ВУЗ: Казахская Национальная Академия Искусств им. Т. Жургенова
Категория: Книга
Дисциплина: Не указана
Добавлен: 03.02.2019
Просмотров: 21713
Скачиваний: 19

7-31
Chapter
7.2
ATSC DTV System Compression Issues
Jerry C. Whitaker, Editor-in-Chief
7.2.1
Introduction
The primary application of interest when the MPEG-2 standard was first defined was “true” tele-
vision broadcast resolution, as specified by ITU-R Rec. 601. This is roughly four times more
picture information than the MPEG-1 standard provides. MPEG-2 is a superset, or extension, of
MPEG-1. As such, an MPEG-2 decoder also should be able to decode an MPEG-1 stream. This
broadcast version adds to the MPEG-1 toolbox provisions for dealing with interlace, graceful
degradation, and hierarchical coding.
Although MPEG-1 and MPEG-2 each were specified with a particular range of applications
and resolutions in mind, the committee’s specifications form a set of techniques that support
multiple coding options, including picture types and macroblock types. Many variations exist
with regard to picture size and bit rates. Also, although MPEG-1 can run at high bit rates and at
full ITU-R Rec. 601 resolution, it processes frames, not fields. This fact limits the attainable
quality, even at data rates approaching 5 Mbits/s.
The MPEG specifications apply only to decoding, not encoding. The ramifications of this
approach are:
•
Owners of existing decoding software can benefit from future breakthroughs in encoding pro-
cessing. Furthermore, the suppliers of encoding equipment can differentiate their products by
cost, features, encoding quality, and other factors.
•
Different schemes can be used in different situations. For example, although Monday Night
Football must be encoded in real time, a film can be encoded in non-real time, allowing for
fine-tuning of the parameters via computer or even a human operator.
7.2.2
MPEG-2 Layer Structure
To allow for a simple yet upgradable system, MPEG-2 defines only the functional elements—
syntax and semantics—of coded streams. Using the same system of I-, P-, and B-frames devel-
oped for MPEG-1, MPEG-2 employs a 6-layer hierarchical structure that breaks the data into
simplified units of information, as given in Table 7.2.1.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
Source: Standard Handbook of Audio and Radio Engineering

7-32 Compression Technologies for Audio
The top sequence layer defines the decoder constraints by specifying the context of the video
sequence. The sequence-layer data header contains information on picture format and applica-
tion-specific details. The second level allows for random access to the decoding process by hav-
ing a periodic series of pictures; it is fundamentally this GOP layer that provides the bidirectional
frame prediction. Intraframe-coded (I) frames are the entry-point frames, which require no data
from other frames in order to reconstruct. Between the I-frames lie the predictive (P) frames,
which are derived from analyzing previous frames and performing motion estimation. These P-
frames require about one-third as many bits per frame as I-frames. B-frames, which lie between
two I-frames or P-frames, are bidirectionally encoded, making use of past and future frames. The
B-frames require only about one-ninth of the data per frame, compared with I-frames.
These different compression ratios for the frames lead to different data rates, so that buffers
are required at both the encoder output and the decoder input to ensure that the sustained data
rate is constant. One difference between MPEG-1 and MPEG-2 is that MPEG-2 allows for a
variety of data-buffer sizes, to accommodate different picture dimensions and to prevent buffer
under- and overflows.
The data required to decode a single picture is embedded in the picture layer, which consists
of a number of horizontal slice layers, each containing several macroblocks. Each macroblock
layer, in turn, is made up of a number of individual blocks. The picture undergoes DCT process-
ing, with the slice layer providing a means of synchronization, holding the precise position of the
slice within the image frame.
MPEG-2 places the motion vectors into the coded macroblocks for P- and B- frames; these
are used to improve the reconstruction of predicted pictures. MPEG-2 supports both field- and
frame-based prediction, thus accommodating interlaced signals.
The last layer of MPEG-2’s video structure is the block layer, which provides the DCT coeffi-
cients of either the transformed image information for I-frames or the residual prediction error of
B- and P- frames.
7.2.2a
Slices
Two or more contiguous macroblocks within the same row are grouped together to form slices
[1]. The order of the macroblocks within a slice is the same as the conventional television raster
scan, being from left to right.
Slices provide a convenient mechanism for limiting the propagation of errors. Because the
coded bit stream consists mostly of variable-length code words, any uncorrected transmission
Table 7.2.1 Layers of the MPEG-2 Video Bit-Stream Syntax
Syntax layer
Functionality
Video sequence layer
Context unit
Group of pictures (GOP) layer
Random access unit: video coding
Picture layer
Primary coding unit
Slice layer
Resynchronization unit
Macroblock layer
Motion-compensation unit
Block layer
DCT unit
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues
ATSC DTV System Compression Isues 7-33
errors will cause a decoder to lose its sense of code word alignment. Each slice begins with a
slice start code. Because the MPEG code word assignment guarantees that no legal combination
of code words can emulate a start code, the slice start code can be used to regain the sense of
code-word alignment after an error. Therefore, when an error occurs in the data stream, the
decoder can skip to the start of the next slice and resume correct decoding.
The number of slices affects the compression efficiency; partitioning the data stream to have
more slices provides for better error recovery, but claims bits that could otherwise be used to
improve picture quality.
In the DTV system, the initial macroblock of every horizontal row of macroblocks is also the
beginning of a slice, with a possibility of several slices across the row.
7.2.2b
Pictures, Groups of Pictures, and Sequences
The primary coding unit of a video sequence is the individual video frame or picture [1]. A video
picture consists of the collection of slices, constituting the active picture area.
A video sequence consists of a collection of two or more consecutive pictures. A video
sequence commences with a sequence header and is terminated by an end-of-sequence code in
the data stream. A video sequence may contain additional sequence headers. Any video-
sequence header can serve as an entry point. An entry point is a point in the coded video bit
stream after which a decoder can become properly initialized and correctly parse the bit-stream
syntax.
Two or more pictures (frames) in sequence may be combined into a GOP to provide bound-
aries for interframe picture coding and registration of time code. GOPs are optional within both
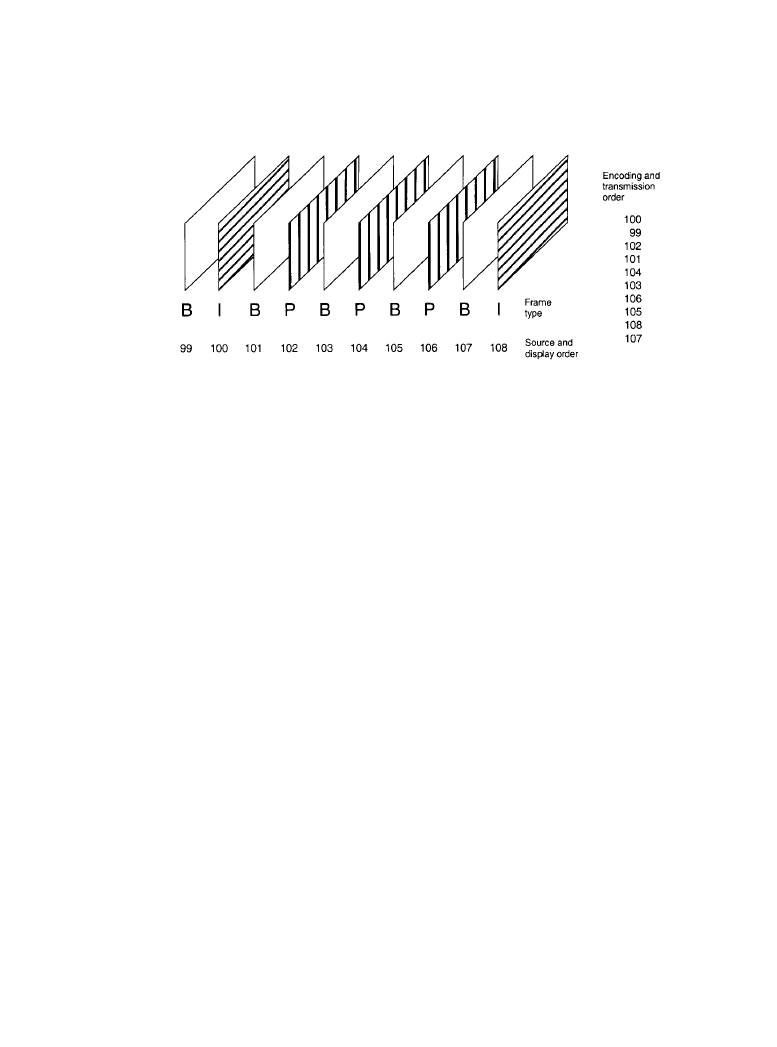
MPEG-2 and the ATSC DTV system. Figure 7.2.1 illustrates a typical time sequence of video
frames.
Figure 7.2.1
Sequence of video frames for the MPEG-2/ATSC DTV system. (
From [1]. Used with
permission.)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

7-34 Compression Technologies for Audio
I-Frames
Some elements of the compression process exploit only the spatial redundancy within a single
picture (frame or field) [1]. These processes constitute intraframe coding, and do not take advan-
tage of the temporal correlation addressed by temporal prediction (interframe) coding. Frames
that do not use any interframe coding are referred to as I-frames (where “I” denotes intraframe-
coded). The ATSC video-compression system utilizes both intraframe and interframe coding.
