Файл: Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214.docx
Добавлен: 12.01.2024
Просмотров: 638
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Основные требования к отчетам по лабораторным работам
Лабораторная/практическая работа № 1
Лабораторная/практическая работа № 2
Лабораторная/практическая работа № 3
Лабораторная/практическая работа № 4
Лабораторная/практическая работа № 5
Лабораторная/практическая работа № 6
Лабораторная/практическая работа № 7
Лабораторная/практическая работа № 6
-
Название работы: «Синтаксис языков программирования. Преобразование транслируемой программы в постфиксную форму записи». -
Цели работы: изучение задач и методов преобразования текста транслируемой программы постфиксную форму записи (ПФЗ) для выявления заложенной в алгоритм последовательности операций, приобретение навыков разработки действий, реализующих преобразования. -
Основные теоретические сведения:
-
Постфиксная форма записи
Конечной целью работы транслятора является эквивалентное преобразование текста программы на исходном языке в код, который может исполнять реальная или виртуальная вычислительная машина. Компиляторы формируют машинный код для реального компьютера, интерпретаторы – для виртуальной машины. Требование эквивалентности преобразования означает, что результаты выполнения исходной (мысленного) и преобразованной (физического) программ при одинаковых обрабатываемых данных должны быть идентичными. Процессы (истории) выполнения программ, записанных на различных языках, можно рассматривать как последовательности выполнения различных по сложности операций. В исходной программе это могут быть операции уровня вычисления сложного выражения, выполнения итерации цикла или ветки условного оператора или переключателя. В машинном или в виртуальном коде это операции уровня сложения двух чисел, сравнения значений, условной или безусловной передачи управления из одной точки программы в другую. При формальных преобразованиях, выполняемых трансляторами, добиться эквивалентности можно только в том случае, если гарантируется, что в любой паре историй работы выполнению каждой операции исходной программы соответствует выполнение эквивалентной ей последовательности из одной или нескольких операций машинного или виртуального кода (далее машинный или виртуальный код будет называться объектным).
Таким образом, транслятор рано или поздно обязан выяснить, какие операции и в какой последовательности должны выполняться согласно алгоритму обработки данных, определенному текстом исходной программы. Здесь очень важным моментом является соотношение между синтаксисом (определяющим способ записи последовательности операций) и семантикой (определяющей способ выполнения этой последовательности) для языков разного уровня. Любой язык программирования высокого уровня ориентирован на предоставление максимальных удобств разработчику программ. Поэтому, как правило, последовательность появления знаков операций в тексте исходной программы не совпадает с последовательностью их выполнения в истории работы программы. Приведем простейший пример. Пусть в тексте программы на языке С/С++ записан оператор присваивания
a=b*c+d;
Последовательность появления знаков операций в тексте такова: = * + . Однако выполнение этого оператора, в целом определяемое семантикой языка, эквивалентно последовательности выполнения трех элементарных операций, эквивалентных машинным командам:
-
умножить значение b на значение c(операция *); -
сложить полученное значение со значением d(операция +); -
присвоить последнее полученное значение переменной a(операция =).
Следовательно, в объектном коде знаки операций должны быть записаны в последовательности * + = , поскольку семантика машинно-ориентированных языков предусматривает последовательную выборку выполняемых команд из линейно организованной памяти. Легко можно привести множество других примеров, из которых следует, что привычная для человека форма записи выражений, операторов присваивания и других операторов языков программирования существенно отличается от того вида, в котором они должны быть представлены в объектном коде.
Весьма существенные отличия форм представления исходной и объектной программ характерны для управляющих конструкций языков программирования, таких как условные операторы, переключатели и операторы цикла. Синтаксис таких конструкций не предусматривает явной записи операций передач управления, подразумеваемых семантикой языка, и ориентирован на удобство использования человеком. Однако в процессе эквивалентного преобразования исходной программы эти операции, очевидно, должны появиться в тексте объектной программы. Например, пусть в тексте программы на языке С/С++ записан условный оператор:
if ( c>0 )
a = b * c + d;
else
a = ( d – b ) * c;
Смысл этой записи совершенно ясен человеку и сводится к тому, что должна быть выполнена определенная последовательность действий:
-
Вычислить результат сравнения значения c с нулем и получить булевское значение true или false. -
Если результат сравнения есть false, то перейти к шагу 7 (к выполнению оператора, записанного внутри ветки else). -
Перемножить значения b и c. -
Сложить полученное значение с d. -
Присвоить полученное значение переменной a. -
Перейти к шагу 10. -
Вычесть значение b из значения d. -
Умножить результат вычитания на значение c. -
Присвоить полученное значение переменной a. -
… ( Следующий по тексту оператор программы. )
Именно в этой последовательности должны быть записаны операции в тексте объектного кода, для того чтобы процессор компьютера (или виртуальная машина) мог выбирать их из оперативной памяти и выполнять. В этом представлении появились операции переходов (передач управления) на шагах 2 и 6, отсутствующие в явном виде в исходном тексте, но подразумеваемые семантикой входного языка.
Постфиксная форма записи (ПФЗ), эквивалентная исходному оператору и содержащая близкие к машинно-ориентированному языку элементы, может выглядеть так:
c 0 >labelF JmpF a b c * d +=labelEnd Jmp labelF: a d b – c *=labelEnd:
В этой записи жирным шрифтом выделены слова, добавленные при преобразовании, и подчеркнуты знаки операций, в том числе операции условной (JmpF) и безусловной (Jmp) передачи управления. Операнды каждой операции записаны перед знаком этой операции. Все знаки операций, кроме унарной безусловной передачи управления, являются бинарными (используют два операнда). Унарная операция Jmp имеет единственный операнд – метку labelEnd. Метки, именующие некоторые операторы программы и используемые в операциях перехода, введены при преобразовании исходного кода в постфиксную форму записи.
