Файл: Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214.docx
Добавлен: 12.01.2024
Просмотров: 635
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Основные требования к отчетам по лабораторным работам
Лабораторная/практическая работа № 1
Лабораторная/практическая работа № 2
Лабораторная/практическая работа № 3
Лабораторная/практическая работа № 4
Лабораторная/практическая работа № 5
Лабораторная/практическая работа № 6
Лабораторная/практическая работа № 7
Локальные данные. Здесь в течение времени жизни данной активации функции хранятся значения объектов, объявленных в ее теле. Размер этого поля, как правило, может быть вычислен во время трансляции вызываемой функции. Существуют языки программирования, в которых возможно исключение из этого правила, такие как С/С++: допускающие возможность объявления в функции локальных массивов, размеры которых зависят от значений фактических параметров. Их значения желательно размещать в регистрах процессора на время выполнения функции.
Результаты промежуточных вычислений. В том случае если в инструкциях вызываемой функции имеются сложные выражения наподобие a*b+c*d, возникает необходимость временного хранения значения произведения a*b (или c*d, или и того и другого) от момента его вычисления и, по крайней мере, до момента последнего использования. Такие данные во многом эквивалентны локальным данным функции, но не имеют никакого имени, присвоенного программистом в тексте программы. В процессе трансляции по мере необходимости образования объектов для хранения промежуточных результатов имена для них могут формироваться и использоваться семантическим анализатором и генератором объектного кода/виртуальной машиной. Как будет показано ниже, перечень и типы данных объектов, необходимых для хранения промежуточных результатов, могут быть определены транслятором в процессе преобразования постфиксной записи в последовательность тетрад/триад. Таким образом, размер этого поля тоже может быть вычислен во время трансляции вызываемой функции.
Регистры процессора. В этом поле сохраняется состояние регистров процессора, каким оно было непосредственно перед вызовом функции и, соответственно, каким должно быть сразу после возврата из нее. В частности, здесь же обычно хранится адрес возврата, поскольку он является значением одного из регистров, а именно – счетчика команд. Размер памяти, необходимой для сохранения значений регистров, определяется архитектурой компьютера и фиксируется в качестве константы на этапе разработки транслятора.
Связь по доступу. Используется для обеспечения доступа из вызываемой функции к нелокальным данным, хранящимся в другой записи активации. Размер этого поля фиксирован и равен размеру любого указательного значения.
Связь по управлению. Это поле используется для хранения указателя на запись активации вызывающей функции. Размер его фиксирован. Используется в реализациях языков, обеспечивающих не текстуальную, а динамическую видимость нелокальных объектов.
Фактические параметры. Обычно фактические параметры стремятся передавать через регистры процессора. Тем не менее всегда необходимо учитывать возможность того, что количество фактических параметров превысит доступное количество регистров, поэтому в записи активации функции для них должно предусматриваться место. Большинство языков программирования предусматривает фиксированное количество и типы значений параметров каждой функции. В этом случае размер поля фактических параметров может быть определен во время трансляции вызываемой функции. Однако существуют языки (С/С++), допускающие возможность приема вызываемой функцией заранее неопределенного количества фактических параметров. В этом случае размер поля фактических параметров может быть определен только при трансляции текста вызывающей функции.
Поле возвращаемого значения используется вызываемой функцией для возврата значения вызывающей функции. Для повышения эффективности программы это значение, как правило, возвращается в регистре. Если же для возвращаемого значения резервируется поле в записи активации, то его размер определяется типом значения и может быть легко определен во время трансляции функции.
Не во всех языках используется каждое из этих полей (и не все компиляторы с одного и того же языка делают это одинаково). В силу того что поля записи активации интенсивно используются при выполнении функции, для хранения наиболее часто используемых из них разработчики трансляторов стремятся использовать регистры процессора. За формирование полей записи активации обычно отвечают и вызывающая и вызываемая функции, но каждая – строго за определенные поля записи.
Запись активации может создаваться (здесь имеется в виду выделение памяти для нее, а не формирование значений полей) следующими способами:
Первый способ – создание записи активации в процессе трансляции – преследует цель минимизировать накладные расходы по времени на вызовы функций при исполнении программы. Типичный пример применения – язык Fortran. С каждой функцией связана в точности одна запись активации, поскольку статически невозможно создать большее, но заранее не известное количество записей активации, а создание ограниченного
, но большего единицы количества записей никак не решает проблему рекурсивности вызовов, но приводит к росту накладных расходов. При статическом создании записей активации не может быть разрешен рекурсивный вызов функций. Записи активаций функций размещаются транслятором в области статических данных (см. рис. 8.6).
Динамическое создание записей активации в куче во время исполнения программы предполагает наличие механизма управления кучей (библиотеки функций, выполняющих учет свободного пространства и обработки запросов на выделение связного блока требуемого размера и, возможно, освобождение ранее выделенного блока). Вполне вероятно, что куча будет использоваться не только для хранения записей активации, поэтому необходимо обеспечивать учет созданных записей (см. рис. 8.6, поле связи по управлению, которое в данном случае становится обязательным). Следовательно, реализация этого способа приводит к высоким накладным расходам по времени на вызовы, но обеспечивает наибольшую гибкость во взаимодействии вызывающих и вызываемых функций. В частности, при этом способе время жизни активации вызываемой функции в принципе может быть дольше, чем время жизни вызывающей ее активации (см. ниже). Возможна также реализация таких экзотических возможностей, как, например, сопрограммы.
Средняя между предыдущими способами величина накладных расходов в сочетании с наиболее естественной текстуальной видимостью нелокальных данных обеспечивается при динамическом создании записей активации в стеке исполняемой программы. Аппаратная реализация стека минимизирует накладные расходы по времени на выделение памяти для записей активации вызываемых функций. Рекурсивные вызовы функций допускаются, при этом количество записей активации одной и той же функции может быть сколь угодно большим, и ограничиваться только размером области памяти, отведенной под стек программы.
При создании записей активации функций в стеке последовательность их уничтожения обратна последовательности образования. Поэтому время жизни активации любой функции не может быть больше времени жизни активации вызывающей функции. Другими словами, две произвольные активации любых функций (возможно, одной функции) либо не пересекаются во времени, либо одна из них полностью вложена в другую. На рис. 8.7 показано перемещение потока управления между активациями двух функций во времени.
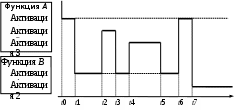
Внизу сплошной линией со стрелкой обозначена ось времени. Сплошные вертикальные линии показывают либо вызовы функций, либо возвраты из них. Жирными горизонтальными линиями показаны процессы исполнения соответствующих активаций функций. Пунктирными горизонтальными линиями для некоторых активаций выделены интервалы, когда активации существуют, но не исполняются, поскольку в это время процессор занят исполнением другой активации либо той же самой функции (интервалы t2 – t3 и t4 – t5 для активации 1 функции А), либо другой функции (интервалы t1 –t2,
t3 –t4, t5 –t6 и t6 –… для активации 1 функции А, t2 –t3 и t4 –t5 для активации 1 функции В).
Рис. 8.7. Времена жизни активаций функций
Согласно дисциплине существования элементов стека после создания, к примеру, активации 2 функции А и до ее завершения не может завершиться существование ни активации 1 функции В, ни активации 1 функции А. Заметим, что и то и другое событие в принципе возможно при динамическом создании записей активаций функций в куче. Для реализации этих событий нужно просто обеспечивать явное уничтожение записей ненужных активаций и возвраты по адресам, предварительно взятым из них.
На рис. 8.8. показана последовательность состояний стека программы, соответствующая моментам времени t0, … t7. Записи активаций обозначены буквенным названием функции (А или В) и порядковым номером активации.
Для изображения того, как управление передается активациям и покидает их, может оказаться полезным так называемое дерево активаций. Это графическое представление процесса исполнения совокупности функций, для которого выполняются следующие условия:
Рис. 8.8. Последовательность состояний стека программы
Поскольку каждый узел представляет единственную активацию, и наоборот, удобно говорить о том, что управление находится в узле, когда оно находится в активации, представленной этим узлом. Если пометить каждый узел дерева именем (обозначением) функции и порядковым (во времени) номером ее активации, то все узлы дерева будут иметь уникальные пометки. Фрагмент дерева активаций для случая, изображенного на рис. 8.7, может выглядеть так, как показано на рис. 8.9.
