Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 412
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
-
для корректировки синаптических весов на второй итерации алгоритма обучения следует вычислить
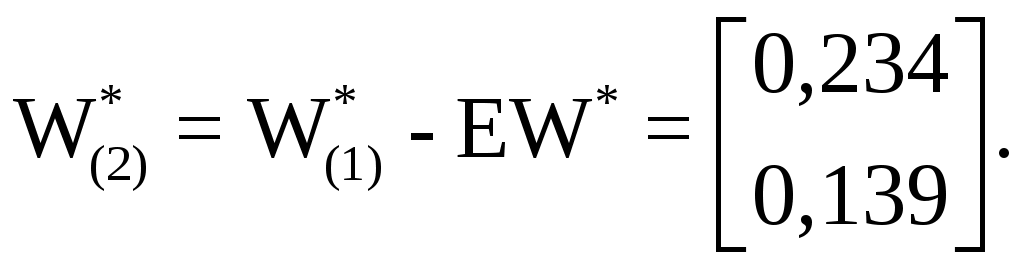
Далее вычисляются поправочные коэффициенты EW для синапти-ческой матрицы скрытого слоя и значения
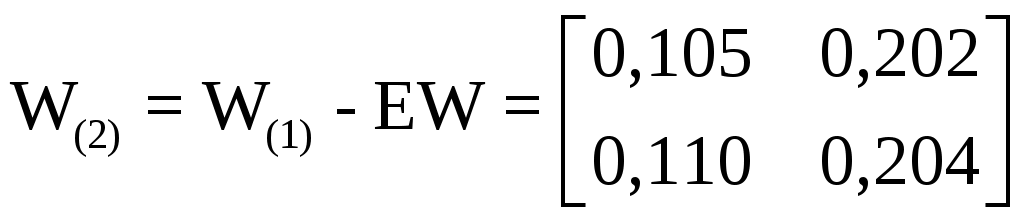 .
.Второй прямой проход выполняется, чтобы определить, насколько рассматриваемая сеть близка к поставленной цели. В результате повторного просчета с синаптическими матрицами
За n итераций нейронная сеть будет обучена.
Глава 7. Агенты и мультиагентные системы
7.1. Интеллектуальные агенты
Проблематика интеллектуальных агентов и мультиагентных систем (МАС) имеет почти 40-летнюю историю и сформировалась на основе результатов, полученных в рамках работ по распределенному ИИ (DAI), распределенному решению задач (DPS) и параллельному ИИ (PAI). Данная тематика интегрирует достижения в области компьютерных сетей и открытых систем, ИИ и информационных технологий [15,16,21].
Агент – это аппаратная или программная сущность, способная действовать в интересах достижения целей, поставленных перед ним владельцем или пользователем.
Таким образом, в рамках МАС-парадигмы программные агенты рассматриваются как автономные компоненты, действующие от лица пользователя.
Интеллектуальным агентам должны быть присущи следующие свойства:
автономность – способность функционировать без вмешательства со стороны своего владельца и осуществлять контроль внутреннего состояния и своих действий;
социальное поведение – возможность взаимодействия и коммуни-кации с другими агентами;
реактивность – адекватное восприятие среды и соответствующие реакции на ее изменения;
активность – способность генерировать цели и действовать рацио-нальным образом для их достижения;
базовые знания – знания агента о себе, окружающей среде, включая других агентов, которые не меняются в рамках ЖЦ агента;
убеждения – переменная часть базовых знаний, которые могут меняться во времени, хотя агент может об этом не знать и продолжать их использовать для своих целей;
цели – совокупность состояний, на достижение которых направлено текущее поведение агента;
желания – состояния или ситуации, достижение которых для агента важно;
обязательства – задачи, решение которых берет на себя агент по просьбе других агентов;
намерения – то, что агент должен делать в силу своих обязательств.
В зависимости от концепций, выбранных для организации МАС, обычно выделяются три базовых класса архитектур:
базирующиеся на принципах и методах работы со знаниями;
основанные на поведенческих моделях типа «стимул – реакция»;
гибридные.
Архитектуру или агентов, которые используют только точное представление картины мира в символьной форме и принимают решения на основе формальных рассуждений и использования методов сравнения по образцу, принято определять как делиберативные (первый подход).
Реактивными называются агенты и архитектуры, в которых функционирование отдельных агентов и всей системы осуществляется по правилам типа «ситуация – действие». При этом под ситуацией понимается потенциально сложная комбинация внутренних и внешних состояний (второй подход).
Для решения реальных задач используются гибридные архитектуры.
Развитие и внедрение программных агентов было бы невозможно без опыта разработки открытых систем, для которых характерны:
расширяемость/масштабируемость (возможность изменения набора составляющих систем);
мобильность/переносимость (простота переноса ПС на разные аппаратно-программные платформы);
интероперабельность (способность к взаимодействию с другими системами);
дружелюбность, легкая управляемость.
Одним из результатов внедрения концепции открытых систем в практику стало распространение архитектуры «клиент – сервер». В настоя-щее время выделяются следующие модели клиент-серверного взаимо-действия:
«толстый клиент – тонкий сервер». Серверная часть реализует только доступ к ресурсам, а основная часть приложения находится на клиенте;
«тонкий клиент – толстый сервер». Модель активно используется в связи с распространением интернет-технологий. Клиентское приложение обеспечивает реализацию интерфейса, а сервер объединяет остальные части приложений.
Мобильные агенты – это программы, которые могут перемещаться по сети. Они покидают клиентский компьютер и перемещаются на удаленный сервер для выполнения своих действий, после чего воз-вращаются обратно.
Мобильные агенты являются перспективными для МАС, но в настоящее время отсутствуют единые стандарты их разработки и остается нерешенным ряд проблем, таких как легальные способы перемещения по сети, верификация агентов (защита от передаваемых по сети вирусов), соблюдение агентами прав частной собственности и сохранение кон-фиденциальности информации, которой они обладают, перенаселение сети агентами.
С точки зрения разработки и реализации МАС наиболее эффектив-ными системами поддержки распределенных технологий являются DCOM, Java RMI, COBRA.
Основная ценность DCOM – предоставление возможности ин-теграции приложений, реализованных в разных системах программи-рования.
Java RMI-приложения обычно состоят из клиента и сервера. При этом на сервере создаются объекты, которые можно передавать по сети, либо методы, доступные для вызова удаленными приложениями, а на клиенте реализуются приложения, пользующиеся удаленными объектами. Отличительной чертой RMI является возможность передачи в сети не только методов, но и самих объектов, что обеспечивает в конечном счете реализацию мобильных агентов.
Основным преимуществом COBRA является интерфейс IDL, уни-фицирующий средства коммуникации между приложениями.
Агентом является все, что может воспринимать свою среду с по-мощью датчиков и воздействовать на нее через исполнительные механизмы (человек, робот, программа). Каждый агент может воспри-нимать собственные действия.
Выбор агентом действия в любой конкретный момент может зависеть от всей последовательности актов восприятия, наблюдавшихся
до этого времени. Поведение агента может быть описано и с помощью функции агента, которая отображает любую конкретную последователь-ность актов восприятия на некоторое действие. Внешним описанием агента может служить таблица. Внутреннее описание состоит в опре-делении того, какая функция агента реализуется с помощью программы агента, то есть конкретная реализация, действующая в рамках архитектуры агента.
В любой конкретный момент времени оценка рациональности дей-ствий агента зависит:
от показателей производительности;
знаний агента о среде, приобретенных ранее;
действий, которые могут быть выполнены агентом;
последовательности актов восприятия агента по состоянию на текущий момент.
Рациональный агент должен иметь способность к обучению и быть автономным.
Под проблемной средой агента понимается совокупность показа-телей производительности, среда, исполнительные механизмы и датчики.
