Файл: Учебнометодическое пособие знакомит студентов с основными понятиями о.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 12.12.2023
Просмотров: 473
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Внимание: Если число градаций независимой переменной две рекомендуется использовать группу методов из раздела «Сравнение независимых выборок».
Нажатие кнопки «Вычислить» приводит к переключению в окно результаты
Результаты дисперсионного анализа Фишера
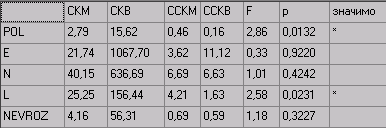
В том случае если в окне настроек установлена галочка «Выводить только достоверные значения»

Как видно из примера, в этом случае не отображается колонка «значимо» и результаты отображаются в соответствии с выбранным уровнем значимости.
Внимание: Дисперсионный анализ показывает только влияние фактора на переменную, но не его направленность.
В вышеприведенном примере, переменная возраст, в принципе не может повлиять на пол обследуемого (это скорее связано с разными частотами юношей и девушек в разных возрастных группах), а влияние на переменную L выявлено, но не ясно в каких возрастах преобладают более высокие или более низкие значения.
Внимание: Для изучения направленности влияний рекомендуется использовать критерий Шеффе (см. раздел «Сравнение независимых выборок»
Результаты дисперсионного анализа Краскела-Уоллиса
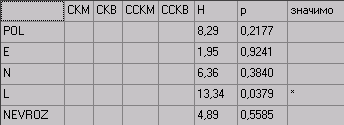
Установлена галочка «Выводить только достоверные значения»
Внимание: Поскольку дисперсионный анализ Краскела-Уоллиса выполняется не через расчет межгрупповых и групповых дисперсий, а через суммы рангов, то галочки напротив соответствующих настроек игнорируются. Поэтому при проведении этого анализа рекомендуется их убирать.
Интерпретация результатов аналогична однофакторному дисперсионному анализу Фишера.
Корреляционный анализ
Необходимо выбрать пункт меню "Статистика→Корреляционный анализ" или нажать кнопку
Предусмотрены следующие виды анализа в зависимости от характера исходных данных и типа распределения изучаемых переменных:
| Количественные переменные, имеющие нормальное распределение | Количественные переменные, не имеющие нормальное распределение или порядковые переменные |
| Корреляционный анализ Пирсона | Корреляционный анализ Спирмена |
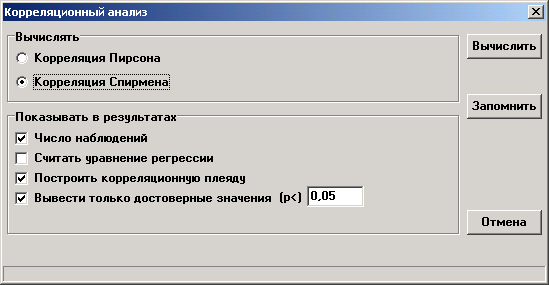
Внимание: О проверке соответствия переменной нормальному закону распределения см раздел «Проверка типа распределения эмпирических данных». Если проверка не выполнялась рекомендуется использовать корреляции Спирмена.
Внимание: Для номинальных переменных см раздел «Частотный анализ»
Внимание: Настройка «Считать уравнение регрессии» работает только для корреляции Пирсона. Это связано с тем, что метод наименьших квадратов разработан для количественных переменных.
При выборе опции «Считать уравнение регрессии» вычисляются два уравнения вида: y=a+bx и x=a+by, где y – это первая из пары переменных, x – вторая, b – угол наклона, а – свободный член.
| | a(xy) | b(xy) | a(yx) | b(yx) |
| VOZRAST - L | 10,73 | 0,29 | 1,69 | 0,23 |
| | VOZRAST=10,73+0,29*L | L=1,69+0,23*VOZRAST | ||
Пример уравнений регрессии и интерпретация.
Внимание: Уравнения регрессии считаются только при вычислениях коэффициентов корреляции Пирсона. При вычислении корреляций Спирмена эта опция окна настроек игнорируется.
 | 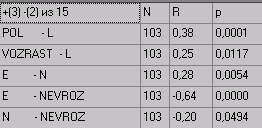 |
| Все корреляции | Только достоверные |
| Обозначения: N- число наблюдений R –коэффициент корреляции Р – доверительный уровень | |
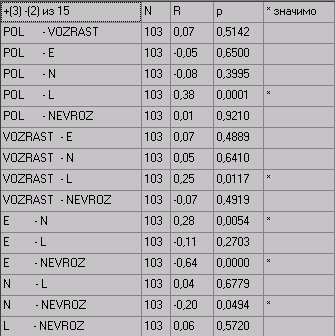
В левом верхнем углу таблицы результатов показано количество статистически значимых прямых, обратных корреляций и их общее число.
Вычисление корреляций осуществляется по принципу «каждая переменная с каждой». Результат выводится только один раз. Поэтому взаимосвязи последних переменных как бы размазаны по всей таблице. В приведенном примере корреляция POL – VOZRAST есть вначале таблицы, поэтому корреляция VOZRAST – POL не приводится.
Внимание: Если установлена опция выводить только достоверные корреляции, а их нет, таблица результатов будет пустой.
По результатам можно построить график взаимосвязей.