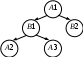
Рис. 8.9. Фрагмент дерева активаций
Последовательность событий создания/уничтожения активаций функций может быть получена путем обхода дерева, начинающегося с корня и заключающегося в последовательном посещении всех поддеревьев каждой вершины строго слева направо. Размещение записей активации функций в стеке исполняемой программы наиболее часто используется в реализациях языков программирования общего назначения.
Независимо от того, где хранятся записи активации в процессе исполнения программы, для любой из них должен быть отведен связный блок памяти такого размера, чтобы в нем размещались все поля записи. Другими словами – к моменту фактического выделения блока памяти под запись активации необходимо точно знать его требуемый размер, который равняется сумме размеров всех полей. Рассмотрим, каким образом определяются размеры полей локальных данных. Способы формирования полей промежуточных вычислений и фактических параметров будут рассмотрены позже. Остальные поля записи активации, как уже упоминалось, имеют фиксированные размеры.
Для определения размера поля локальных данных транслятор должен разметить (распределить) его образ памяти. Для каждой функции этот процесс начинается с фиксации начального адреса образа памяти поля локальных данных, обычно равного сумме размеров всех предшествующих полей записи активации. Далее последовательно перебираются наименования объектов, ассоциации которых должны быть активными при исполнении инструкций функции. Текущее значение адреса первого свободного элемента (обычно – байта) памяти заносится в соответствующую объекту запись таблицы ассоциаций (обычно это просто таблица идентификаторов), из этой записи извлекается тип объекта, по нему определяется требуемое количество байт памяти и на это количество увеличивается счетчик занятых байт (т.е. указатель первого свободного байта). При генерации объектного кода сформированный таким образом адрес объекта будет использован в качестве смещения в любой команде, оперирующей с этим объектом. При исполнении программы в момент вызова функции адрес записи активации будет занесен в строго определенный регистр процессора (если записи активации размещаются в стеке, то для доступа к ним может использоваться указатель стека).
Результаты промежуточных вычислений. В том случае если в инструкциях вызываемой функции имеются сложные выражения наподобие a*b+c*d, возникает необходимость временного хранения значения произведения a*b (или c*d, или и того и другого) от момента его вычисления и, по крайней мере, до момента последнего использования. Такие данные во многом эквивалентны локальным данным функции, но не имеют никакого имени, присвоенного программистом в тексте программы. В процессе трансляции по мере необходимости образования объектов для хранения промежуточных результатов имена для них могут формироваться и использоваться семантическим анализатором и генератором объектного кода/виртуальной машиной. Как будет показано ниже, перечень и типы данных объектов, необходимых для хранения промежуточных результатов, могут быть определены транслятором в процессе преобразования постфиксной записи в последовательность тетрад/триад. Таким образом, размер этого поля тоже может быть вычислен во время трансляции вызываемой функции.
Регистры процессора. В этом поле сохраняется состояние регистров процессора, каким оно было непосредственно перед вызовом функции и, соответственно, каким должно быть сразу после возврата из нее. В частности, здесь же обычно хранится адрес возврата, поскольку он является значением одного из регистров, а именно – счетчика команд. Размер памяти, необходимой для сохранения значений регистров, определяется архитектурой компьютера и фиксируется в качестве константы на этапе разработки транслятора.
Связь по доступу. Используется для обеспечения доступа из вызываемой функции к нелокальным данным, хранящимся в другой записи активации. Размер этого поля фиксирован и равен размеру любого указательного значения.
Связь по управлению. Это поле используется для хранения указателя на запись активации вызывающей функции. Размер его фиксирован. Используется в реализациях языков, обеспечивающих не текстуальную, а динамическую видимость нелокальных объектов.