Пример 7.1. Проблемная среда водителя такси:
| Тип агента | Показатели производительности | Среда | Исполнительные механизмы | Датчики |
| Водитель такси | Безопасная, быстрая езда в рамках правил, максимизация прибыли | Дороги, дру-гие транс-портные средства, пешеходы, клиенты | Рулевое управ-ление, газ, тор- моз, световые сигналы, зву- ковые сигналы, дисплей | Видеокамеры, ультразвуко- вой дальномер, система нави-гации, датчики двигателя |
Программные агенты (программные роботы, софтботы) существуют в сложных неограниченных проблемных областях. Например, софтбот для управления тренажером, имитирующим пассажирский самолет, морское судно, или софтбот, предназначенный для просмотра источников новостей в Интернете и показа клиентам интересующих их сообщений. Интернет представляет собой среду, которая по своей сложности соперничает с физическим миром, а в число обитателей этой сети входит множество искусственных агентов.
Классификация вариантов проблемной среды:
наблюдаемая полностью/частично (полностью, если датчики фикси-руют все необходимые данные);
детерминированная/стохастическая. Если следующее состояние среды определяется текущим и действием агента, то среда детерминированная;
эпизодическая/последовательная: в эпизодической среде опыт агента состоит из неразрывных эпизодов. Каждый эпизод включает в себя:
восприятие среды агентом, а затем выполнение одного действия
(распознавание дефектных деталей) в последовательных средах.
статическая/динамическая: если среда может измениться в ходе принятия агентом решения, то она является динамической;
дискретная/непрерывная: игра в шахматы дискретная; вождение автомобиля – непрерывная;
одноагентная/многоагентная (мультиагентная): решение кроссворда, одноагентная; игра в шахматы, вождение автомобиля – многоагентная.
Задача искусственного интеллекта состоит в разработке про-граммы агента, которая реализует функцию агента, отображая вос-приятия на действия. Предполагается, что программа должна работать в своего рода вычислительном устройстве с физическими датчиками и ис-полнительными механизмами. Эти компоненты составляют архитектуру агента:
агент = архитектура + программа.
Архитектура может представлять собой персональный компьютер или роботизированный автомобиль.
В основе почти всех интеллектуальных систем лежат четыре основ-ных вида программных агентов:
простые рефлексивные;
рефлексивные, основанные на модели;
действующие на основе цели;
действующие на основе полезности.
Простейшим видом является простой рефлексивный агент, который выбирает действия на основе текущего акта восприятия, игнорируя всю остальную историю актов восприятия. Агент – пылесос: решения основаны только на информации о текущем местоположении и о том, содержит ли оно мусор.
Наиболее эффективный способ организации работы в условиях частичной наблюдаемости состоит в том, чтобы агент отслеживал ту часть ситуации, которая воспринимается им в текущий момент. Это означает, что агент должен поддерживать внутреннее состояние, зависящее от предыстории. Для обеспечения возможности обновления внутренней информации о состоянии среды в программе агента должны быть закодированы знания двух видов. Во-первых, нужна информация о том, как изменяется внешняя среда независимо от агента. Во-вторых, требуется определенная информация о влиянии действий агента на среду. Знания о том, как работает среда, называются моделью мира. Агент, в котором используется такая модель, называется агентом, основанным на модели.
Знаний о текущем состоянии среды не всегда достаточно для принятия решения. На перекрестке такси может ехать прямо, направо, налево. Правильное решение – место назначения клиента, т.е. кроме текущего состояния агенту необходимо знать цель. Инструментом для выработки последовательности действий, позволяющих агенту достичь цели, являются поиск и планирование.
Программа агента может комбинировать информацию о цели с информацией о результатах возможных действий. Такие агенты получили название агентов, действующих на основе цели.
Функция полезности отображает состояние на вещественное число, которое обозначает соответствующую степень удовлетворенности агента. Полная спецификация функции полезности обеспечивает возможность принимать рациональные решения, если имеются конфликтующие цели (скорость и безопасность) или несколько целей, к которым может стремиться агент, но ни одна из них не может быть достигнута со всей определенностью. Такие агенты получили название агентов, действую-щих на основе полезности.