ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.10.2023
Просмотров: 345
Скачиваний: 5
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
abи be. Отрезки, отвечающие совокупностям возможных идеальных точек первых двух респондентов, отмечены в нижней части рисунка.
А вот с третьим респондентом дело обстоит сложнее. Рассуждения того же типа приведут нас к необходимости выполнения противоречивого требования: идеальная точка этого респондента должна находиться одновременно левее вертикали abи правее вертикали be. Другими словами, при указанном выборе первоначального расположения шкалируемых объектов на оси мы в принципе не можем найти места для идеальной точки третьего респондента.
Предположим теперь, что мы опросили не трех, а произвольное количество респондентов. Ясно, что, вообще говоря, многие из них дадут одинаковые ранжировки. Для простоты будем считать, что никакие ранжировки, кроме перечисленных трех, у нас не встретились, а каждую из этих трех какое-то количество респондентов указало. Далее мы рассуждаем следующим образом.
Сказанное выше справедливо для идеальных точек всех рассматриваемых респондентов. Если доля людей, давших ту же ранжировку, что и третий респондент, окажется очень маленькой (скажем, их будет меньше 1%), то будем считать себя вправе их мнение проигнорировать и полагать, что мы свою задачу решили — указали какое-то конкретное расположение на прямой как точек, отвечающих шкалируемым объектам, так и идеальных точек наших респондентов.
Прежде чем описывать дальнейший ход рассуждений, подчеркнем то, о чем мы уже говорили при обсуждении установочной шкалы Терстоуна: игнорирование мнения даже одного респондента может носить лишь условный характер. Мы его не учитываем только при построении данной определенной модели, только "на время". Далее мы должны по возможности изучить этого человека — подробнее проанализировать его ответы на другие предложенные ему вопросы, вернуться к его опросу (хотя это, как правило, в социологических исследованиях бывает невозможно сделать) и т.д. Еще раз подчеркнем, что рассматриваемые в данной книге методы носят статистический характер,т.е. описывают изучаемые явления "в среднем". Не исключены ситуации, когда тщательный анализ мнения одного человека может дать больше, чем традиционный анкетный опрос огромного числа людей.
И еще одно вспомогательное замечание необходимо здесь сделать. Выбор порога, определяющего долю респондентов, мнение которых можно игнорировать в описанном выше смысле, является делом весьма субъективным (мы уже наталкивались на подобное обстоятельство; можно сказать, что здесь мы имеем дело с довольно типичной для социологии ситуацией). Только практика (своя или чужая) может дать ответ на вопрос о величине порога.
Предположим теперь, что мы не можем проигнорировать мнение людей, давших такую же ранжировку, как третий респондент, — предположим, что такую ранжировку дали 40% всех респондентов. В таком случае возможны два выхода.
Первый состоит в том, что мы считаем нашу совокупность неоднородной и полагаем, что наши 60% и 40% респондентов образуют две внутренне однородные подсовокупности, и с каждой из них работаем отдельно. Прийти к такому выводу можно только на основе содержательных соображений. Так, скажем, шкалируя политиков, к решению о принципиальном различии рассматриваемых совокупностей можно прийти, если, к примеру, окажется, что среди наших 60% респондентов почти все на первые места ставят лидеров — сторонников правящей партии, а среди 40% — напротив, сторонников оппозиции.
Второй выход заключается в признании неправильности нашего первоначального расположения объектов на оси и переходе к какому-либо другому расположению. При этом подчеркнем, что выше, в процессе поиска идеальных точек, использовался только порядок упомянутого расположения. Поэтому, говоря о переходе к другому варианту, мы имеем в виду изменение этого порядка. Ни о каких соотношениях для интервалов между рассматриваемыми точками прямой, ни о каких других привычных нам свойствах чисел речи пока не идет.