Особо отметим, что в постфиксной записи второго оператора присваивания отсутствуют скобки, изменяющие порядок выполнения операций в исходном операторе программы. Постфиксная форма записи уникальна тем, что:
– последовательность появления в ней знаков операций совпадает с требуемым порядком их выполнения;
– не нужны скобки для изменения порядка выполнения операций.
Задача выявления последовательности операций, эквивалентной исходной программе, хотя и определяется во многом семантикой двух языков, но имеет глубокие внутренние связи с задачей восстановления дерева грамматического разбора и решается, как правило, на этапе синтаксического анализа.
-
Синтаксические деревья и постфиксная форма записи
Синтаксическим деревом или деревом операций называется такое графическое представление совокупности операций, связанных значениями обрабатываемых данных (операндами), в котором:
-
узлы (вершины дерева, из которых выходят дуги, ведущие к потомкам) помечены знаками операций; -
листья (концевые вершины дерева, не имеющие потомков) помечены наименованиями операндов; -
нет вершин, помеченных какими-либо другими символами.
Синтаксическое дерево оператора присваивания a=b*c+d; может выглядеть так, как показано на рис. 6.1, а. На рис. 6.1, б для сравнения показано дерево грамматического разбора этого оператора в грамматике Ga1, расширенной путем добавления правила P : i = S ; для нового начального нетерминала P.
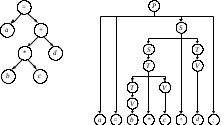
а б
Рис. 6.1. Связь дерева операций и дерева разбора:
а – дерево операций; б – дерево грамматического разбора
Синтаксическое дерево (рис. 6.1., а) в наглядной форме показывает зависимость операций друг от друга и может быть использовано для определения последовательности их выполнения. Ясно, что до тех пор, пока не вычислено произведение значений b и c, не может быть выполнена операция сложения.
В свою очередь, операция присваивания зависит от результата выполнения операции сложения и может быть выполнена только после нее. Может быть определена точная процедура обхода синтаксического дерева для построения требуемой последовательности операций в линейном представлении.
Дерево грамматического разбора, восстанавливаемое при проверке правильности данного оператора присваивания и показанное на рис. 6.1., б, также содержит всю необходимую информацию для решения этой задачи. Однако это дерево содержит «лишние» с точки зрения выявления последовательности операций элементы: вершины, помеченные нетерминалами и выходящими их них дугами, а также вершину, помеченную ограничителем оператора присваивания (;) вместе со всеми дугами, ведущими к таким вершинам. В данном операторе не использовались скобки (), но если бы они и были, то также считались бы «лишними».
Дерево грамматического разбора может быть преобразовано в дерево операций путем применения следующей процедуры.
Шаг 1. Удалить все листья (вершины, помеченные терминальными символами), пометки которых не являются знаками операций и наименованиями операндов.
Шаг 2. Просмотреть узлы дерева (вершины, имеющие исходящие дуги), начиная с корня. Для каждого просматриваемого узла сохранять в стеке перечень дочерних узлов. Если какая-либо из дочерних вершин помечена знаком операции, то просматриваемый узел пометить этим знаком и удалить из дерева дочернюю вершину, но только в том случае, если она является листом. Если после обработки очередного узла стек не пуст, то перейти к обработке узла, номер которого снимается с верхушки стека. Если же стек опустел, то повторять шаг 2 до тех пор, пока состояние дерева не перестанет изменяться.
Шаг 3. Для каждого листа, помеченного операндом, проверить пометку родительского узла. В том случае если родительский узел помечен нетерминалом, перенести в него наименование операнда из дочернего листа и удалить этот лист. Продолжать выполнение шага 3 до тех пор, пока состояние дерева не перестанет изменяться.
Если применить эту процедуру к приведенному выше дереву разбора,
то будет получено именно такое дерево операций, которое приведено на
рис. ?, а.
Для данной грамматики применение этой процедуры позволит получить желаемый результат из дерева разбора любого оператора присваивания. Объясняется это тем, что вся семантика, определяющая последовательность выполнения операций сложения, вычитания и присваивания, а также изменение порядка их выполнения при использовании скобок в любом выражении неявным образом заложена в совокупность порождающих правил, описывающих синтаксис языка операторов присваивания.
Из дерева операций легко можно получить постфиксную форму записи линейной последовательности знаков операций (с их операндами) такую, в которой порядок появления операций совпадает с требуемым порядком их выполнения.
Процедура преобразования дерева операций в постфиксную форму записи является рекурсивной и может быть определена следующим образом.
Шаг 1. Взять корень дерева операций в качестве текущей вершины.
Шаг 2. Если текущая вершина не является листом, перейти к шагу 3, иначе выдать ее пометку (наименование операнда) на выход и завершить обход поддерева.
Шаг 3. Обойти левое поддерево данного корня (рекурсивно вызвать шаг 2 процедуры для корня левого поддерева текущей вершины).
Шаг 4. Обойти правое поддерево данного корня (рекурсивно вызвать шаг 2 процедуры для корня правого поддерева текущей вершины).
Шаг 5. Выдать пометку текущей вершины (знак операции) на выход. Завершить обход поддерева.
Применение этой процедуры к дереву операций, построенному нами для оператора присваивания a=b*c+d;,позволит получить такую постфиксную запись:
abc * d + =
Ее смысл (семантика) состоит в следующем.
Сначала должна быть выполнена операция умножения значений bи c, наименования которых записаны перед знаком *. Можно считать, что в результате выполнения операции умножения получено промежуточное значение, которое мы обозначим через r, а исходная ПФЗ превратилась в такую: