Файл: 1. Раскройте понятие информационного права. Что такое информационная среда как объект правового регулирования Информационное право.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 05.12.2023
Просмотров: 241
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
ОБ УТВЕРЖДЕНИИ ТРЕБОВАНИЙ К МЕЖСЕТЕВЫМ ЭКРАНАМ
от 28 апреля 2016 г. N 240/24/1986
РЕГЛАМЕНТЫ ТЕХНИЧЕСКИХ ОСМОТРОВ И ПРОФИЛАКТИЧЕСКИХ РАБОТ
Профилактические работы на серверах
Профилактические работы на рабочих станциях
2 Порядок ввода в эксплуатацию и перемещение компьютерного оборудования
4 Порядок работы в информационной сети
Международные стандарты[править | править код]
Государственные (национальные) стандарты РФ[править | править код]
24.Из чего состоит мониторинг событий, возникающих в процессе работы инфокоммуникационной системы?
Поскольку полностью исключить возможность отказа или некорректной работы техники невозможно, решение заключается в том, чтобы обнаруживать проблемы на наиболее ранних стадиях, и получать о них наиболее подробную информацию. Для этого, как правило, применяется различное ПО мониторинга и контроля сети, которое способно как своевременно оповещать технических специалистов об обнаруженной проблеме, так и накапливать статистические данные о стабильности и других параметрах работы серверов, сервисов и служб, доступные для подробного анализа.
Ниже мы рассматриваем базовые методы мониторинга работы сети и контроля ее защищенности.
Методы мониторинга состояния сети
Выбор способов и объектов мониторинга сети зависит от множества факторов – конфигурации сети, действующих в ней сервисов и служб, конфигурации серверов и установленного на них ПО, возможностей ПО, используемого для мониторинга и т.п. На самом общем уровне можно говорить о таких элементах как:
-
проверка физической доступности оборудования; -
проверка состояния (работоспособности) служб и сервисов, запущенных в сети; -
детальная проверка не критичных, но важных параметров функционирования сети: производительности, загрузки и т.п.; -
проверка параметров, специфичных для сервисов и служб данного конкретного окружения (наличие некоторых значений в таблицах БД, содержимое лог-файлов).
Начальный уровень любой проверки – тестирование физической доступности оборудования (которая может быть нарушена в результате отключения самого оборудования либо отказе каналов связи). Как минимум, это означает проверку доступности по ICMP-протоколу (ping), причем желательно проверять не только факт наличия ответа, но и время прохождения сигнала, и количество потерянных запросов: аномальные значения этих величин, как правило, сигнализируют о серьезных проблемах в конфигурации сети. Некоторые из этих проблем легко отследить при помощи трассировки маршрута (traceroute) – ее также можно автоматизировать при наличии «эталонных маршрутов».
Следующий этап – проверка принципиальной работоспособности критичных служб. Как правило, это означает TCP-подключение к соответствующему порту сервера, на котором должна быть запущена служба, и, возможно, выполнение тестового запроса (например, аутентификации на почтовом сервере по протоколу SMTP или POP или запрос тестовой страницы от веб-сервера).
В большинстве случаев, желательно проверять не только факт ответа службы/сервиса, но и задержки – впрочем, то относится уже к следующей по важности задаче: проверке нагрузки. Помимо времени отклика устройств и служб для различных типов серверов существуют другие принципиально важные проверки: память и загруженность процессора (веб-сервер, сервер БД), место на диске (файл-сервер), и более специфические – например, статус принтеров у сервера печати.
Способы проверки этих величин варьируются, но один из основных, доступных почти всегда – проверка по SNMP-протоколу. Помимо этого, можно использовать специфические средства, предоставляемые ОС проверяемого оборудования: к примеру, современные серверные версии ОС Windows на системном уровне предоставляют так называемые счетчики производительности (performance counters), из которых можно «считать» довольно подробную информацию о состоянии компьютера.
Наконец, многие окружения требуют специфических проверок – запросов к БД, контролирующих работу некоего приложения; проверка файлов отчетов или значений настроек; отслеживание наличия некоторого файла (например, создаваемого при «падении» системы).
Контроль безопасности сети
Безопасность компьютерной сети (в смысле защищенности ее от вредоносных действий) обеспечивается двумя методами: аудитом и контролем. Аудит безопасности – проверка настройки сети (открытых портов, доступности «внутренних» приложений извне, надежности аутентификации пользователей); методы и средства аудита выходят за рамки данной статьи.
Сущность контроля безопасности состоит в выявлении аномальных событий в функционировании сети. Предполагается, что базовые методы обеспечения и контроля безопасности (аутентификация, фильтрация запросов по адресу клиента, защита от перегрузок и т.п.) встроена во все серверное ПО. Однако, во-первых, не всегда можно доверять этому предположению; во-вторых, не всегда такой защиты достаточно. Для полноценной уверенности в безопасности сети в большинстве случаев необходимо использовать дополнительные, внешние средства. При этом проверяют, как правило, следующие параметры:
нагрузку на серверное ПО и «железо»: аномально высокие уровни загрузки процессора, внезапное сокращение свободного места на дисках, резкое увеличение сетевого трафика зачастую являются признаками сетевой атаки;
журналы и отчеты на наличие ошибок: отдельные сообщения об ошибках в лог-файлах программ-серверов или журнале событий серверной ОС допустимы, но накопление и анализ таких сообщений помогает выявить неожиданно частые или систематические отказы;
состояние потенциально уязвимых объектов – например, тех, «защищенность» которых тяжело проконтролировать напрямую (ненадежное стороннее ПО, изменившаяся/непроверенная конфигурация сети): нежелательные изменения прав доступа к некоторому ресурсу или содержимого файла может свидетельствовать о проникновении «врага».
Во многих случаях аномалии, замеченные при мониторинге и контроле, требуют немедленной реакции технических специалистов, соответственно, средство мониторинга сети должно иметь широкие возможности для пересылки оповещений (пересылка сообщений в локальной сети, электронной почтой, Интернет-пейджером). Изменения других контролируемых параметров реакции не требуют, но должны быть учтены для последующего анализа. Зачастую же необходимо и то, и другое – непрерывный сбор статистики плюс немедленная реакции на «выбросы»: например, отмечать и накапливать все случаи загрузки процессора более 80%, а при загрузке более 95% – немедленно информировать специалистов. Полноценный мониторинговый софт должен позволять организовывать все эти (и более сложные) сценарии.
Использование Alchemy Eye для мониторинга состояния сети и контроля ее безопасности
Alchemy Eye – средство мониторинга состояния серверов в сети с богатыми возможностями. Ниже показано, как реализуются сценарии, описанные в предыдущих разделах, посредством этой программы.
Прежде всего, чтобы обеспечить непрерывность мониторинга, нужно запустить программу как NT-службу (установить ее в Файл>Настройки>NT-служба, затем запустить из Панели управленияWindows). После запуска службы появится иконка в области уведомлений (системном трее), по клику на ней откроется главное окно программы, где и нужно создать необходимые проверки.
Alchemy Eye позволяет создавать любое количество объектов мониторинга(«сервер» в терминах программы, но пусть это вас не смущает: одному физическому серверу может соответствовать любое количество объектов мониторинга). Каждому объекту мониторинга соответствует проверка одного типа для одного компьютера.
Чтобы добавить проверку в программ, откройте диалог создания нового сервера (меню «Сервер>Добавить сервер>Новый») – рис 1. На основной закладке этого диалога нужно задать логическое имя для объекта мониторинга, интервал между проверками, и тип проверки.
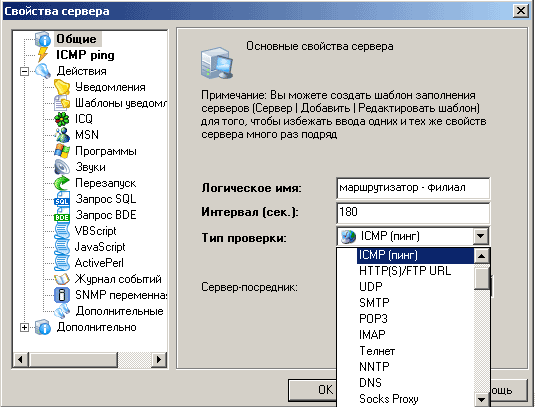
Рис.1. Выбор типа проверки сервера.
Скриншот на рис.1 может продемонстрировать лишь небольшое количество типов проверок, доступных в программе (полный список вы можете посмотреть самостоятельно). Для ориентировки можно привести соответствия между задачами, описанными выше, и некоторыми проверками, доступными в Alchemy Eye:
Проверка физической доступности оборудования: ICMP, UDP, трассировка маршрута (traceroute).
Проверка работоспособности служб и сервисов, запущенных в сети: все стандартные протоколы (POP/SMTP, DNS, DHCP, HTTP/FTP), подключение к базам данных (Oracle, MySQL, MS SQL Server, или любая БД, доступная через источники данных ODBC). Кроме того, Alchemy Eye предоставляет мощное средство для проверки нестандартных серверов – TCP-скрипт. В этой проверке можно описать достаточно сложную логику подключения к порту сервера, отсылки ему любых строк-команд и тестирования ответов.
Проверка нагрузки сети и отдельных служб: можно использовать проверку стандартных переменных SNMP MIB (Management Information Base) – программа не только позволяет контролировать их, но и предоставляет дерево-список всех доступных в MIB переменных (рис. 2). Счетчики производительности для Windows-машин доступны «из коробки» (рис. 3), а сходная функциональность для nix-серверов – в виде бесплатного плагина на сайте производителя.
Проверка специфических параметров* для данного окружения: список проверок включает и SQL-запросы с проверкой результата, и анализ лог-файлов (в том числе на удаленных компьютерах), и еще более специфичные проверки (например, анализ значений ключей реестра или журнала событий Windows).
Проверка состояния уязвимых объектов: сюда можно отнести подключение по TCP/IP к любому порту удаленного компьютера, проверка прав доступа к различным файлам и папкам (права могут быть изменены злоумышленником или некачественным ПО), проверка количества файлов в определенной папке и сравнения файла по содержимому с эталоном.
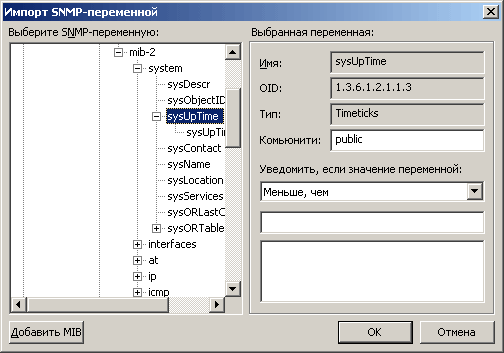
Рис.2. Браузер дерева MIB – выбор переменной для SNMP-мониторинга.
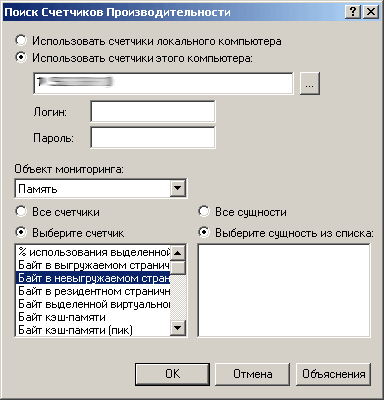
Рис.3. Браузер счетчиков производительности Windows – выбор параметра для мониторинга.
В случае сложных окружений, для которых недостаточно встроенных проверок, можно использовать одну из возможностей расширения, доступных в Alchemy Eye: запуск скриптовых функций (VBScript, JavaScript, ActivePerl) или внешних приложений, а так же подсистему плагинов.
После выбора типа проверки нужно задать ее параметры – как правило, они включают адрес проверяемого сервера и несколько других, очевидных либо в деталях объясняемых всплывающими подсказками. На рис.4 показана страница выбора параметров ICMP-проверки.
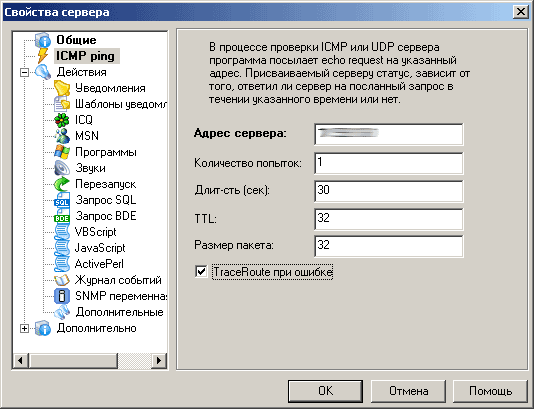
Если проверка является критичной (ее несрабатывание требует немедленного внимания технических специалистов), в этом же диалоге необходимо настроить уведомления: Alchemy Eye может отсылать их с помощью электронной почты, ICQ/MSN (обратите внимание, что в настройках программы должен быть настроен доступ к соответствующим аккаунтам) или сообщениями локальной сети (net send).
Когда объекты мониторинга созданы, главное окно Alchemy Eye само по себе становится инструментом анализа текущей ситуации, наглядно отображая состояния серверов (рис.5). Если заданных проверок больше чем 4-5 (и к тому же, они имеют разную степень критичности), лучше всего разбить их по папкам (впоследствии это даст дополнительные «приятности», вроде возможности сгенерировать отчеты только для проверок из конкретной папки).
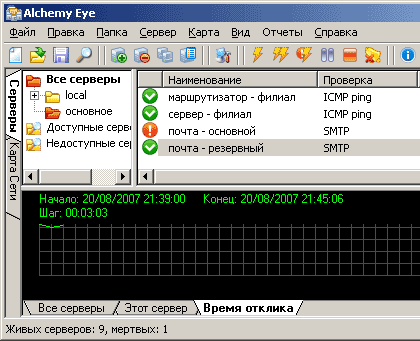
Рис.5. Главное окно Alchemy Eye – мониторинг серверов (3 успешных проверки, 1 сбой).
Все проверки Alchemy Eye «бинарные» (проверка либо прошла, либо нет), но на количество однотипных проверок никаких ограничений не накладывается. Таким образом, встроенных средств программы вполне достаточно для реализации сложных сценариев: например, две независимые проверки загрузки процессора одного и того же сервера – одна будет «ловить» загрузку выше 95% и немедленно сообщать о проблеме техническим специалистам, а другая – загрузку выше 80% для статистического учета и последующего анализа.
Задачи этого рода (учет и анализ) в Alchemy Eye решаются с помощью встроенных отчетов (меню Отчеты). Стоит учесть, что вся статистика выполненных программой проверок и их результатов записывается в стандартной форме в файл stat.csv в папке программы, данные из него можно использовать для последующего анализа (Alchemy Eye позволяет подключать сторонние программы-анализаторы в качестве генераторов отчетов – подробная инструкция имеется в справке программы).
Напоследок хотелось бы заметить, что даже при наличии качественного программного средства разработка работающей