Итак, пусть новое расположение шкалируемых объектов имеет вид, скажем, изображенный на рис.9.5. Начнем все сначала — снова попытаемся найти место для идеальных точек всех рассматриваемых респондентов. И таким образом переберем все возможные варианты расположения объектов а, Ь, с на оси.

Процедура продолжается до тех пор, пока мы не найдем такое расположение объектов на оси, при котором сравнительно мало реальных ранжировок будет нами проигнорировано. Если таких приемлемых вариантов будет несколько, выберем наилучший, т.е. такой, при котором отбрасывается наименьшее количество информации.
Возможна и такая ситуация, когда окажутся непригодными все возможные варианты. В таком случае метод работает как шкальный критерий (так же, как это имело место в методе парных сравнений) — мы приходим к выводу, что работу надо прекратить, строить одномерную шкалу бессмысленно. И,конечно, основная причина возникновения подобной ситуации может быть усмотрена в том, что мышление респондентов неодномерно и, следовательно, надо искать другие способы решения задачи, например переходить к многомерному шкалированию.
Если число шкалируемых объектов больше трех, то рассматриваемый подход может иногда заставить нас учитывать не только порядок расположения объектов на оси, но и соотношение интервалов между ними. Начнем с примера.
П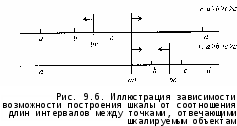
усть a,b,c,d—шкалируемые объекты и какой-то респондент г дал ранжировку вида: d>b>c>a. Рассмотрим рис. 9.6.
(На рисунке представлены не все варианты, требующиеся для поиска идеальной точки для респондента г).
Пытаясь найти идеальную точку нашего респондента на верхней прямой, мы придем к противоречию, поскольку соответствующие полупрямые (идущая от середины beвлево и от середины adвправо) не пересекаются. Однако если перейти к нижней прямой, место этой идеальной точки легко отыскивается — это отрезок между серединами adи be. В чем же дело? Причина в том, что на верхней прямой расстояние от α до bбыло меньше расстояния от с до d, а на нижней — наоборот. Если за рассматриваемой ранжировкой стоит значительная доля респондентов, то вполне может оказаться, что единственным способом разместить и объекты, и идеальные точки респондентов на оси является выполнение требования: расстояние между α и bбольше расстояния между с и d. В таком случае результатом решения нашей задачи — расположения на оси объектов и идеальных точек респондентов — явится не только некая результирующая ранжировка объектов, но и частичное упорядочение расстояний между ними. Это означает, что получающаяся шкала обладает свойствами не только порядковой шкалы, но и некоторыми свойствами интервальной, т.е. по существу является промежуточной между этими шкалами.
Рассмотрим получающиеся с помощью метода одномерного развертывания результаты более подробно.
9.5. Задачи, решаемые методом
Итак, метод одномерного развертывания предполагает, что исследователя интересует отношение некоторой совокупности респондентов к каким-то объектам. Исходными данными служат результаты ранжирования респондентами рассматриваемых объектов. Соответствующая техника позволяет получать расположение на числовой оси одновременно и респондентов, и объектов. Обсудим более подробно значение этих результатов для социолога.
Используя метод, мы получаем следующую информацию.
Построенную оценочную шкалу можно считать результатом усреднения исходных ранжировок. Важность получения "средней" для всех респондентов ранжировки не вызывает сомнений. Проблема усреднения мнений экспертов (в частности, высказанных в виде ранжировок рассматриваемых объектов) известна давно (особенно в том разделе прикладной статистики, который связывается с так называемыми экспертными оценками). Существует множество подходов к ее решению. В каждом — свои плюсы и минусы. Подход Кумбса представляется практически полезным потому, что в меньшей степени, чем другие, опирается на трудно проверяемые модельные предположения.
