в другую, сама она остаётся пассивной. Это значит, что сеть не вырабатывает и не анализирует передаваемые данные; она даже не содержит каких-либо средств обработки информации. Все операции обработки данных выполняются прикладными программами!
При использовании сети приложения действуют парами, и каждая пара приложений использует сеть просто для обмена сообщениями. Например, рассмотрим службу управления распределенной базой данных, которая позволяет удаленным пользователям обращаться к центральной базе данных. Для работы такой службы требуется два приложения: одно должно выполняться на том компьютере, где находится база данных, а другое — на удаленной компьютере. Приложение, выполняющееся на удалённом компьютере, отправляет запрос приложению, работающему на компьютере базы данных. После поступления запроса приложение, которое выполняется на компьютере базы данных, получает информацию из базы данных и возвращает ответ. Только этим двум приложениям известен формат сообщения и его смысл.
Каким образом две программы могут найти друг друга в такой большой сети, как Интернет? Как и в большинстве других сетей, в Интернете используется простой механизм: вначале запускается одно приложение и ждет, пока к нему не обратится другое приложение. Второму приложению должно быть известно, в каком месте его ожидает первое приложение.
Соглашение, в соответствии с которым одно сетевое приложение ждет, пока к нему не обратится другое приложение, лежит в основе систем типа клиент/сервер или архитектур распределенных вычислений по принципу клиент/сервер. Рассмотрим общий принцип и изучим основную терминологию технологии клиент/сервер.
Программа, которая ожидает запросов на установление соединения, называется сервером, а программа, которая является инициатором этих запросов, называется клиентом. Для инициализации запроса на установление соединения клиентская программа должна знать, где именно выполняется серверная программа, и указать это местонахождение сетевому программному обеспечению.
-
Основным источником информации, поступающей в оперативную базу данных является деятельность корпорации. Для проведения анализа данных требуется привлечение внешних источников информации (например, статистических отчетов). Тем самым, склад данных должен включать как внутренние корпоративные данные, так и внешние данные, характеризующие рынок в целом. -
Если для оперативной обработки, как правило, требуются свежие данные (обычно в оперативных базах данных информация сохраняется не более нескольких месяцев), то в складе данных нужно поддерживать хранение информации о деятельности корпорации и состоянии рынка на протяжении нескольких лет (для проведения достоверных анализа и прогнозирования). Как следствие, аналитические базы данных имеют объем как минимум на порядок больший, чем оперативные. -
Во многих достаточно крупных корпорациях одновременно существуют несколько оперативных информационных систем с собственными базами данных (как мы уже отмечали в этом курсе, это не очень хорошо, но часто неизбежно по историческим причинам). Оперативные базы данных могут содержать семантически эквивалентную информацию, представленную в разных форматах, с разным указанием времени ее поступления, иногда даже противоречивую (например, из-за ошибок ввода данных). Склад данных корпорации должен содержать единообразно представленные данные из всех оперативных баз данных. Эта информация должна максимально полно соответствовать текущему содержанию оперативных баз данных и быть согласованной. Отсюда следует необходимость наличия компонента склада данных, извлекающего информацию из оперативных баз данных и "очищающего" эту информацию. -
Оперативные информационные системы проектируются и разрабатываются в расчете на решение конкретных задач. Обычно набор запросов к оперативной базе данных становится известным уже на этапе проектирования системы. Информация из базы данных выбирается часто и небольшими порциями. Поэтому при проектировании оперативной базы данных можно и нужно учитывать этот заранее известный набор запросов (с известными оговорками в связи с возможными переделками информационной системы). Набор запросов к аналитической базе данных предсказать невозможно. Склады данных для того и существуют, чтобы отвечать на неожиданные (ad hoc) запросы аналитиков. Можно рассчитывать только на то, что запросы будут поступать не слишком часто и затрагивать большие объемы информации. Размеры аналитической базы данных стимулируют использование запросов с агрегатами (сумма, минимальное, максимальное, среднее значение и т.д.). -
Оперативные базы данных по своей природе являются сильно изменчивыми. Это учитывается в используемых СУБД. В частности, распространенным механизмом индексации являются B-деревья, модификация которых выполняется достаточно быстро, а строки в таблицах хранятся неупорядоченно. Аналитические базы данных меняются только тогда, когда в них загружается оперативная или внешняя информация. В результате оказывается разумным использовать другие, более быстрые при выполнении операций массовой выборки методы индексации, поддерживать упорядоченность информационных массивов, сохранять заранее вычисленные значения агрегатных функций и т.д. -
Если для оперативных информационных систем обычно хватает защиты информации на уровне таблиц (по правилам SQL-ориентированных баз данных), то информация аналитических баз данных настолько критична для корпорации, что для ее защиты требуются более тонкие приемы (например, при использовании реляционных баз данных установка индивидуальных привилегий доступа для индивидуальных строк и/или столбцов таблицы).
С учетом приведенных замечаний общая архитектура склада данных и системы аналитической обработки данных может выглядеть (Рисунок 11).
Рисунок 11 – Схематическое представление архитектуры аналитической информационной системы
В 1993 г. основоположник реляционного подхода к организации баз данных Эдвар Кодд, исходя из потребностей систем динамической аналитической обработки данных, сформулировал 12 основных требований к системам, поддерживающим аналитические базы данных. Мы приведем изложение этих требований, чтобы представить точку зрения проектировщика и разработчика системы аналитической обработки данных.
-
Многомерное концептуальное представление данных. Это требование возникает по той причине, что бизнес-пользователь естественно представляет историю и деятельность своей корпорации многомерными (например, одно измерение - время, другое - заказчики, третье - производимая продукция и т.д.). OLAP-модели должны поддерживать это представление и, естественно, оно должно хотя бы в какой-то мере опираться на возможности аналитической базы данных. -
Прозрачность. Для бизнес-пользователя не должно быть существенно, где конкретно расположены средства динамического анализа данных. При разработке OLAP-систем следует придерживаться подхода открытых систем, что позволит размещать средства анализа в любом узле корпоративной сети. -
Доступность. Логическая схема, с которой работает OLAP-система, должна отображаться в схемы разнородных физических хранилищ данных. При доступе к данным должно поддерживаться их единое и согласованное представление. -
Согласованная эффективность производства отчетов. Эта эффективность не должна деградировать при увеличении числа измерений. -
Архитектура "клиент-сервер". Серверный компонент OLAP-системы должен быть достаточно развитым, чтобы разнообразные клиенты могли подключаться к нему с минимальными усилиями и затратами на дополнительное "интегрирующее" программирование. -
Родовая многомерность. Структурные и операционные возможности работы с каждым измерением данных должны быть эквивалентны. Для всех измерений должна существовать только одна логическая структура. Любая функция, применимая к одному измерению, должна быть применима к любому другому измерению. -
Управление динамическими разреженными матрицами. Сервер OLAP-системы должен уметь эффективно хранить и обрабатывать разреженные матрицы. Физические методы доступа должны быть разнообразны, включая прямое вычисление, B-деревья, хэширование или комбинации этих методов. -
Поддержка многопользовательского режима. OLAP-система должна поддерживать многопользовательский доступ к данным (по выборке и изменению), обеспечивая целостность и безопасность данных. -
Неограниченные операции между измерениями. При выполнении многомерного анализа данных все измерения создаются и обрабатываются единообразно. OLAP-система должна быть в состоянии выполнять соответствующие вычисления между измерениями. -
Интуитивное манипулирование данными. Манипуляции, подобные смене пути анализа или уровня детализации, должны выполняться с помощью прямого воздействия на элементы OLAP-модели без потребности использовать меню или другие вспомогательные средства. -
Гибкая система отчетов. Бизнес-пользователь должен иметь возможность манипулировать данными, анализировать и/или синтезировать, а также просматривать их таким образом, как ему захочется. -
Неограниченное число измерений и уровней агрегации. OLAP-сервер должен поддерживать не менее 15 измерений для каждой аналитической модели. Для каждого измерения должно допускаться неограниченное число определяемых пользователями агрегатов.
Основным выводом из материала этого раздела является то, что подход складов данных еще слишком молод, чтобы вокруг него сложился круг общепринятых понятий, терминов, технологических приемов. Тем не менее, он кажется настолько важным и перспективным, что многие компании (в том числе и ведущие производители СУБД) ведут активную работу, чтобы быть в авангарде этого направления. Существующие идеи и реализации мы рассмотрим в пятой части курса.
5. Логическая трехзвенная модель Web-приложений
Современный подход разработки web-приложений, работающих с базами данных, основан на так называемой трехзвенной модели. В соответствии с этой моделью приложение логически разделяется на три функциональных уровня (Рисунок 12).
Рисунок 12
– Логическая трехзвенная модель Web-приложений.
-
Представления данных (Presentation) – интерфейс взаимодействия пользователя и приложения:
-
Ввод данных пользователем; -
Пересылка входных данных компонентам, которые работают с функциональной логикой приложения (business-objects); -
Получение результирующих данных от бизнес объектов; -
Представление этих результатов в требуемом виде.
-
Функциональная логика приложения (Business) – множество бизнес-объектов, которые выполняют требуемые операции над данными пользователя и местом их хранения (базой данных), т.е. которые реализуют функциональную часть приложения– часть, для которой создавалось приложение. -
Хранилище (Data) – сохранение данных, выборка, вставка, удаление и возможная модификация, целостность, резервное копирование и.т.д.– например база данных.
Трехзвенная логическая модель приложения может быть физически представлена в виде распределенного хранения и обработки данных на нескольких машинах.
Некоторые хранилища могут использоваться несколькими приложениями с дополнительными расходами по изменению уровня функциональной логики (использованием различных бизнес-объектов) и изменению уровня представления. Как правило, хранилищами являются сервера баз данных (OLTP, OLAP).
С введением такого деления на уровни критические ресурсы скрываются от пользователя (например, соединение с базами данных или транзакции).
Уровни представления данных и функциональной логики могут формироваться как на стороне сервера, так и на стороне клиента, и зависят от того, где возможно использование различных технологий и инструментария.
6. Представления данных
Несмотря на, то, что сеть обеспечивает перемещение данных из одной точки в другую, сама она остаётся пассивной. Это значит, что сеть не вырабатывает и не анализирует передаваемые данные; она даже не содержит каких-либо средств обработки информации. Все операции обработки данных выполняются прикладными программами!
При использовании сети приложения действуют парами, и каждая пара приложений использует сеть просто для обмена сообщениями. Например, рассмотрим службу управления распределенной базой данных, которая позволяет удаленным пользователям обращаться к центральной базе данных. Для работы такой службы требуется два приложения: одно должно выполняться на том компьютере, где находится база данных, а другое — на удаленной компьютере. Приложение, выполняющееся на удалённом компьютере, отправляет запрос приложению, работающему на компьютере базы данных. После поступления запроса приложение, которое выполняется на компьютере базы данных, получает информацию из базы данных и возвращает ответ. Только этим двум приложениям известен формат сообщения и его смысл.
Обработка данных в системах клиент/сервер
Каким образом две программы могут найти друг друга в такой большой сети, как Интернет? Как и в большинстве других сетей, в Интернете используется простой механизм: вначале запускается одно приложение и ждет, пока к нему не обратится другое приложение. Второму приложению должно быть известно, в каком месте его ожидает первое приложение.
Соглашение, в соответствии с которым одно сетевое приложение ждет, пока к нему не обратится другое приложение, лежит в основе систем типа клиент/сервер или архитектур распределенных вычислений по принципу клиент/сервер. Рассмотрим общий принцип и изучим основную терминологию технологии клиент/сервер.
Программа, которая ожидает запросов на установление соединения, называется сервером, а программа, которая является инициатором этих запросов, называется клиентом. Для инициализации запроса на установление соединения клиентская программа должна знать, где именно выполняется серверная программа, и указать это местонахождение сетевому программному обеспечению.