Файл: Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214.docx
Добавлен: 12.01.2024
Просмотров: 623
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Основные требования к отчетам по лабораторным работам
Лабораторная/практическая работа № 1
Лабораторная/практическая работа № 2
Лабораторная/практическая работа № 3
Лабораторная/практическая работа № 4
Лабораторная/практическая работа № 5
Лабораторная/практическая работа № 6
Лабораторная/практическая работа № 7

Команды функции | |
… Запись активации |
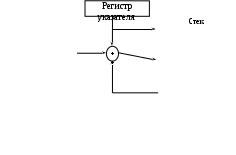
Рис. 8.10. Формирование исполнительного адреса, объект внутри поля локальных данных
Для обеспечения этого транслятор формирует и помещает в точку входа в функцию дополнительные команды. Доступ к значению любого локального объекта осуществляется по адресу, вычисляемому как сумма базового адреса записи активации (из регистра процессора, специально выделяемого для этой цели) со смещением (из команды). Если стек растет в направлении увеличения адресов памяти, то все значения смещений будут отрицательными. Для ситуации, представленной на рис. 8.10, предполагается, что стек растет в сторону уменьшения адресов памяти, поэтому значения смещений положительны. Кажущаяся примитивность процесса формирования смещений локальных объектов осложняется двумя обстоятельствами. Первое состоит в том, что на компоновку памяти для объектов данных сильное влияние оказывают ограничения системы адресации целевого компьютера и/или требования оптимизации по времени выполнения. Пусть, например, выборка данных из памяти выполняется четырехбайтными кадрами, адрес первого из которых должен быть кратен четырем. В таком случае для доступа к двухбайтному целому значению может потребоваться два обращения к памяти, если его адрес нечетен. Такой случай возможен, если транслятор экономно использует память и размещает данные слитно. Если же при трансляции преследуется цель построения быстрой программы, то определение размера памяти, отводимой под каждый объект, должно производиться с учетом оптимального выравнивания адреса его первого байта.
Второе усложняющее обстоятельство ранее уже упоминалось: если в функции в качестве локального объявлен динамический массив, у которого хотя бы одна граница изменения индекса зависит от значений фактических параметров, то во время трансляции размер этого массива определить невозможно. Следовательно, до момента вызова функции невозможно определить размер записи активации. Существует по меньшей мере два способа преодоления этой трудности. Независимо от того, какой способ применяется, в точку входа в функцию неявно для программиста транслятор добавляет инструкции, вычисляющие для каждого такого массива требуемый размер памяти.
-
 При первом способе (см. рис. 8.11) окончательное определение размера поля локальных данных и размера всей записи активации откладывается до момента входа в функцию.
При первом способе (см. рис. 8.11) окончательное определение размера поля локальных данных и размера всей записи активации откладывается до момента входа в функцию.
Рис. 8.11. Формирование исполнительного адреса, элемент динамического массива внутри поля локальных данных
Ясно, что адреса всех таких массивов, кроме первого из них, не могут быть зафиксированы во время трансляции. Следовательно, машинные команды, оперирующие с элементами второго и всех последующих массивов, не могут быть построены тем же способом, что и команды, работающие с обычными локальными данными. Вызвано это тем, что для формирования исполнительного адреса элемента массива теперь приходится складывать три величины:
-
базовый адрес записи активации; -
смещение первого элемента динамического массива внутри записи активации (вычисляется после входа в функцию и хранится в качестве локального объекта, построенного транслятором); -
смещение элемента массива (берется из команды либо вычисляется до ее выполнения, если транслятору неизвестны индексы этого элемента).
Второй способ, показанный на рис. 8.12, состоит в том, что память для динамических массивов не резервируется в записи активации, а выделяется из кучи после того, как вычислен требуемый размер массива.

Рис. 8.12. Формирование исполнительного адреса, память для динамического массива выделяется из кучи
В записи активации во время трансляции резервируется фиксированное количество байт памяти для хранения указателя на память, взятую из кучи. Указатель используется в командах, оперирующих с элементами массива, которые строятся транслятором не так, как команды, работающие с обычными локальными данными (в том числе массивами). Адрес памяти для доступа к элементу динамического массива при хранении его в куче вычисляется так:
-
вначале известное транслятору смещение указателя массива складывается с адресом записи активации и используется для выборки адреса массива и помещения его в регистр процессора; -
затем значение этого регистра складывается со смещением нужного элемента массива и по полученному адресу извлекается операнд.
Главным достоинством использования кучи для хранения динамических массивов является вычисление размера записи активации во время трансляции, а не во время исполнения программы.
-
Вызывающие последовательности
Вызовы функций реализуются путем исполнения так называемых вызывающих последовательностей команд. Эти последовательности размещаются частично в вызывающей, частично в вызываемой функции. Они обеспечивают передачу управления и данных из вызывающей функции в вызываемую (последовательность вызова), и наоборот – из вызываемой в вызывающую (последовательность возврата). Последовательность вызова создает запись активации и заполняет ее поля необходимой информацией. Последовательность возврата восстанавливает состояние машины таким образом, чтобы вызывающая функция могла продолжать исполнение.
Последовательности вызовов и структура записи активации различаются даже в разных реализациях одного и того же языка. Коды в последовательностях вызова и возврата зачастую разделяются между вызывающей и вызываемой функциями. Не существует однозначного разграничения задач между вызывающей и вызываемой функциями – исходный язык, целевая машина и операционная система налагают свои требования, в силу которых может оказаться предпочтительным то или иное решение.
Поскольку каждый вызов имеет собственные фактические параметры, вызывающая функция обычно вычисляет фактические параметры и передает их в запись активации вызываемой функции. В стеке времени исполнения запись активации вызывающей функции находится непосредственно под записью активации вызываемой функции, как показано на рис. 8.13. Размещение полей параметров и возможного возвращаемого значения вслед за записью активации вызывающей функции дает некоторый выигрыш за счет того что вызывающая функция может получить доступ к таким полям, используя только смещения от конца собственной записи активации. Для этого не нужна полная информация о компоновке записи активации вызываемой функции. В частности, при трансляции вызывающей функции, как правило, ничего не известно о локальных переменных вызываемой функции.
Несмотря на то что размер поля для временных значений в конечном счете фиксируется во время компиляции, он может быть неизвестен вплоть до окончания этапов оптимизации и первой фазы генерации объектного кода. На этих этапах количество временных переменных для хранения промежуточных значений может быть уменьшено, а следовательно, на этапе семантического анализа размер этого поля может быть неизвестен. Поэтому поле временных переменных лучше размещать после поля локальных данных, поскольку изменения его размера не будут влиять на смещение прочих локальных объектов.
Если вызов функции встречается в тексте программы n раз, то часть последовательности вызова в вызывающих функциях будет построена транслятором n раз, в то время как часть последовательности вызова в вызываемой функции генерируется лишь единожды. Следовательно, для экономии памяти желательно разместить как можно большую часть последовательности вызова в коде вызываемой функции. Однако, очевидно, не всю работу по организации вызова можно переложить на вызываемую функцию.
Для выполнения всей работы необходимы два регистра процессора: указатель стека и указатель текущей записи активации.
Указатель стека (УС) в любой момент времени разделяет занятое и свободное пространства в стеке и используется всегда для доступа к единственному объекту, находящемуся на верхушке стека. Он не может быть использован для доступа к любым другим объектам в силу того, что значение этого указателя постоянно изменяется в результате выполнения различных команд. Поэтому для хранения базового адреса записи активации, как правило, выделяется еще один регистр процессора – указатель записи активации (УЗ). С использованием двух регистров типичная последовательность действий по вызову функции выглядит так.
Перед началом процесса вызова регистр УЗ указывает на конец поля состояния машины в записи активации.
-
Вызывающая функция вычисляет фактические параметры и заносит их в стек, модифицируя УС. -
Вызывающая функция сохраняет адрес возврата и старое значение УЗ в записи активации вызываемой функции, после чего устанавливает значение УЗ равным значению УС, как показано на рис. 8.13. Таким образом, УЗ перемещается за локальные и временные данные вызывающей функции, параметры и поле состояния машины вызываемой функции. -
Управление передается вызываемой функции, которая сохраняет в стеке значения регистров и другую информацию о состоянии машины и модифицирует УС таким образом, чтобы зарезервировать место под свои локальные данные и временные значения. -
Вызываемая функция инициализирует локальные данные и переходит к исполнению своего тела.

 Запись активации вызываемой функы Временные значения |
| Локальные данные |
| Регистры процессора |
| Связь по доступу |
| Связь по управлению |
| Фактические параметры |
| Возвращаемое значение |
| Временные значения |
| Локальные данные |
| Регистры процессора |
| Связь по доступу |
| Связь по управлению |
| Фактические параметры |
| Возвращаемое значение |
Рис. 8.13. Разделение задач между вызывающей и вызываемой функциями
Возможная последовательность возврата из функции выглядит следующим образом.
-
Вызываемая функция размещает возвращаемое значение после записи активации вызывающей программы. Используя информацию в поле состояния машины, вызываемая функция восстанавливает УЗ и другие регистры и передает управление по адресу возврата в коде вызывающей функции. -
Хотя значение УЗ было уменьшено, вызывающая функция может скопировать возвращаемое значение в собственную запись активации и использовать его в вычислениях.
Приведенные выше последовательности вызова позволяют реализовывать функции с переменным числом аргументов. Транслятор, обрабатывая вызывающую функцию, может подсчитать количество фактических параметров. Следовательно, при формировании кода вызывающей функции ему известен размер поля параметров, который может быть неявно передан тоже в виде параметра. Теперь остается только таким образом формировать код вызываемой функции, чтобы он правильно обрабатывал неизвестное при трансляции, но получаемое в момент вызова количество параметров. Другой возможный вариант способа реализации переменного количества параметров – функции типа printf в языке С. Первый параметр такой функции содержит перечень и типы остальных параметров в виде текстовой строки. Поэтому, как только код тела функции printf выбирает первый параметр, он может по нему определить способ доступа к произвольному количеству остальных параметров.
-
Доступ к нелокальным объектам
Правила области видимости языка определяют способ работы со ссылками на нелокальные объекты – такие, объявления которых находятся вне текста функции, в которой объект используется. Существует общее правило, именуемое правилом текстуальной (или статической) области видимости, согласно которому видимость любого объекта определяется исключительно расположением его объявления в тексте программы.
В языках Pascal, С и Ada и многих других используется текстуальная область видимости с добавлением правила «ближайшее вложенное».
В некоторых языках программирования используется другое правило динамической области видимости, при котором ассоциация наименования любого объекта с его объявлением определяется не текстом программы, а совокупностью имеющихся на данный момент активаций функций. Согласно этому правилу доступ к значению нелокального объекта осуществляется путем поиска его имени в таблицах, ассоциированных с активациями функций. Просмотр активаций функций должен осуществляться в заранее обусловленной последовательности. Правило динамической области видимости используется в таких языках, как Lisp, APL и Snobol.