Файл: Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214.docx
Добавлен: 12.01.2024
Просмотров: 615
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Основные требования к отчетам по лабораторным работам
Лабораторная/практическая работа № 1
Лабораторная/практическая работа № 2
Лабораторная/практическая работа № 3
Лабораторная/практическая работа № 4
Лабораторная/практическая работа № 5
Лабораторная/практическая работа № 6
Лабораторная/практическая работа № 7
Исторически понятие нелокальных объектов появилось в языке Algol и связано с впервые введенной в этом языке конструкцией блоков. Блок представляет собой последовательность инструкций, содержащую объявления собственных локальных данных. Основная отличительная особенность понятия блока заключается во вложенности структуры. Блоки либо следуют друг за другом, либо один блок является полностью вложенным в другой. Невозможно такое перекрытие блоков В1 и В2, при котором первым по тексту начинается блок В1, после чего начинается блок В2, затем заканчивается блок В1, а затем – В2.
Начало и конец блока оформляются специальными ограничителями (в С для этой цели используются фигурные скобки { и }; в Algol и Pascal – ключевые слова begin и end).
-
Блочные области видимости
Область видимости любого объекта в языке с блочной структурой определяется правилом ближайшего вложенного, суть которого состоит в следующем:
-
Область видимости объявления в блоке В включает весь блок В. -
Если объект х не объявлен в блоке В, то все появления имени х в В находятся в области видимости объявления х во внешнем окружающем блоке Во, таком, что:
-
Во содержит объявление объекта с именем х; -
Во является ближайшим окружающим В блоком среди всех, содержащих объявление х.
Для пояснения того, как действует правило ближайшего вложенного, приведем следующий фрагмент программы на языке С (рис. 8.14). В нем каждое объявление инициализирует объявляемый объект числом, равным номеру блока, в котором оно появляется. Обратим внимание на то, что область видимости целой переменной b, объявленной в блоке В0, не включает блока В1, поскольку в блоке В1 объявлена другая переменная с тем же именем b. Такой разрыв называется «дырой» в области видимости объявления.
main()
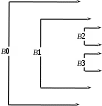 {int a=0;
{int a=0;int b=0;
{int b=1;
{int a=2;
printf(“a=%d b=%d\n”,a,b);
}
{int b=3;
printf(“a=%d b=%d\n”,a,b);
}
printf(“a=%d b=%d\n”,a,b);
}
printf(“a=%d b=%d\n”,a,b);
}
Рис. 8.14. Блоки и видимость переменных в С-программе
Всего в этом тексте объявлено пять разных объектов, области видимости которых приведены в табл. 8.2:

Таблица 8.2
| Объявление | Область видимости |
| int a = 0; | B0, B2 |
| int b = 0; | B0, B1 |
| int b = 1; | B1, B3 |
| int a = 2; | B2 |
| int b = 3; | B3 |
Результаты работы этой программы иллюстрируют правило «ближайшего вложенного». При ее исполнении управление передается внутрь блока из точки, находящейся непосредственно перед ним, а затем из блока возвращается в точку, следующую прямо за ним в исходном тексте. Инструкции печати выполняются в последовательности В2, В3, В1 и В0 (в порядке, в котором завершается исполнение блоков). Значения переменных а и b в этих блоках показаны в табл. 8.3.

Таблица 8.3
| Блок | a | b |
| B2 | 2 | 1 |
| B3 | 0 | 3 |
| B1 | 0 | 1 |
| B0 | 0 | 0 |
Блочная структура программы может быть реализована с использованием стекового распределения памяти. Поскольку область видимости объявления не выходит за пределы того блока, в котором оно записано, память для объявленного объекта может быть выделена при входе в блок и освобождена при выходе из него. Это эквивалентно использованию блока как «процедуры/функции без параметров», вызываемой только из одной точки непосредственно перед блоком и возвращающей управление в точку непосредственно за блоком.
Нелокальная среда ссылок для блока может поддерживаться с использованием технологий для функций, которые будут рассмотрены в этой главе ниже. Заметим, что с точки зрения разработчика транслятора реализация блоков несколько проще, чем реализация функций, поскольку блокам не передаются параметры, а поток управления строго следует статическому тексту программы (не осуществляются передачи управления).
Другая возможная реализация программ с блочной структурой состоит в однократном выделении памяти для всех локальных объектов функции в тот момент, когда ей передается управление. При наличии блоков в функции размер поля локальных данных ее записи активации рассчитывается транслятором с учетом всех объявлений внутри блоков.
Для переменных программы, приведенной на рис. 8.14, можно выделить память так, как показано на рис. 8.15. Индексы у локальных переменных а и b на этом рисунке соответствуют блоку, в котором они объявлены.
| … | а0 | b0 | b1 | а2, b3 | … |
Рис. 8.15. Локальные объекты в записи активации
Заметим, что для объектов a2 и b3 может быть отведена одна и та же область памяти, поскольку блоки B2 и B3 не пересекаются.
При отсутствии динамических массивов (и других данных переменной длины) максимальное количество памяти, необходимой для выполнения блока, может быть определено в процессе компиляции (с данными переменной длины можно работать, используя указатели). Определение этого размера транслятор должен выполнять исходя из предположения, что при исполнении программы будут пройдены все возможные пути управления по тексту функции.
-
Текстуальная область видимости без вложенных функций
Для изучения того, каким образом реализуется видимость нелокальных объектов в языке, не допускающем текстуально вложенных функций, рассмотрим программу сортировки элементов массива на языке С (рис. 8.16).
Эта программа предназначена для демонстрационных целей, ее не следует (как и приведенную ниже программу на языке Pascal) рассматривать в качестве образца программирования или реализации методов сортировки. Правила текстуальной области видимости в языке С проще, чем в языке Pascal (для языка Pascal они обсуждаются позже) вследствие того, что определение функции не может находиться внутри другой функции.
Если в некоторой функции используется не объявленный в ней объект X, то предполагается, что его объявление находится вне любой функции. Область видимости любого такого объявления состоит из тел функций, следующих за ним (объявлением) по тексту файла (с дырами, если внутри функций имеются объявления объектов с точно такими же именами).
-
int arr[ ]; -
void ReadArray(void) { ... аrr ... } -
int PartExch(int iBeg,int iEnd) { -
int i, j, k, mVal; -
i=iBeg; j=iEnd; mVal=arr[i+(j-i)/2]; -
while(i
for( ;arr[i]
for( ;arr[j]>mVal;j-=1);
if(i
} //end while
return i;
} //end PartExch
void QuickSort(int iBeg,int iEnd) {
int iMid;
if(iBeg
iMid=PartExch(iBeg,iEnd);
if(iBeg
if(iMid+1
}
} //end QuickSort
void main() {
ReadArray();QuickSort(0,(sizeof(arr)/sizeof(int))-1);
} //end main
Рис. 8.16. С-программа с нелокальным массивом arr
При отсутствии вложенных функций для языка с текстуальными областями видимости можно использовать стратегию стекового распределения памяти для локальных объектов. Память для объектов, объявленных вне функций, может быть выделена статически. Положение этой памяти известно в процессе компиляции, так что даже если некоторый объект нелокален в теле данной функции, транслятор будет использовать статически определенный адрес объекта для построения команд, оперирующих с его значением.
Важное преимущество статического выделения памяти для нелокальных объектов заключается в том, что любые функции могут свободно передаваться в качестве параметра другим функциям и возвращаться как результат вызова (в языке С функция передается как параметр путем передачи указателя на нее). При использовании текстуальной области видимости и отсутствии вложенных функций любой нелокальный для одной функции объект является нелокальным и для всех остальных функций, а следовательно, его статический адрес может использоваться всеми функциями одинаково и независимо от того, каким образом они активируются. Это справедливо для любой функции, в том числе и для функций, которые вызываются по вычисляемым ссылкам.
Доступ к другим элементам среды ссылок следует изучить по [6-9].
-
Порядок выполнения работы (рекомендуется использовать в качестве примера систему правил Samples/Sample8):
-
Расширить систему действий синтаксического анализатора, построенного при выполнении лабораторных работ 3 – 7, действиями для исполнения последовательности тетрад (триад/пентад согласно варианту задания на курсовую работу); -
Обеспечить выполнение некоторых семантических проверок для выявления ошибок времени исполнения при интерпретации; -
Построить интерпретатор (виртуальную машину) для учебного языка или его подмножества, убедиться в его работоспособности. -
Подготовить, сдать и защитить отчет к лабораторной работе.
-
Требования к содержанию отчета.
Отчет должен содержать:
-
цель работы; -
краткое изложение задач, возникающих при интерпретации псевдокода; -
описание структур данных и алгоритмов совокупности действий, разработанных для реализации виртуальной машины для заданного варианта учебного языка; -
выводы и заключение.
-
Контрольные вопросы
-
Что такое побочный эффект вызова процедуры/функции? -
Что такое глобальный, локальный и нелокальный объект? -
Что такое текстуальная область видимости без вложенных функций? -
Что такое передача аргумента по имени? Как она реализуется? -
Перечислите способы передачи аргументов в функцию. -
Что такое жизненный цикл наименования объекта? -
Что такое кодированное представление типов данных? В чем состоят его достоинства и недостатки? -
Что такое вложенность процедур/функций? -
Что такое нелокальная среда ссылок?
-
Расшифруйте словами тип данных языка С:
(int*[](unsigned)).
-
Что такое именное представление типов данных? В чем состоят его достоинства и недостатки? -
Что такое передача аргументов методом копирование-восстановление? -
Что такое запись активации процедуры/функции? -
Как делится ответственность за формирование записи активации между вызывающей и вызываемой функциями? -
Что такое дерево активации функций? -
Перечислите минимально необходимые поля записи активации функции. -
Что такое блочная область видимости переменной? -
Что такое вызывающая последовательность? -
Что такое l-value и r-value?
Литература
-
Малявко А.А. Формальные языки и компиляторы: учебное пособие для вузов. – М., Изд-во Юрайт, 2021 -
Малявко А.А. Формальные языки и компиляторы: учебник НГТУ. – Изд-во НГТУ, 2014, 004 М219, Id = 000184529 -
Малявко А.А. Системное программное обеспечение. Формальные языки и методы трансляции: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2010. – Ч.1, 004 M 219, Id = 143812 -
Малявко А.А. Системное программное обеспечение. Формальные языки и методы трансляции: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2011. – Ч.2, 004 M 219, Id=155235 -
Малявко А.А. Системное программное обеспечение. Формальные языки и методы трансляции: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2012. – Ч.3, 004 M 219, Id=170641 -
Ахо А., Сети Р., Ульман Д. Компиляторы: принципы, технологии и инструменты. – М.: «Вильямс», 2001, Id=16803 -
Карпов Ю.Г. Теория и технология программирования. Основы построения трансляторов: учеб. пособие. – СПб.: БХВ-Петербург, 2005, Id=64347 -
Свердлов С. З. Языки программирования и методы трансляции: учебное пособие для вузов - СПб., 2007, Id=65534 -
Гавриков М.М., ИванченкоА.Н., Гринченков Д.В. Теоретические основы разработки и реализации языков программирования. – М.: Кнорус, 2010.