Еще большую значимость этот подход приобретает в силу того, что иногда позволяет получить информацию, на первый взгляд не заложенную в исходных данных. Мы имеем в виду частичное упорядочение расстояний между шкалируемыми объектами. Респонденты дают нам только ранжировки. А метод позволяет помимо усредненной ранжировки найти еще и соотношения типа: "В целом респонденты рассматриваемой совокупности полагают, что различие между лидером а и лидером bменьше, чем между с и а"'и т.д.
Заметим, что здесь часто бывает трудно говорить о построении установочной шкалы, поскольку, хотя мы и получаем идеальные точки респондентов (а их в принципе можно было бы расценивать как соответствующие шкальные значения), но из-за их неоднозначности практически невозможно сравнивать их относительное расположение. Правда, иногда полезную информацию исследователь может получить на основе анализа взаимного расположения шкальных значений объектов и респондентов.
Поскольку метод работает как шкальный критерий, то в ряде случаев мы вместо описанных шкал получаем информацию о том, что их строить не имеет смысла (наиболее распространенная причина этого — их многомерность).
9.6. Методические выводы
Очень важным нам представляется анализ предложенного Кум-бсом подхода с точки зрения иллюстрации некоторых общих методических соображений, касающихся измерения в социологии. Мы имеем в виду следующие обстоятельства.
Прежде всего отметим, что и процесс применения метода, и его результаты ярко демонстрируют сущность порядковой и интервальной шкалы.
Необходимость разговора на соответствующую тему обусловлена наличием у некоторых исследователей-социологов какой-то психологической "заслонки", которая мешает правильно воспринять сущность социологического измерения. И анализ некоторых аспектов метода одномерного развертывания, как нам кажется, позволяет эту "заслонку" ликвидировать. Поясним это соображение.
Наш опыт говорит о том, что исследователи иногда не воспринимают полученное с помощью метода одномерного развертывания расположение объектов на оси как результат измерения. Исследователь недоумевает: как можно расценивать подобным образом ситуацию, когда мы абсолютно не знаем, в каком месте числовой оси каждый объект находится. Единственно, что нам известно, это то, что один объект левее, другой правее (на сколько — не ясно !), третий — еще правее и т.д. И в то же время тот же самый исследователь вполне спокойно воспринимает сообщение о том, что, скажем, числа — ответы респондентов на традиционный вопрос об удовлетворенности работой можно считать полученными по порядковой шкале. И даже согласится с тем, что эти числа определены с точностью до порядка их расположения. А ведь указанная неоднозначность того расположения объектов, которое мы получаем с помощью метода одномерного развертывания, — это то же самое, только представленное в наглядном, "бьющем в глаза" виде.
Суть порядковых шкал заключается в том, что вместо набора чисел (1, 2, 3, 4, 5) могут фигурировать, скажем, числа (1, 43, 44, 100, 538). Однако констатация этого обычно вызывает возражение, поскольку в последней пятерке чисел различие между четвертым и пятым много больше различия между первым и вторым и т.д. Но это возражение несостоятельно. Оно означает принятие предположения об интервальное™ той шкалы, по которой получен набор (1, 2, 3, 4, 5), т.е. осмысленность соотношений между интервалами, чего на самом деле нет.
То, что даже при порядковом уровне измерения в практических исследованиях фигурирует последний названный нами набор чисел (с равными интервалами!), как бы затеняет истинную сущность шкалы, состоящую в том, что полученные с ее помощью шкальные значения определены только с точностью до порядка! Кумбсовский же подход, напротив, эту сущность высвечивает.
Далее, с методической точки зрения важно еще раз обратить внимание на то, что одномерное развертывание дает возможность измерять нетрадиционные отношения между объектами (частичное упорядочение расстояний между ними).
Социолог, как правило, не задумывается о том, что в тех случаях, когда приписать объектам числа по интервальной шкале не удается (напомним, что интервальность шкалы означает осмысленность структуры межобъектных расстояний), иногда все же бывает полезно получить хотя бы какие-нибудь соотношения для расстояний между объектами. Так, в дополнение к ранжировке телепередач неплохо было бы узнать, что, скажем, такие-то две передачи вызывают примерно одинаковый зрительский интерес, а вот две другие совершенно по-разному воспринимаются изучаемой аудиторией.