The use of periodic I-frames facilitates receiver initializations and channel acquisition (for
example, when the receiver is turned on or the channel is changed). The decoder also can take
advantage of the intraframe coding mode when noncorrectable channel errors occur. With
motion-compensated prediction, an initial frame must be available at the decoder to start the pre-
diction loop. Therefore, a mechanism must be built into the system so that if the decoder loses
synchronization for any reason, it can rapidly reacquire tracking.
The frequency of occurrence of I-pictures may vary and is selected at the encoder. This allows
consideration to be given to the need for random access and the location of scene cuts in the
video sequence.
P-Frames
P-frames, where the temporal prediction is in the forward direction only, allow the exploitation
of interframe coding techniques to improve the overall compression efficiency and picture qual-
ity [1]. P-frames may include portions that are only intraframe-coded. Each macroblock within a
P-frame can be either forward-predicted or intraframe-coded.
B-Frames
The B-frame is a picture type within the coded video sequence that includes prediction from a
future frame as well as from a previous frame [1]. The referenced future or previous frames,
sometimes called anchor frames, are in all cases either I- or P-frames.
The basis of the B-frame prediction is that a video frame is correlated with frames that occur
in the past as well as those that occur in the future. Consequently, if a future frame is available to
the decoder, a superior prediction can be formed, thus saving bits and improving performance.
Some of the consequences of using future frames in the prediction are:
•
The B-frame cannot be used for predicting future frames.
•
The transmission order of frames is different from the displayed order of frames.
•
The encoder and decoder must reorder the video frames, thereby increasing the total latency.
In the example illustrated in Figure 7.2.1, there is one B-frame between each pair of I- and P-
frames. Each frame is labeled with both its display order and transmission order. The I and P
frames are transmitted out of sequence, so the video decoder has both anchor frames decoded
and available for prediction.
B-frames are used for increasing the compression efficiency and perceived picture quality
when encoding latency is not an important factor. The use of B-frames increases coding effi-
ciency for both interlaced- and progressive-scanned material. B-frames are included in the DTV
system because the increase in compression efficiency is significant, especially with progressive
scanning. The choice of the number of bidirectional pictures between any pair of reference (I or
P) frames can be determined at the encoder.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

ATSC DTV System Compression Isues 7-35
Motion Estimation
The efficiency of the compression algorithm depends on, first, the creation of an estimate of the
image being compressed and, second, subtraction of the pixel values of the estimate or prediction
from the image to be compressed [1]. If the estimate is good, the subtraction will leave a very
small residue to be transmitted. In fact, if the estimate or prediction were perfect, the difference
would be zero for all the pixels in the frame of differences, and no new information would need
to be sent; this condition can be approached for still images.
If the estimate is not close to zero for some pixels or many pixels, those differences represent
information that needs to be transmitted so that the decoder can reconstruct a correct image. The
kinds of image sequences that cause large prediction differences include severe motion and/or
sharp details.
7.2.2c
Vector Search Algorithm
The video-coding system uses motion-compensated prediction as part of the data-compression
process [1]. Thus, macroblocks in the current frame of interest are predicted by macroblock-
sized regions in previously transmitted frames. Motion compensation refers to the fact that the
locations of the macroblock-sized regions in the reference frame can be offset to account for
local motions. The macroblock offsets are known as motion vectors.
The DTV standard does not specify how encoders should determine motion vectors. One pos-
sible approach is to perform an exhaustive search to identify the vertical and horizontal offsets
that minimize the total difference between the offset region in the reference frame and the mac-
roblock in the frame to be coded.
7.2.2d
Motion-Vector Precision
The estimation of interframe displacement is calculated with half-pixel precision, in both vertical
and horizontal dimensions [1]. As a result, the displaced macroblock from the previous frame
can be displaced by noninteger displacements and will require interpolation to compute the val-
ues of displaced picture elements at locations not in the original array of samples. Estimates for
half-pixel locations are computed by averages of adjacent sample values.
7.2.2e
Motion-Vector Coding
Motion vectors within a slice are differenced, so that the first value for a motion vector is trans-
mitted directly, and the following sequence of motion-vector differences is sent using variable-
length codes (VLC) [1]. Motion vectors are constrained so that all pixels from the motion-com-
pensated prediction region in the reference picture fall within the picture boundaries.
7.2.2f
Encoder Prediction Loop
The encoder prediction loop, shown in the simplified block diagram of Figure 7.2.2, is the heart
of the video-compression system for DTV [1]. The prediction loop contains a prediction function
that estimates the picture values of the next picture to be encoded in the sequence of successive
pictures that constitute the TV program. This prediction is based on previous information that is
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues