ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 12.12.2023
Просмотров: 45
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Слова Р и М называют эквивалентными, если существует цепочка от Р к М и обратно.
Пример
Алфавит Подстановки
{а, b, с, d, е} ас - сa, abac - abace
ad - da; eca - ae
bc - cb; eda - be
bd - db; edb - be
Слова abcde и acbde - смежные (подстановка bc - cb). Слова abcde - cadbe эквивалентны.
Может быть рассмотрен специальный вид ассоциативного исчисления, в котором подстановки являются ориентированными: N → М (стрелка означает, что подстановку разрешается производить лишь слева направо). Для каждого ассоциативного исчисления существует задача: для любых двух слов определить, являются ли они эквивалентными или нет.
Любой процесс вывода формул, математические выкладки и преобразования также являются дедуктивными цепочками в некотором ассоциативном исчислении. Построение ассоциативных исчислений является универсальным методом детерминированной переработки информации и позволяет формализовать понятие алгоритма.
Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом в алфавите А называется понятное точное предписание, определяющее процесс над словами из А и допускающее любое слово в качестве исходного. Алгоритм в алфавите А задается в виде системы допустимых подстановок, дополненной точным предписанием о том, в каком порядке нужно применять допустимые подстановки и когда наступает остановка.
Пример
Алфавит: Система подстановок В:
А = {а, b, с} cb - cc
сса - аb
ab – bса
Предписание о применении подстановок: в произвольном слове Р надо сделать возможные подстановки, заменив левую часть подстановок на правую; повторить процесс с вновь полученным словом.
Так, применяя систему подстановок В из рассмотренного примера к словам babaac и bсaсаbс получаем:
babaac → bbcaaac → остановка
bcacabc → bcacbcac → bcacccac → bсасаbс → бесконечные процесс (остановки нет), так как мы получили исходное слово.
Предложенный А.А.Марковым способ уточнения понятия алгоритма основан на понятии нормального алгоритма, который определяется следующим образом. Пусть задан алфавит А и система подстановок В. Для произвольного слова Р подстановки из В подбираются в том же порядке, в каком они следуют в В. .Если подходящей подстановки нет, то процесс останавливается. В противном случае берется первая из подходящих подстановок и производится замена ее правой частью первого вхождения ее левой части в
Р. Затем все действия повторяются для получившегося слова P1. Если применяется последняя подстановка из системы В, процесс останавливается.
Такой набор предписаний вместе с алфавитом А и набором подстановок В определяют нормальный алгоритм. Процесс останавливается только в двух случаях: 1) когда подходящая подстановка не найдена; 2) когда применена последняя подстановка из их набора. Различные нормальные алгоритмы отличаются друг от друга алфавитами и системами подстановок.
Приведем пример нормального алгоритма, описывающего сложение -натуральных чисел (представленных наборами единиц).
Пример
Алфавит: Система подстановок В:
А = (+, 1) 1 + → + 1
+ 1 → 1
1 → 1
Слово Р: 11+11+111
Последовательная переработка слова Р с помощью нормального алгоритма Маркова проходит через следующие этапы:
Р = 11 + 11 + 111 Р5 = + 1 + 111111
Р1 = 1 + 111 + 111 Р6 = ++ 1111111
Р2 = + 1111 + 111 Р7 = + 1111111
Р3 = + 111 + 1111 Р8 = 1111111
Р4 = + 11 + 11111 Р9 = 1111111
Нормальный алгоритм Маркова можно рассматривать как универсальную форму задания любого алгоритма. Универсальность нормальных алгоритмов декларируется принципом нормализации: для любого алгоритма в произвольном конечном алфавите А можно построить эквивалентный ему нормальный алгоритм над алфавитом А,
Разъясним последнее утверждение. В некоторых случаях не удается построить нормальный алгоритм, эквивалентный данному в алфавите А, если использовать в подстановках алгоритма только буквы этого алфавита. Однако, можно построить требуемый нормальный алгоритм, производя расширение алфавита А (добавляя к нему некоторое число новых букв). В этом случае говорят, что построенный алгоритм является алгоритмом над алфавитом А, хотя он будет применяться лишь к словам в исходном алфавите A.
Если алгоритм N задан в некотором расширении алфавита А, то говорят, что N есть нормальный алгоритм над алфавитом А.
Условимся называть тот или иной алгоритм нормализуемым, если можно построить эквивалентный ему нормальный алгоритм, и ненормализуемым в противном случае. Принцип нормализации теперь может быть высказан в видоизмененной форме: все алгоритмы нормализуемы.
| Данный принцип не может быть строго доказан, поскольку понятие произвольного алгоритма не является строго определенным и основывается на том, что все Известные в настоящее время алгоритмы являются нормализуемыми, а способы ромпозиции алгоритмов, позволяющие строить новые алгоритмы из уже известных, не выводят за пределы класса нормализуемых алгоритмов. Ниже перечислены способы композиции нормальных алгоритмов.
I. Суперпозиция алгоритмов. При суперпозиции двух алгоритмов А и В выходное слово первого алгоритма рассматривается как входное слово второго алгоритма В. Результат суперпозиции С может быть представлен в виде С(р) = В(А(р)),
II. Объединение алгоритмов. Объединением алгоритмов А и В в одном и том же алфавите называется алгоритм С в том же алфавите, преобразующий любое слово р, содержащееся в пересечении областей определения алгоритмов А и В, в записанные рядом слова А(р) и В(р).
III. Разветвление алгоритмов. Разветвление алгоритмов представляет собой композицию D трех алгоритмов А, В и С, причем область определения алгоритма Dявляется пересечением областей определения всех трех алгоритмов А, В и С, а для любого слова р из этого пересечения D(p) = А(р), если С(р) = е, D(p) = B(p), если С(р) = е, где е - пустая строка.
IV. Итерация алгоритмов. Итерация (повторение) представляет собой такую композицию С двух алгоритмов А и В, что для любого входного слова р соответствующее слово С(р) получается в результате последовательного многократного применения алгоритма А до тех пор, пока не получится слово, преобразуемое алгоритмом В.
Нормальные алгоритмы Маркова являются не только средством теоретических построений, но и основой специализированного языка программирования, применяемого как язык символьных преобразований при разработке систем искусственного интеллекта. Это один из немногих языков, разработанных в России и получивших известность во всем мире.
Существует строгое доказательство того, что по возможностям преобразования нормальные алгоритмы Маркова эквивалентны машинам Тьюринга.
. РЕКУРСИВНЫЕ ФУНКЦИИ
Еще одним подходом к проблеме формализации понятия алгоритма являются, так называемые, рекурсивные функции. Исторически этот подход возник первым, поэтому в математических исследованиях, посвященных алгоритмам, он имеет наибольшее распространение.
Рекурсией называется способ задания функции, при котором значение функции при определенном значении аргументов выражается через уже заданные значения функции при других значениях аргументов. Применение рекурсивных функций в теории алгоритмов основано на идее нумерации слов в произвольном алфавите последовательными натуральными числами. Таким образом любой алгоритм можно свести к вычислению значений некоторой целочисленной функции при целочисленных значениях аргументов.
Введем несколько основных понятий. Пусть X, Y - два множества. Частичной функцией (или отображением) из Х в Y будем называть пару
Через N будем обозначать множество натуральных чисел. Через (N)n (при п ³ 1) будем обозначать n-кратное декартово произведение N на себя, т.е. множество упорядоченных n-ок (х1 ..., xn), хi Ì N. Основным объектом дальнейших построений будут частичные функции из (N)m в (N)n для различных т и п.
Частичная функция f из (N)m в (N)n называется вычислимой, если можно указать такой алгоритм («программу»), который для входного набора х Ì (N)m дает на выходе f(x), если х Ì D(f) и нуль, если х Ë D(f). В этом определении неформальное понятие алгоритма (программы) оказывается связанным (отождествленным) с понятием вычислимости функции. Вместо алгоритмов далее будут изучаться свойства вычислимых функций. Вместо вычислимых функций оказывается необходимым использовать более широкий класс функций (и более слабое определение) - полувычислимые функции. Частичная функция из (N)" в (N)" полувычислима, если можно указать такой алгоритм (программу), который для входного набора х с (N)" дает на выходе х е D(f), или алгоритм работает неопределенно долго, если х е D(f). Очевидно, что вычислимые функции полувычислимы, а всюду определенные полувычислимые функции вычислимы.
Частичная функция f называется невычислимой, если она не является ни вычислимой, ни полувычислимой.
Из вновь введенных понятий основным является полувычислимость, так как вычислимость сводится к нему. Существуют как невычислимые функции, так и функции, являющиеся полувычислимыми, но не вычислимые. Пример такой функции:
Можно показать, что существует такой многочлен с целыми коэффициентами P(t, x1,...,xn), что g(t
) - невычислима. Однако, легко видеть, что g(t) - полувычислима.
Фундаментальным открытием теории вычислимости явился, так называемый, тезис Черча, который в слабейшей форме имеет следующий вид: можно явно указать а) семейство простейших полувычислимых функций; б) семейство элементарных операций, которые позволяют строить по одним полувычислимым функциям другие полувычислимые функции с тем свойством, что любая полувычислимая функция получается за конечное число шагов, каждый из которых состоит в применении одной из элементарных операций к ранее построенным или к простейшим функциям.
Простейшие функции:
suc: N ®N; suc(x) = x+1 - определение следующего за х числа;
l(n): (N)n ® N; l(n) (x1,..., хn) = 1, п ³ 0 - определение «размерности» области определения функции;
рr
Элементарные операции над частичными функциями:
а) композиция (или подстановка) ставит в соответствие паре функций f из (N)m в (N)n и g из (N)n в (N)p функцию h = gof из (N)m в (N)p , которая определяется как
б) соединение ставит в соответствие частичным функциям fi из (N)ni, i = 1, ..., kфункцию (fi, ...,fk) из (N)m в (N)n1 х... х (N)nk, которая определяется как
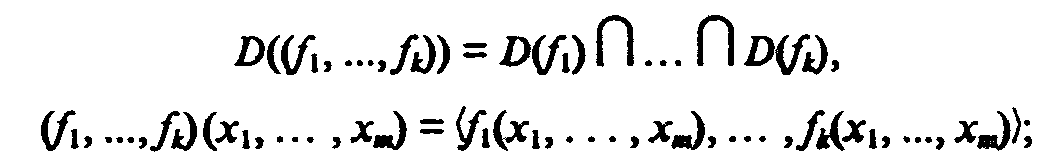
в) рекурсия ставит в соответствие паре функций f из (N)n в N и g из (N)n+2 в N функцию h из (N)n+2 в N, которая определяется рекурсией по последнему аргументу
h(x1