А вот с третьим респондентом дело обстоит сложнее. Рассуждения того же типа приведут нас к необходимости выполнения противоречивого требования: идеальная точка этого респондента должна находиться одновременно левее вертикали abи правее вертикали be. Другими словами, при указанном выборе первоначального расположения шкалируемых объектов на оси мы в принципе не можем найти места для идеальной точки третьего респондента.
Предположим теперь, что мы опросили не трех, а произвольное количество респондентов. Ясно, что, вообще говоря, многие из них дадут одинаковые ранжировки. Для простоты будем считать, что никакие ранжировки, кроме перечисленных трех, у нас не встретились, а каждую из этих трех какое-то количество респондентов указало. Далее мы рассуждаем следующим образом.
Сказанное выше справедливо для идеальных точек всех рассматриваемых респондентов. Если доля людей, давших ту же ранжировку, что и третий респондент, окажется очень маленькой (скажем, их будет меньше 1%), то будем считать себя вправе их мнение проигнорировать и полагать, что мы свою задачу решили — указали какое-то конкретное расположение на прямой как точек, отвечающих шкалируемым объектам, так и идеальных точек наших респондентов.
Прежде чем описывать дальнейший ход рассуждений, подчеркнем то, о чем мы уже говорили при обсуждении установочной шкалы Терстоуна: игнорирование мнения даже одного респондента может носить лишь условный характер. Мы его не учитываем только при построении данной определенной модели, только "на время". Далее мы должны по возможности изучить этого человека — подробнее проанализировать его ответы на другие предложенные ему вопросы, вернуться к его опросу (хотя это, как правило, в социологических исследованиях бывает невозможно сделать) и т.д. Еще раз подчеркнем, что рассматриваемые в данной книге методы носят статистический характер,т.е. описывают изучаемые явления "в среднем". Не исключены ситуации, когда тщательный анализ мнения одного человека может дать больше, чем традиционный анкетный опрос огромного числа людей.
И еще одно вспомогательное замечание необходимо здесь сделать. Выбор порога, определяющего долю респондентов, мнение которых можно игнорировать в описанном выше смысле, является делом весьма субъективным (мы уже наталкивались на подобное обстоятельство; можно сказать, что здесь мы имеем дело с довольно типичной для социологии ситуацией). Только практика (своя или чужая) может дать ответ на вопрос о величине порога.
Предположим теперь, что мы не можем проигнорировать мнение людей, давших такую же ранжировку, как третий респондент, — предположим, что такую ранжировку дали 40% всех респондентов. В таком случае возможны два выхода.
Первый состоит в том, что мы считаем нашу совокупность неоднородной и полагаем, что наши 60% и 40% респондентов образуют две внутренне однородные подсовокупности, и с каждой из них работаем отдельно. Прийти к такому выводу можно только на основе содержательных соображений. Так, скажем, шкалируя политиков, к решению о принципиальном различии рассматриваемых совокупностей можно прийти, если, к примеру, окажется, что среди наших 60% респондентов почти все на первые места ставят лидеров — сторонников правящей партии, а среди 40% — напротив, сторонников оппозиции.
Второй выход заключается в признании неправильности нашего первоначального расположения объектов на оси и переходе к какому-либо другому расположению. При этом подчеркнем, что выше, в процессе поиска идеальных точек, использовался только порядок упомянутого расположения. Поэтому, говоря о переходе к другому варианту, мы имеем в виду изменение этого порядка. Ни о каких соотношениях для интервалов между рассматриваемыми точками прямой, ни о каких других привычных нам свойствах чисел речи пока не идет.
Итак, пусть новое расположение шкалируемых объектов имеет вид, скажем, изображенный на рис.9.5. Начнем все сначала — снова попытаемся найти место для идеальных точек всех рассматриваемых респондентов. И таким образом переберем все возможные варианты расположения объектов а, Ь, с на оси.
Процедура продолжается до тех пор, пока мы не найдем такое расположение объектов на оси, при котором сравнительно мало реальных ранжировок будет нами проигнорировано. Если таких приемлемых вариантов будет несколько, выберем наилучший, т.е. такой, при котором отбрасывается наименьшее количество информации.
Возможна и такая ситуация, когда окажутся непригодными все возможные варианты. В таком случае метод работает как шкальный критерий (так же, как это имело место в методе парных сравнений) — мы приходим к выводу, что работу надо прекратить, строить одномерную шкалу бессмысленно. И,конечно, основная причина возникновения подобной ситуации может быть усмотрена в том, что мышление респондентов неодномерно и, следовательно, надо искать другие способы решения задачи, например переходить к многомерному шкалированию.
Если число шкалируемых объектов больше трех, то рассматриваемый подход может иногда заставить нас учитывать не только порядок расположения объектов на оси, но и соотношение интервалов между ними. Начнем с примера.
П
усть a,b,c,d—шкалируемые объекты и какой-то респондент г дал ранжировку вида: d>b>c>a. Рассмотрим рис. 9.6.
(На рисунке представлены не все варианты, требующиеся для поиска идеальной точки для респондента г).
Пытаясь найти идеальную точку нашего респондента на верхней прямой, мы придем к противоречию, поскольку соответствующие полупрямые (идущая от середины beвлево и от середины adвправо) не пересекаются. Однако если перейти к нижней прямой, место этой идеальной точки легко отыскивается — это отрезок между серединами adи be. В чем же дело? Причина в том, что на верхней прямой расстояние от α до bбыло меньше расстояния от с до d, а на нижней — наоборот. Если за рассматриваемой ранжировкой стоит значительная доля респондентов, то вполне может оказаться, что единственным способом разместить и объекты, и идеальные точки респондентов на оси является выполнение требования: расстояние между α и bбольше расстояния между с и d. В таком случае результатом решения нашей задачи — расположения на оси объектов и идеальных точек респондентов — явится не только некая результирующая ранжировка объектов, но и частичное упорядочение расстояний между ними. Это означает, что получающаяся шкала обладает свойствами не только порядковой шкалы, но и некоторыми свойствами интервальной, т.е. по существу является промежуточной между этими шкалами.
Рассмотрим получающиеся с помощью метода одномерного развертывания результаты более подробно.
9.5. Задачи, решаемые методом
Итак, метод одномерного развертывания предполагает, что исследователя интересует отношение некоторой совокупности респондентов к каким-то объектам. Исходными данными служат результаты ранжирования респондентами рассматриваемых объектов. Соответствующая техника позволяет получать расположение на числовой оси одновременно и респондентов, и объектов. Обсудим более подробно значение этих результатов для социолога.
Используя метод, мы получаем следующую информацию.
Построенную оценочную шкалу можно считать результатом усреднения исходных ранжировок. Важность получения "средней" для всех респондентов ранжировки не вызывает сомнений. Проблема усреднения мнений экспертов (в частности, высказанных в виде ранжировок рассматриваемых объектов) известна давно (особенно в том разделе прикладной статистики, который связывается с так называемыми экспертными оценками). Существует множество подходов к ее решению. В каждом — свои плюсы и минусы. Подход Кумбса представляется практически полезным потому, что в меньшей степени, чем другие, опирается на трудно проверяемые модельные предположения.
Еще большую значимость этот подход приобретает в силу того, что иногда позволяет получить информацию, на первый взгляд не заложенную в исходных данных. Мы имеем в виду частичное упорядочение расстояний между шкалируемыми объектами. Респонденты дают нам только ранжировки. А метод позволяет помимо усредненной ранжировки найти еще и соотношения типа: "В целом респонденты рассматриваемой совокупности полагают, что различие между лидером а и лидером bменьше, чем между с и а"'и т.д.
Заметим, что здесь часто бывает трудно говорить о построении установочной шкалы, поскольку, хотя мы и получаем идеальные точки респондентов (а их в принципе можно было бы расценивать как соответствующие шкальные значения), но из-за их неоднозначности практически невозможно сравнивать их относительное расположение. Правда, иногда полезную информацию исследователь может получить на основе анализа взаимного расположения шкальных значений объектов и респондентов.
Поскольку метод работает как шкальный критерий, то в ряде случаев мы вместо описанных шкал получаем информацию о том, что их строить не имеет смысла (наиболее распространенная причина этого — их многомерность).
9.6. Методические выводы
Очень важным нам представляется анализ предложенного Кум-бсом подхода с точки зрения иллюстрации некоторых общих методических соображений, касающихся измерения в социологии. Мы имеем в виду следующие обстоятельства.
Прежде всего отметим, что и процесс применения метода, и его результаты ярко демонстрируют сущность порядковой и интервальной шкалы.
Необходимость разговора на соответствующую тему обусловлена наличием у некоторых исследователей-социологов какой-то психологической "заслонки", которая мешает правильно воспринять сущность социологического измерения. И анализ некоторых аспектов метода одномерного развертывания, как нам кажется, позволяет эту "заслонку" ликвидировать. Поясним это соображение.
Наш опыт говорит о том, что исследователи иногда не воспринимают полученное с помощью метода одномерного развертывания расположение объектов на оси как результат измерения. Исследователь недоумевает: как можно расценивать подобным образом ситуацию, когда мы абсолютно не знаем, в каком месте числовой оси каждый объект находится. Единственно, что нам известно, это то, что один объект левее, другой правее (на сколько — не ясно !), третий — еще правее и т.д. И в то же время тот же самый исследователь вполне спокойно воспринимает сообщение о том, что, скажем, числа — ответы респондентов на традиционный вопрос об удовлетворенности работой можно считать полученными по порядковой шкале. И даже согласится с тем, что эти числа определены с точностью до порядка их расположения. А ведь указанная неоднозначность того расположения объектов, которое мы получаем с помощью метода одномерного развертывания, — это то же самое, только представленное в наглядном, "бьющем в глаза" виде.
Суть порядковых шкал заключается в том, что вместо набора чисел (1, 2, 3, 4, 5) могут фигурировать, скажем, числа (1, 43, 44, 100, 538). Однако констатация этого обычно вызывает возражение, поскольку в последней пятерке чисел различие между четвертым и пятым много больше различия между первым и вторым и т.д. Но это возражение несостоятельно. Оно означает принятие предположения об интервальное™ той шкалы, по которой получен набор (1, 2, 3, 4, 5), т.е. осмысленность соотношений между интервалами, чего на самом деле нет.
То, что даже при порядковом уровне измерения в практических исследованиях фигурирует последний названный нами набор чисел (с равными интервалами!), как бы затеняет истинную сущность шкалы, состоящую в том, что полученные с ее помощью шкальные значения определены только с точностью до порядка! Кумбсовский же подход, напротив, эту сущность высвечивает.
Далее, с методической точки зрения важно еще раз обратить внимание на то, что одномерное развертывание дает возможность измерять нетрадиционные отношения между объектами (частичное упорядочение расстояний между ними).
Социолог, как правило, не задумывается о том, что в тех случаях, когда приписать объектам числа по интервальной шкале не удается (напомним, что интервальность шкалы означает осмысленность структуры межобъектных расстояний), иногда все же бывает полезно получить хотя бы какие-нибудь соотношения для расстояний между объектами. Так, в дополнение к ранжировке телепередач неплохо было бы узнать, что, скажем, такие-то две передачи вызывают примерно одинаковый зрительский интерес, а вот две другие совершенно по-разному воспринимаются изучаемой аудиторией.