Файл: Отчеты оформляются в виде файлов формата Microsoft Word (файлы других форматов не принимаются), размер шрифта 1214.docx
Добавлен: 12.01.2024
Просмотров: 641
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Основные требования к отчетам по лабораторным работам
Лабораторная/практическая работа № 1
Лабораторная/практическая работа № 2
Лабораторная/практическая работа № 3
Лабораторная/практическая работа № 4
Лабораторная/практическая работа № 5
Лабораторная/практическая работа № 6
Лабораторная/практическая работа № 7
LL(1)-грамматик. Левую рекурсию всегда можно преобразовать в правую или в общую. Однако это преобразование не гарантирует перехода грамматики в класс LL(1), потому что не только свойство левой рекурсии может быть причиной непригодности грамматики для построения нисходящего синтаксического акцептора. В общем случае задача нахождения LL(1)-грамматики, эквивалентной заданной грамматике, алгоритмически неразрешима.
Алгоритм нисходящего восстановления дерева грамматического разбора, сформулированный выше, в принципе может быть использован с любой LL(1)-грамматикой, но применение его на практике потребует уточнения ряда деталей, в том числе способа поиска правила, способа представления и хранения узлов дерева и т.д. Такая детализация может привести к радикальному изменению внешнего вида алгоритма при сохранении его сути.
Реализация общего алгоритма для конкретной грамматики обычно сводится к построению специального алгоритма, определяемого совокупностью порождающих правил, или к преобразованию грамматики в управляющую таблицу конечного автомата. Методы построения специальных алгоритмов или управляющих таблиц по грамматике легко формализуются. Следовательно, если заданная грамматика принадлежит классу LL(1)-грамматик, то построение нисходящего синтаксического акцептора предложений порождаемого ею языка может быть автоматизировано.
Существует несколько вариантов реализации общего алгоритма и методов соответствующего преобразования грамматики. Пакет ВебТрансБилдер для каждого инструментального языка содержит набор шаблонов преобразования грамматики в код программы транслятора. Для построения нисходящих синтаксических анализаторов (парсеров) существуют шаблоны, формирующие:
-
парсер, как нисходящий стековый автомат с одним состоянием;
-
парсер, как нисходящий стековый автомат с несколькими состояниями;
-
парсер, как совокупность функций.
-
Построение парсера, как нисходящего стекового автомата с одним состоянием.
Поведение нисходящего стекового автомата с одним состоянием определяется управляющей таблицей, столбцы которой соответствуют входным символам, строки – символам, которые могут находиться в стеке, а в клетках содержится последовательность операций над стеком, входной цепочкой символов и состоянием автомата.
Обычные для стековой памяти операции будут обозначаться так:
! X – занесение символа (или цепочки) символов X в стек (аналог операции push), при этом первый символ цепочки окажется в стеке под всеми остальными, последний символ окажется на самом верху стека;
^ – снятие одного символа с верхушки стека (аналог операции pop). Заметим, что попытка выполнения этой операции при пустом стеке должна приводить к останову автомата по обнаружению ошибки во входной цепочке.
Над входным потоком определена единственная операция, которую будем обозначать так:
> – чтение следующего символа из входной цепочки.
Для управления состоянием автомата используется единственный знак операции Stop, предназначенный для останова по успешному окончанию восстановления дерева разбора. Для обозначения операции останова по обнаружению ошибок во входной цепочке используется обычное соглашение: соответствующая клетка управляющей таблицы пуста.
Процедура преобразования системы порождающих правил грамматики в управляющую таблицу автомата, реализованная в шаблонах пакета.
Шаг 1. Построить заготовку таблицы, имеющую ровно столько столбцов, сколько символов есть в терминальном алфавите грамматики (включая псевдотерминал ►), и столько строк, сколько символов есть в нетерминальном алфавите (ниже мы будет показано, что в процессе преобразования возможно появление дополнительных строк). Озаглавить столбцы терминалами грамматики (порядок следования столбцов не имеет значения), строки – нетерминалами (опять же в произвольном порядке).
Шаг 2. В силу т ого, что автомат предназначен для разбора цепочки, выводимой из правой части специального добавочного правила грамматики Z : S ►, перед запуском в его стеке должна оказаться правая часть этого правила, причем нижним символом в стеке должен быть псевдотерминал ►, а верхним, соответственно – начальный нетерминал грамматики. Поскольку рано или поздно псевдотерминал ► может стать верхним символом в стеке, к таблице добавляется еще одна строка, озаглавленная этим символом.
Шаг 3. Для каждой строки таблицы, начиная с первой, в ее клетках формируются знаки операций следующим образом:
Шаг 3.1. Если строка озаглавлена нетерминальным символом (пусть это будет символ N), то последовательно в произвольном порядке перебираются все правила грамматики, имеющие этот нетерминал в левой части.
Шаг 3.1.1. Если очередное правило имеет вид N : M , где M – нетерминальный символ, а – цепочка символов s1 s2 ... sk (возможно, пустая), то во все клетки данной строки, находящиеся на пересечении со столбцами, помеченными терминалами из множества выбора данного правила, заносится такая последовательность знаков операций:
^ !sk... s2 s1M
Если среди символов s1 s2 ... sk встречаются терминалы, то к таблице добавляются новые строки, озаглавленные этими терминалами, но только при условии, что таких строк в ней еще нет.
Шаг 3.1.2. Если очередное правило имеет вид N : t , где t – терминальный символ, а – возможно, пустая цепочка символов s1 s2 ... sk, то в клетку, находящуюся на пересечении со столбцом, помеченным терминалом t (очевидно, что множество выбора данного правила содержит единственный символ t), заносится такая последовательность знаков операций:
^ !sk... s2 s1 >
Если среди символов s1 s2 ... sk встречаются терминалы, то к таблице добавляются новые строки, озаглавленные этими терминалами, но только при условии, что таких строк в ней еще нет.
Эта последовательность знаков операций завершается чтением следующего входного символа вместо записи первого символа правой части правила в стек. Причина очевидна: терминал, с которого начинается цепочка правой части правила, совпадает с текущим входным символом. Если его заносить в стек, то только для того, чтобы удалить на следующем такте.
Шаг 3.1.3. Если очередное правило имеет вид N : , то во все клетки данной строки, находящиеся на пересечении со столбцами, помеченными терминалами из множества выбора данного правила, заносится единственный знак операции ^. Очевидно, что удаление символа N с верхушки стека без выполнения каких-либо других действий соответствует применению этого правила.
Шаг 3.2. Если текущая строка озаглавлена терминалом t, то в клетку, находящуюся на пересечении с одноименным столбцом (т. е. также озаглавленным терминалом t), заносится последовательность знаков операций ^ >. Терминал t мог быть занесен в стек при выполнении последовательности операций, сформированных согласно шагам 3.1.1 и 3.1.2. Если он появился на верхушке стека, то входным символом обязан быть именно этот терминал, иначе входная цепочка неверна. Последовательность знаков операций ^ > обеспечивает переход к следующим символам из стека и из входной цепочки.
Шаг 3.3. И, наконец, если текущая строка озаглавлена псевдотерминалом ►, то в клетку, находящуюся на пересечении с одноименным столбцом, заносится знак операции Stop.
Алгоритм работы программной модели автомата очень прост и здесь не описывается
-
Построение парсера, как нисходящего стекового автомата с несколькими состояниями.
Функционирование конечного автомата со стековой памятью и несколькими состояниями также определяется управляющей таблицей, но имеющей совершенно другую структуру. Предполагается, что автомат при запуске оказывается в особом начальном состоянии, на каждом такте по входному символу и текущему состоянию определяет и выполняет операции над входным потоком символов, стековой памятью и собственным состоянием.
Для выявления характера этих операций и структуры управляющей таблицы рассмотрим еще раз, но несколько с другой точки зрения, существо процесса нисходящего синтаксического акцепта.
Процесс нисходящего восстановления дерева грамматического разбора можно интерпретировать как управляемое входной цепочкой движение по порождающим правилам грамматики. Для такого рассмотрения удобно считать, что каждое правило завершается обозначением пустой цепочки . В этом случае обработка правил с пустой правой частью ничем не будет отличаться от обработки остальных правил. Управляющая таблица автомата при этом будет обладать некоторой избыточностью, впоследствии легко удаляемой.
Начиная с нетерминала S в правой части добавочного правила Z:S►, движение осуществляется следующим образом.
-
По правым частям правил посимвольно слева направо.
Обработка любого нетерминала состоит в переключении на первое правило для этого нетерминала. Более точно, на состояние, соответствующее нетерминалу из левой части первого правила с сохранением в стеке точки возврата в текущую правую часть правила. До переключения осуществляется проверка принадлежности текущего входного символа к множеству предшественников данного нетерминала (т.е. к объединению множеств выбора всех правил, в левой части которых находится этот нетерминал).
Обработка терминального символа состоит в проверке его совпадения с текущим входным символом и при положительном результате проверки завершается чтением следующего терминала из входной цепочки. Отрицательный результат проверки приводит к останову автомата по обнаружению ошибки.
Обработка пустой цепочки , завершающей каждое правило, состоит в возврате по номеру состояния, снимаемого с верхушки стека. Возврат в состояние, соответствующее псевдотерминалу ►, рассматривается как успешное окончание процесса восстановления дерева при условии, что текущим входным символом является признак конца входной цепочки ►. Если же в этот момент текущим входным символом является любой другой терминал, то выполняется останов по ошибке.
-
По левым частям правил сверху вниз.
При этом движении используются только правила, имеющие в левой части один и тот же нетерминал. Для каждого правила прежде всего проверяется, содержит ли его множество выбора текущий входной символ.
При отрицательном результате проверки осуществляется переход к левой части следующего правила, тем самым обеспечивается поиск подходящего правила для замены нетерминала.
При положительном результате проверки выполняется переключение на обработку первого символа из правой части данного правила, т. е. подстановка правой части вместо нетерминала из левой части.
Если такого правила нет вообще (ни одно из множеств выбора правил для данного нетерминала не содержит текущего входного символа), то восстановить дерево невозможно и следует остановиться по обнаружении ошибки во входном предложении.
Таким образом, каждому символу каждого правила грамматики (в том числе нетерминалам, находящимся в левых частях правил, и обозначениям пустой цепочки, замыкающим каждое правило), должно быть поставлено в соответствие в точности одно состояние автомата. С каждым состоянием должно быть связано множество выбора и два адреса перехода (один используется при положительном результате проверки принадлежности текущего входного символа множеству выбора, второй – при отрицательном). Под адресом перехода понимается номер состояния. Ниже показано, что при соблюдении определенных правил нумерации состояний и введении операции управления остановом по ошибке можно обойтись только одним адресом перехода.
С каждым состоянием должны быть также связаны операции управления стековой памятью (занесение адреса возврата, снятие адреса с верхушки стека и переключение в состояние возврата) и операция управления чтением следующего входного символа. Все операции управления могут задаваться булевскими значениями true/ false, которые далее называются флажками. Обозначения для флажков управления операциями:
-
флажок a управляет чтением следующего входного символа;
-
флажок s управляет занесением адреса точки возврата (вычисляемого как номер текущего состояния плюс 1) в стек;
-
флажок r обеспечивает переключение автомата в состояние, номер которого снимается с верхушки стека возвратов;
-
флажок e запрещает останов по ошибке в случае, когда состояние соответствует нетерминалу из левой части и есть еще хотя бы одно правило для такого нетерминала.
-
Таким образом, каждая клетка управляющей таблицы автомата должна содержать следующие поля:
Номер состояния
Флажки
Адрес перехода
Множество выбора состояния
Действие
a
s
r
e
При практических применениях автоматной реализации рекурсивного спуска в состав клетки управляющей таблицы обычно включаются дополнительное поле, указывающее на действие, сопровождающее синтаксический акцепт (например, для нейтрализации ошибок) или относящееся к задачам семантического анализа и формирования объектного кода.
Для построения управляющей таблицы автомата по заданной LL(1)-грамматике (в качестве иллюстрации используется грамматика G a2, к каждой правой части правил которой дописано обозначение пустой цепочки ) необходимо выполнить следующую процедуру.
Шаг 1. Определение и нумерация множества состояний. Для этого всем символам системы порождающих правил грамматики, исключая символ Z в левой части добавочного правила, но включая обозначения пустых цепочек присваивается номер так, чтобы:
-
символ S в добавочном правиле Z : S ► получил номер 0;
-

Таблица 4.2.
Грамматика G a2
0
Z : S0 1
1
S2 : U11 R12 13
2
R3 : + 14 S15 16
3
R4 : 17
4
U5 : V18 W19 20
5
W6 : *21 U22 23
6
W7 : 24
7
V8 : ( 25 S26 )27 28
8
V9 : i29 30
9
V10 : c31 32
символы, следующие друг за другом в правых частях правил, имели последовательно возрастающие номера; при соблюдении этого требования адрес возврата, помещаемый в стек при обработке нетерминального символа в правой части правила, вычисляется как номер текущего состояния плюс единица;
-
одинаковые нетерминалы в левых частях правил имели последовательно возрастающие номера; при соблюдении этого требования легко обеспечивается перебор правил при обработке нетерминалов из левых частей правил и .
В табл. 4.2. приведены результаты выполнения шага 1 для модифицированной грамматики Ga2.
Шаг 2. Формирование множества выбора для каждого состояния управляющей таблицы.
Способ образования множества выбора состояния зависит от того, какому символу (терминалу, нетерминалу или пустой цепочке) и из какой части правила оно поставлено в соответствие.
Если состояние соответствует нетерминалу N из левой части правила N : , то его множество выбора есть множество выбора данного правила:
– множество предшественников цепочки , если она содержит хотя бы один терминал или неаннулируемый нетерминал;
– множество последователей N, если цепочка пуста;
– объединение этих двух множеств, если цепочка не пуста, но состоит только из аннулируемых нетерминалов).
Если состояние соответствует нетерминальному символу из правой части правила, то его множество выбора есть объединение множеств выбора всех правил грамматики для этого нетерминала.
Если состояние соответствует терминальному символу (такие символы могут появляться только в правых частях правил), то его множество выбора содержит только этот терминальный символ.
Для состояний, соответствующих обозначениям пустой цепочки, множества выбора есть множество последователей нетерминала из левой части данного правила.
Шаг 3. Формирование значений флажков управления операциями.
Флажок a устанавливается (имеет значение true) только в состояниях, соответствующих терминальным символам (которые, естественно, могут находиться только в правых частях правил).
Флажок s устанавливается в состояниях, соответствующих нетерминальным символам, находящимся в правых частях правил.
Флажок r устанавливается в состояниях, соответствующих обозначениям пустой цепочки символов в конце правой части каждого правила.
Флажок e устанавливается в состояниях, соответствующих нетерминальным символам, находящимся в левой части правил, за исключением последнего правила для каждого нетерминала.
Шаг 4. Образование адреса перехода.
В клетках состояний, соответствующих нетерминалам из левых частей правил, адрес перехода должен быть равен номеру состояния, соответствующего первому символу правой части данного правила.
В клетках состояний, соответствующих символам из правых частей правил, адрес перехода формируется только в том случае, если для этого состояния не установлен флажок r (в том случае если флажок r установлен, переход осуществляется по адресу, снимаемому со стека возвратов). Если флажок в данном состоянии r установлен, в поле адреса перехода будем заносить значение 0. Особое значение адреса перехода (Stop) формируется для состояния 1. Переход по этому адресу означает останов автомата по окончании восстановления дерева разбора правильного предложения при условии, что стек пуст.
В противном случае (стек не пуст) операция Stop означает останов по ошибке.
Для состояний, соответствующих терминальным символам, в поле адреса перехода заносится номер состояния, соответствующего следующему символу правила (при используемом способе нумерации состояний он вычисляется как номер текущего состояния плюс единица).
Для состояний, соответствующих нетерминальным символам в правых частях правил, в поле адреса перехода заносится номер состояния, приписанного первому такому (одноименному) нетерминалу, но находящемуся в левой части правил.
В табл. 4.3. приведены результаты применения этой процедуры преобразования грамматики в управляющую таблицу автомата для грамматики Ga2 (в полях флажков управления значению true сопоставлено 1, значению false – пустая клетка).
Этот автомат имеет определенную избыточность. Добавление обозначений пустой цепочки в конец правой части правил 1, 2, 4, 5, 7, 8 и 9 привело к образованию в управляющей таблице состояний, зарезервированных для возможного включения действий в грамматику. Эти состояния с номерами 13, 16, 20, 23, 28, 30 и 32 являются избыточными при решении задачи чистого синтаксического акцепта, т. е. без учета задач нейтрализации ошибок, семантического анализа и генерации кода.
Таблица 4.3.
N
Флажки
Переход
Множество выбора
Действие
a
s
r
e
0
1
2
( i c
1
Stop
►
2
11
( i c
3
1
14
+
4
17
) ►
5
18
( i c
6
1
21
*
7
24
+ ) ►
8
1
25
(
9
1
29
i
10
31
c
11
1
5
( i c
12
1
3
+ ) ►
13
1
0
i c* +( ) ►
14
1
15
+
15
1
2
( i c
16
1
0
i c* +( ) ►
17
1
0
i c* +( ) ►
18
1
8
( i c
19
1
6
* + ) ►
20
1
0
i c* +( ) ►
21
1
22
*
22
1
5
( i c
23
1
0
i c* +( ) ►
24
1
0
i c* +( ) ►
25
1
26
(
26
1
2
( i c
27
1
28
)
28
1
0
i c* +( ) ►
29
1
30
i
30
1
0
i c* +( ) ►
31
1
32
c
32
1
0
ic* +( ) ►
Если для этих состояний при расширении синтаксического акцептора до анализатора так и не будут определены действия, то они легко могут быть удалены из управляющей таблицы.
Программная модель автомата с несколькими состояниями и стековой памятью должна реализовывать следующий алгоритм.
Шаг 1. Запуск и инициализация. Очистить стек, прочитать первый символ входной цепочки, установить в качестве текущего состояние 0 и перейти
к шагу 2.
Шаг 2. Проверить, принадлежит ли очередной символ множеству выбора текущего состояния. Если да, то перейти к шагу 3, иначе – к шагу 6.
Шаг 3. Если в клетке текущего состояния установлен флажок a, то прочитать следующий символ входной цепочки.
Шаг 4. Если в клетке текущего состояния установлен флажок s, то поместить в стек номер текущего состояния, увеличенный на единицу.
Шаг 5. Определение номера следующего состояния. Для этого прежде всего проверяется значение флажка r текущего состояния.
Шаг 5.1. Если флажок r установлен, то:
Шаг 5.1.1. Если стек не пуст, снять с верхушки стека номер состояния, установить его в качестве текущего и перейти к шагу 2;
Шаг 5.1.2. Если стек пуст – перейти к шагу 7.
Шаг 5.2. Если флажок r не установлен, то:
Шаг 5.2.1. Если текущим является состояние 1:
Шаг 5.2.1.1. Если стек пуст, то перейти к шагу 8.
Шаг 5.2.1.2. Если стек не пуст, перейти к шагу 7.
Шаг 5.2.2. Если текущим является любое другое состояние, то взять номер состояния из поля адреса перехода клетки текущего состояния. Установить в качестве текущего состояние с этим номером и вернуться к шагу 2.
Шаг 6. Если в клетке текущего состояния установлен флажок e, то установить в качестве текущего следующее состояние (его номер вычисляется, как номер текущего состояния плюс единица) и вернуться к шагу 2, иначе – перейти к шагу 7.
Шаг 7. Останов по ошибке.
Шаг 8. Останов по окончании разбора правильного предложения.
-
Построение парсера, как совокупности функций нисходящего рекурсивного восстановления дерева разбора.
Пакет ВебТрансБилдер предоставляет возможность преобразования LL(1)-грамматики в программный код, содержащий совокупность функций нисходящего рекурсивного восстановления дерева разбора.
Для каждого нетерминала грамматики создается функция, которая:
-
поочередно проверяет принадлежность текущего терминала из предложения множеству выбора каждого правила;
-
при положительном результате проверки «реализует» правую часть правила, двигаясь по ее символам слева направо и:
-
вызывая соответствующие функции парсера (возможно и сама себя), если очередной символ – это нетерминал;
-
сравнивая символ из правила с текущим терминалом, если это терминал и:
-
вызывая лексический анализатор для чтения следующего терминала из предложения при совпадении символов;
-
возвращая значение false (ложь) при несовпадении;
-
возвращая значение true (истина), если был обработан последний символ правой части правила (или правая часть пуста);
-
возвращает значение false (ложь), если не было найдено ни одного подходящего правила.
Детально способ преобразования LL(1)-грамматики в программный код описан в [1-5].
-
Порядок выполнения работы (рекомендуется использовать в качестве примера систему правил Samples/Sample4):
-
Используя пакет ВебТрансБилдер:
-
расширить грамматику заданного на курсовую работу языка, разработанную при выполнении работы №3 до полной грамматики языка (или как минимум до грамматики блока операторов с реализацией правил для всех заданных операторов языка согласно варианту курсовой работы);
-
изучить и освоить проверку принадлежности грамматики к классу LL(1) (пункт меню «Показать/Множества выбора правил»); изучить, что такое множества выбора правил и как они формируются; изучить их использование для преобразования грамматики в нисходящий синтаксический анализатор;
-
добиться того, чтобы разработанная грамматика стала принадлежать классу LL(1); при необходимости освоить для этого технологию удаления терминальных символов из множеств выбора правил с использованием токена «
»;
парсер, как нисходящий стековый автомат с одним состоянием;
парсер, как нисходящий стековый автомат с несколькими состояниями;
парсер, как совокупность функций.
-
Построение парсера, как нисходящего стекового автомата с одним состоянием.
-
Построение парсера, как нисходящего стекового автомата с несколькими состояниями.
По правым частям правил посимвольно слева направо.
По левым частям правил сверху вниз.
-
флажок a управляет чтением следующего входного символа; -
флажок s управляет занесением адреса точки возврата (вычисляемого как номер текущего состояния плюс 1) в стек; -
флажок r обеспечивает переключение автомата в состояние, номер которого снимается с верхушки стека возвратов; -
флажок e запрещает останов по ошибке в случае, когда состояние соответствует нетерминалу из левой части и есть еще хотя бы одно правило для такого нетерминала.
Таким образом, каждая клетка управляющей таблицы автомата должна содержать следующие поля:
| Номер состояния | Флажки | Адрес перехода | Множество выбора состояния | Действие | |||||
| a | s | r | e | ||||||
символ S в добавочном правиле Z : S ► получил номер 0;
Таблица 4.2.
| Грамматика G a2 | |
| 0 | Z : S0 1 |
| 1 | S2 : U11 R12 13 |
| 2 | R3 : + 14 S15 16 |
| 3 | R4 : 17 |
| 4 | U5 : V18 W19 20 |
| 5 | W6 : *21 U22 23 |
| 6 | W7 : 24 |
| 7 | V8 : ( 25 S26 )27 28 |
| 8 | V9 : i29 30 |
| 9 | V10 : c31 32 |
символы, следующие друг за другом в правых частях правил, имели последовательно возрастающие номера; при соблюдении этого требования адрес возврата, помещаемый в стек при обработке нетерминального символа в правой части правила, вычисляется как номер текущего состояния плюс единица;
одинаковые нетерминалы в левых частях правил имели последовательно возрастающие номера; при соблюдении этого требования легко обеспечивается перебор правил при обработке нетерминалов из левых частей правил и .
| N | Флажки | Переход | Множество выбора | Действие | ||||
| | | a | s | r | e | |||
| | 0 | | 1 | | | 2 | ( i c | |
| | 1 | | | | | Stop | ► | |
| | 2 | | | | | 11 | ( i c | |
| | 3 | | | | 1 | 14 | + | |
| | 4 | | | | | 17 | ) ► | |
| | 5 | | | | | 18 | ( i c | |
| | 6 | | | | 1 | 21 | * | |
| | 7 | | | | | 24 | + ) ► | |
| | 8 | | | | 1 | 25 | ( | |
| | 9 | | | | 1 | 29 | i | |
| | 10 | | | | | 31 | c | |
| | 11 | | 1 | | | 5 | ( i c | |
| | 12 | | 1 | | | 3 | + ) ► | |
| | 13 | | | 1 | | 0 | i c* +( ) ► | |
| | 14 | 1 | | | | 15 | + | |
| | 15 | | 1 | | | 2 | ( i c | |
| | 16 | | | 1 | | 0 | i c* +( ) ► | |
| | 17 | | | 1 | | 0 | i c* +( ) ► | |
| | 18 | | 1 | | | 8 | ( i c | |
| | 19 | | 1 | | | 6 | * + ) ► | |
| | 20 | | | 1 | | 0 | i c* +( ) ► | |
| | 21 | 1 | | | | 22 | * | |
| | 22 | | 1 | | | 5 | ( i c | |
| | 23 | | | 1 | | 0 | i c* +( ) ► | |
| | 24 | | | 1 | | 0 | i c* +( ) ► | |
| | 25 | 1 | | | | 26 | ( | |
| | 26 | | 1 | | | 2 | ( i c | |
| | 27 | 1 | | | | 28 | ) | |
| | 28 | | | 1 | | 0 | i c* +( ) ► | |
| | 29 | 1 | | | | 30 | i | |
| | 30 | | | 1 | | 0 | i c* +( ) ► | |
| | 31 | 1 | | | | 32 | c | |
| | 32 | | | 1 | | 0 | ic* +( ) ► | |
-
Построение парсера, как совокупности функций нисходящего рекурсивного восстановления дерева разбора.
поочередно проверяет принадлежность текущего терминала из предложения множеству выбора каждого правила;
при положительном результате проверки «реализует» правую часть правила, двигаясь по ее символам слева направо и:
-
вызывая соответствующие функции парсера (возможно и сама себя), если очередной символ – это нетерминал; -
сравнивая символ из правила с текущим терминалом, если это терминал и:-
вызывая лексический анализатор для чтения следующего терминала из предложения при совпадении символов; -
возвращая значение false (ложь) при несовпадении;
-
-
возвращая значение true (истина), если был обработан последний символ правой части правила (или правая часть пуста);
возвращает значение false (ложь), если не было найдено ни одного подходящего правила.
Порядок выполнения работы (рекомендуется использовать в качестве примера систему правил Samples/Sample4):
-
Используя пакет ВебТрансБилдер:
расширить грамматику заданного на курсовую работу языка, разработанную при выполнении работы №3 до полной грамматики языка (или как минимум до грамматики блока операторов с реализацией правил для всех заданных операторов языка согласно варианту курсовой работы);
изучить и освоить проверку принадлежности грамматики к классу LL(1) (пункт меню «Показать/Множества выбора правил»); изучить, что такое множества выбора правил и как они формируются; изучить их использование для преобразования грамматики в нисходящий синтаксический анализатор;
добиться того, чтобы разработанная грамматика стала принадлежать классу LL(1); при необходимости освоить для этого технологию удаления терминальных символов из множеств выбора правил с использованием токена «
построить конечный автомат со стековой памятью и несколькими состояниями, найти в коде построенного автомат управляющую таблицу, описать для отчета ее структуру;
построить конечный автомат со стековой памятью и одним состоянием, управляемый входным символом и символом, снятым с верхушки стека, найти в коде построенного автомат управляющую таблицу, описать для отчета ее структуру;
построить программную реализацию нисходящего рекурсивного спуска, найти в коде функцию, построенную для нетерминала, определяющего оператор присваивания, описать ее алгоритм для отчета.
-
Выполнить трассировку процессов нисходящего синтаксического акцепта для всех построенных синтаксических анализаторов, включая флажок показа истории работы при запуске транслятора на тестирование. Изучить по историям работы поведение всех построенных синтаксических акцепторов при разборе как правильных предложений, так и предложений с намеренно внесенными синтаксическими ошибками. -
Проанализировать и сравнить между собой все полученные тексты программ и результаты выполнения пункта 4.2. Оценить степень пригодности изученных вариантов реализации нисходящих синтаксических акцепторов для выполнения курсовой работы, отразить результаты этой оценки в заключении к отчету. -
Подготовить, сдать и защитить отчет к лабораторной работе.
-
Требования к содержанию отчета.
Отчет должен содержать:
-
цель работы; -
систему правил LL(1)-грамматики для языка, заданного на курсовую работу; -
описание этой грамматики в качестве фрагмента расчетно-пояснительной записки к курсовой работе; -
фрагменты текста процедурной реализации и управляющих таблиц автоматных реализаций нисходящего синтаксического акцептора, построенных по этой грамматике для разбора оператора присваивания, описания структур данных и алгоритмов работы соответствующих автоматов; -
фрагменты историй работы процедурной и автоматных реализаций нисходящего синтаксического акцептора для правильного и ошибочного тестовых примеров; описание фрагментов этих историй для разбора оператора присваивания; -
выводы и заключение.
-
Контрольные вопросы.
-
Что такое множество выбора правила грамматики? -
Постройте историю работы нисходящего синтаксического акцептора с одним состоянием при разборе цепочки: (((x))) -
Напишите LL(1)-грамматику для условного оператора С-подобного языка, имеющего и полную и сокращенную форму. -
Что такое s-грамматика? -
Какие операции способен выполнять автомат нисходящего восстановления дерева грамматического разбора с одним состоянием? -
Что такое LL(1)-грамматики? -
Что такое детерминированное (безвозвратное) восстановление дерева грамматического разбора? -
Почему леворекурсивная грамматика не может быть преобразована в нисходящий синтаксический акцептор? -
Опишите технологию разработки процедурной реализации рекурсивного спуска. -
Как вычисляются множества выбора правил грамматики? -
Перечислите поля клетки нисходящего автомата с несколькими состояниями. -
Как формируются значения флагов в управляющей таблице нисходящего синтаксического акцептора с несколькими состояниями? -
Разработайте LL(1)-грамматику для оператора переключателя (switch) С-подобного языка. -
В каком порядке нумеруются символы грамматики при преобразовании в управляющую таблицу автомата с несколькими состояниями? -
Чем управляется нисходящий автомат с одним состоянием? -
Каково назначение каждого управляющего флажка управляющей таблицы автомата с несколькими состояниями? -
Как формируются значения управляющих флагов нисходящего автомата с несколькими состояниями? -
Опишите последовательность действий при преобразовании грамматики в процедурную реализацию нисходящего синтаксического акцептора. -
Как формируются множества выбора состояний нисходящего синтаксического акцептора с несколькими состояниями? -
Опишите процесс функционирования нисходящего рекурсивного спуска.
Лабораторная/практическая работа № 5
-
Название работы: «Синтаксис языков программирования. Восходящий синтаксический анализ, автоматная реализация». -
Цели работы: изучение основных идей и понятий восходящего синтаксического анализа, свойств формальных грамматик, определяющих принадлежность грамматики к одному из классов LR, получение навыков построения автоматной реализации восходящего анализатора, исследование поведения восходящих синтаксических акцепторов. -
Основные теоретические сведения:
-
Восходящие методы синтаксического анализа
Восходящими называются такие методы синтаксического анализа, при которых цепочка терминальных символов входного предложения шаг за шагом «сворачивается» в цепочки, содержащие и нетерминальные символы и являющиеся очередными уровнями дерева грамматического разбора. Этот процесс продолжается до тех пор, пока все правильное предложение не окажется свернутым в цепочку, содержащую единственный нетерминальный символ – начальный нетерминал грамматики, либо до тех пор, пока не будет обнаружена невозможность восстановления дерева для неправильных предложений, т. е. ошибка
Как и для группы нисходящих методов, главным прагматическим требованием к организации процесса сворачивания цепочек является детерминированность (однонаправленность) движения по дереву снизу вверх. Опять-таки, как и при нисходящем анализе, не любая грамматика обладает такими свойствами, чтобы по ее правилам можно было осуществлять детерминированное восходящее восстановление дерева разбора.
-
Структура автомата для восходящего восстановления дерева грамматического разбора
Восходящий синтаксический акцептор представляет собой конечный автомат со стековой памятью (рис. 5.1.), управляемый входным символом и текущим состоянием.
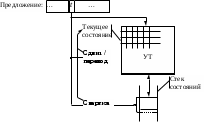
Рис. 5.1.Восходящий парсер как автомат с несколькими состояниями и стеком состояний
Перед запуском автомата номер его начального состояния (состоянии с номером 0) должен быть занесен в стек. Далее на каждом шаге работы номер состояния, находящий на верхушке стека, используется в качестве текущего и определяет выбор строки управляющей таблицы. Из входного предложения прочитан первый терминал, этот символ находится на входе автомата и определяет колонку управляющей таблицы. На каждом шаге работы из клетки, находящейся на пересечении строки текущего состояния и столбца текущего
символа выбирается и выполняется знак операции, в результате чего может измениться содержимое стека (и, соответственно, текущее состояние) и символ на входе автомата. Этот процесс продолжается до тех пор, пока автомат не остановится по завершению восстановления дерева разбора правильного предложения или по обнаружению ошибки.
Знаки операций, которые могут находиться в клетках управляющей таблицы, таковы:
Sn – сдвиг (Shift) по входному предложению, т.е. чтение следующего терминала из анализируемого предложения путем вызова лексического анализатора, сопровождаемое занесением номера состояния n на верхушку стека. Автомат переключается в состояние n, на его входе появляется прочитанный терминал.
Gn – переход (Go) в новое состояние. Номер состояния n заносится на верхушку стека, автомат переключается в состояние n. Эта операция выполняется всегда после выполнения операции свертки, которая «образовала» нетерминальный символ и поместила его на вход автомата перед текущим терминалом. Текущий терминал не изменяется.
Rk,N – свертка (Reduce) правой части правила для нетерминала N, имеющей длину k символов. С верхушки стека сбрасывается в никуда k номеров состояний (эта последовательность номеров образовалась в стеке в результате выполнения k предыдущих во времени операций Shift и Go, соответствующих символам правой части этого правила). Автомат переключается в состояние, номер которого остался на верхушке стека (и который был там до выполнения k операций Shift и Go, соответствующих символам правой части этого правила). Формируется нетерминал N, временно, до выполнения операции Go, «вытесняющий» текущий терминал со входа автомата. В дальнейшем для удобства практической реализации вместо обозначения Rk,N будет использоваться обозначение Rk,n, где малое n обозначает номер столбца управляющей таблицы, помеченного нетерминалом N.
Stop – останов по завершению восстановления дерева разбора правильного предложения (пакет ВебТрансБилдер вместо этого обозначения формирует знак операции S-1; отрицательное значение в обозначении операции Shift трактуется как операция Stop).
Отсутствие любой из этих операций в клетке означает операцию останова по обнаружению ошибки.
Для преобразования данной контекстно-свободной грамматики в управляющую таблицу такого автомата может быть использовано несколько разных по сложности алгоритмов. В процессе преобразования может быть выяснено, применим ли данный алгоритм к данной грамматике, т.е. будет ли построенный автомат стопроцентно работоспособен. При получении положительного ответа на этот вопрос можно просто использовать построенный автомат следует т в качестве парсера. При обнаружении отрицательного результата можно попытаться построить автомат, применяя более сложный алгоритм, или же попытаться модифицировать грамматику или ее свойства для повторного применения уже использовавшегося алгоритма. Алгоритмы преобразования используют то или иное понятие конфигурации. Начнем с простейшего.