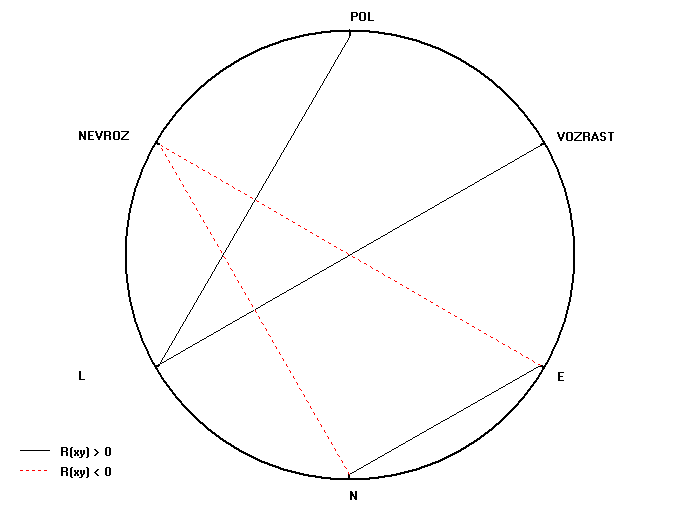
Внимание: Вне зависимости от настроек на графике будут отображены только достоверные корреляции (-уровень обычно принимается равным 0,05 или 0,01). Если -уровень не указан, он принимается равным 0,05.
На графике красным цветом и пунктиром отмечены отрицательные связи, черным цветом и прямыми линиями – положительные.
График можно сохранить в формате Windows BITMAP (*.bmp) или скопировать его в буфер обмена для последующей вставки в другие программы.
Внимание: Число переменных на графике не должно превышать 30. Иначе на графике они будут сливаться и график утратит информативность.
Внимание: Все названия переменных для графика берутся из базы данных. Поэтому рекомендуется называть переменные по-русски и одним или двумя словами.
Множественная регрессия
Необходимо выбрать пункт меню "Статистика→Множественная регрессия" или нажать кнопку
Внимание: Для анализа следует использовать только количественные переменные.
Таблица результатов выглядит следующим образом
| | Beta | B | Ошибка B | T | p |
| Константа | | -0,14438 | | | |
| POL | 0,477863 | 1,501299 | 0,272995 | 5,499373 | 0 |
| VOZRAST | 0,230028 | 0,204517 | 0,077257 | 2,647229 | 0,009472 |
| E | -0,09659 | -0,03945 | 0,035486 | -1,11158 | 0,269065 |
| N | 0,091918 | 0,047624 | 0,045021 | 1,057812 | 0,292768 |
| NEVROZ | 0,009348 | 0,016204 | 0,150626 | 0,107581 | 0,91455 |
| | Бета- коэффициенты | Коэффициенты B | Ошибка коэффициентов B | Т критерий | Р |
| Коэфф. детерминации | 0,310677 | | | | |
| Коэфф. корреляции | 0,557384 | | | | |
| Дисперсия регрессии | 11,28934 | | | | |
| Остаточная дисперсия | 1,291161 | | | | |
| F - критерий | 8,743553 | F- критерий уравнения | |||
| p | 0,000001 | Достигнутый уровень значимости | |||
| Ошибка регресии | 1,136293 | | | | |
Таким образом суммарное уравнение выглядит следующим образом:
L=1,501299*POL+0,204517*VOZRAST-0,03945*E+0,047624*N+0,016204*NEVROZ-0,14438
Внимание: В модель включаются все переменные, находящиеся в закладке «Выборка», за исключением независимой переменной. Поэтому для улучшения прогноза рекомендуется предварительно воспользоваться обычным корреляционным анализом и выбрать для прогноза только те переменные, которые влияют на результативный признак.
Проверка типа распределения эмпирических данных
Для правильного выбора метода статистического анализа необходимо знать тип распределения эмпирических данных, и в первую очередь, соответствует ли эмпирическое распределение теоретическому нормальному.
Для выполнения проверки необходимо выбрать пункт меню "Статистика→Проверка типа распределения" или нажать кнопку
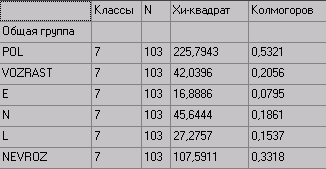
Значения критериев
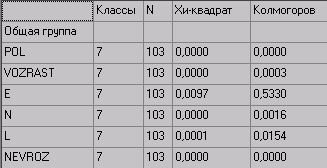
Достигнутый уровень значимости (доверительный уровень)
Внимание: Число классов вычисляется автоматически по формуле Стерджесса 1+3,32*log10(N).
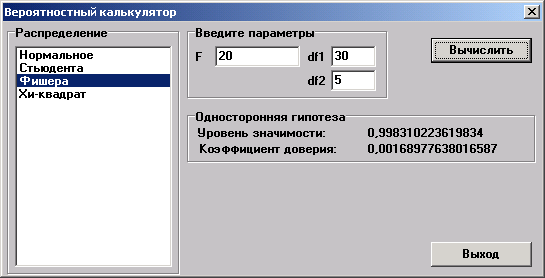
Вероятностный калькулятор
Вероятностный калькулятор позволяет переводить значение параметра распределения в уровень значимости для односторонней и, там где это возможно, для двусторонней гипотезы.
Необходимо выбрать пункт меню "Статистика→Вероятностный калькулятор.
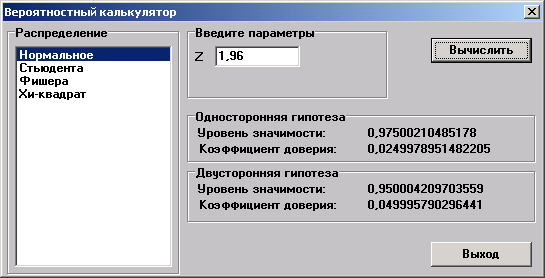
Внимание: df1, df2 – число степеней свободы. Вычисляется на основе числа наблюдений.
Задания для самостоятельной работы с программой