Фактические параметры. Обычно фактические параметры стремятся передавать через регистры процессора. Тем не менее всегда необходимо учитывать возможность того, что количество фактических параметров превысит доступное количество регистров, поэтому в записи активации функции для них должно предусматриваться место. Большинство языков программирования предусматривает фиксированное количество и типы значений параметров каждой функции. В этом случае размер поля фактических параметров может быть определен во время трансляции вызываемой функции. Однако существуют языки (С/С++), допускающие возможность приема вызываемой функцией заранее неопределенного количества фактических параметров. В этом случае размер поля фактических параметров может быть определен только при трансляции текста вызывающей функции.
Поле возвращаемого значения используется вызываемой функцией для возврата значения вызывающей функции. Для повышения эффективности программы это значение, как правило, возвращается в регистре. Если же для возвращаемого значения резервируется поле в записи активации, то его размер определяется типом значения и может быть легко определен во время трансляции функции.
Не во всех языках используется каждое из этих полей (и не все компиляторы с одного и того же языка делают это одинаково). В силу того что поля записи активации интенсивно используются при выполнении функции, для хранения наиболее часто используемых из них разработчики трансляторов стремятся использовать регистры процессора. За формирование полей записи активации обычно отвечают и вызывающая и вызываемая функции, но каждая – строго за определенные поля записи.
Запись активации может создаваться (здесь имеется в виду выделение памяти для нее, а не формирование значений полей) следующими способами:
-
статически при трансляции функции; -
динамически в куче; -
динамически в стеке времени исполнения программы.
Первый способ – создание записи активации в процессе трансляции – преследует цель минимизировать накладные расходы по времени на вызовы функций при исполнении программы. Типичный пример применения – язык Fortran. С каждой функцией связана в точности одна запись активации, поскольку статически невозможно создать большее, но заранее не известное количество записей активации, а создание ограниченного
, но большего единицы количества записей никак не решает проблему рекурсивности вызовов, но приводит к росту накладных расходов. При статическом создании записей активации не может быть разрешен рекурсивный вызов функций. Записи активаций функций размещаются транслятором в области статических данных (см. рис. 8.6).
Динамическое создание записей активации в куче во время исполнения программы предполагает наличие механизма управления кучей (библиотеки функций, выполняющих учет свободного пространства и обработки запросов на выделение связного блока требуемого размера и, возможно, освобождение ранее выделенного блока). Вполне вероятно, что куча будет использоваться не только для хранения записей активации, поэтому необходимо обеспечивать учет созданных записей (см. рис. 8.6, поле связи по управлению, которое в данном случае становится обязательным). Следовательно, реализация этого способа приводит к высоким накладным расходам по времени на вызовы, но обеспечивает наибольшую гибкость во взаимодействии вызывающих и вызываемых функций. В частности, при этом способе время жизни активации вызываемой функции в принципе может быть дольше, чем время жизни вызывающей ее активации (см. ниже). Возможна также реализация таких экзотических возможностей, как, например, сопрограммы.
Средняя между предыдущими способами величина накладных расходов в сочетании с наиболее естественной текстуальной видимостью нелокальных данных обеспечивается при динамическом создании записей активации в стеке исполняемой программы. Аппаратная реализация стека минимизирует накладные расходы по времени на выделение памяти для записей активации вызываемых функций. Рекурсивные вызовы функций допускаются, при этом количество записей активации одной и той же функции может быть сколь угодно большим, и ограничиваться только размером области памяти, отведенной под стек программы.
При создании записей активации функций в стеке последовательность их уничтожения обратна последовательности образования. Поэтому время жизни активации любой функции не может быть больше времени жизни активации вызывающей функции. Другими словами, две произвольные активации любых функций (возможно, одной функции) либо не пересекаются во времени, либо одна из них полностью вложена в другую. На рис. 8.7 показано перемещение потока управления между активациями двух функций во времени.
Внизу сплошной линией со стрелкой обозначена ось времени. Сплошные вертикальные линии показывают либо вызовы функций, либо возвраты из них. Жирными горизонтальными линиями показаны процессы исполнения соответствующих активаций функций. Пунктирными горизонтальными линиями для некоторых активаций выделены интервалы, когда активации существуют, но не исполняются, поскольку в это время процессор занят исполнением другой активации либо той же самой функции (интервалы t2 – t3 и t4 – t5 для активации 1 функции А), либо другой функции (интервалы t1 –t2,
t3 –t4, t5 –t6 и t6 –… для активации 1 функции А, t2 –t3 и t4 –t5 для активации 1 функции В).
Рис. 8.7. Времена жизни активаций функций
Согласно дисциплине существования элементов стека после создания, к примеру, активации 2 функции А и до ее завершения не может завершиться существование ни активации 1 функции В, ни активации 1 функции А. Заметим, что и то и другое событие в принципе возможно при динамическом создании записей активаций функций в куче. Для реализации этих событий нужно просто обеспечивать явное уничтожение записей ненужных активаций и возвраты по адресам, предварительно взятым из них.
На рис. 8.8. показана последовательность состояний стека программы, соответствующая моментам времени t0, … t7. Записи активаций обозначены буквенным названием функции (А или В) и порядковым номером активации.
Для изображения того, как управление передается активациям и покидает их, может оказаться полезным так называемое дерево активаций. Это графическое представление процесса исполнения совокупности функций, для которого выполняются следующие условия:
t0 |
t1 |
t2 |
t3 |
t4 |
t5 |
t6 |
t7 |
Рис. 8.8. Последовательность состояний стека программы
-
Корень дерева представляет активацию основной программы. -
Каждый узел представляет активацию функции. -
Узел А является родительским для узла В тогда и только тогда, когда поток управления передается из активации А в активацию В (узел В называется потомком узла А). -
Если два узла В и С являются потомками одного и того же узла, то узел В располагается слева от узла С тогда и только тогда, когда время жизни активации В начинается раньше времени жизни активации С.
Поскольку каждый узел представляет единственную активацию, и наоборот, удобно говорить о том, что управление находится в узле, когда оно находится в активации, представленной этим узлом. Если пометить каждый узел дерева именем (обозначением) функции и порядковым (во времени) номером ее активации, то все узлы дерева будут иметь уникальные пометки. Фрагмент дерева активаций для случая, изображенного на рис. 8.7, может выглядеть так, как показано на рис. 8.9.
Рис. 8.9. Фрагмент дерева активаций
Последовательность событий создания/уничтожения активаций функций может быть получена путем обхода дерева, начинающегося с корня и заключающегося в последовательном посещении всех поддеревьев каждой вершины строго слева направо. Размещение записей активации функций в стеке исполняемой программы наиболее часто используется в реализациях языков программирования общего назначения.
Независимо от того, где хранятся записи активации в процессе исполнения программы, для любой из них должен быть отведен связный блок памяти такого размера, чтобы в нем размещались все поля записи. Другими словами – к моменту фактического выделения блока памяти под запись активации необходимо точно знать его требуемый размер, который равняется сумме размеров всех полей. Рассмотрим, каким образом определяются размеры полей локальных данных. Способы формирования полей промежуточных вычислений и фактических параметров будут рассмотрены позже. Остальные поля записи активации, как уже упоминалось, имеют фиксированные размеры.
-
Локальные данные функций
Для определения размера поля локальных данных транслятор должен разметить (распределить) его образ памяти. Для каждой функции этот процесс начинается с фиксации начального адреса образа памяти поля локальных данных, обычно равного сумме размеров всех предшествующих полей записи активации. Далее последовательно перебираются наименования объектов, ассоциации которых должны быть активными при исполнении инструкций функции. Текущее значение адреса первого свободного элемента (обычно – байта) памяти заносится в соответствующую объекту запись таблицы ассоциаций (обычно это просто таблица идентификаторов), из этой записи извлекается тип объекта, по нему определяется требуемое количество байт памяти и на это количество увеличивается счетчик занятых байт (т.е. указатель первого свободного байта). При генерации объектного кода сформированный таким образом адрес объекта будет использован в качестве смещения в любой команде, оперирующей с этим объектом. При исполнении программы в момент вызова функции адрес записи активации будет занесен в строго определенный регистр процессора (если записи активации размещаются в стеке, то для доступа к ним может использоваться указатель стека).