ВУЗ: Казахская Национальная Академия Искусств им. Т. Жургенова
Категория: Книга
Дисциплина: Не указана
Добавлен: 03.02.2019
Просмотров: 21712
Скачиваний: 19
7-36 Compression Technologies for Audio
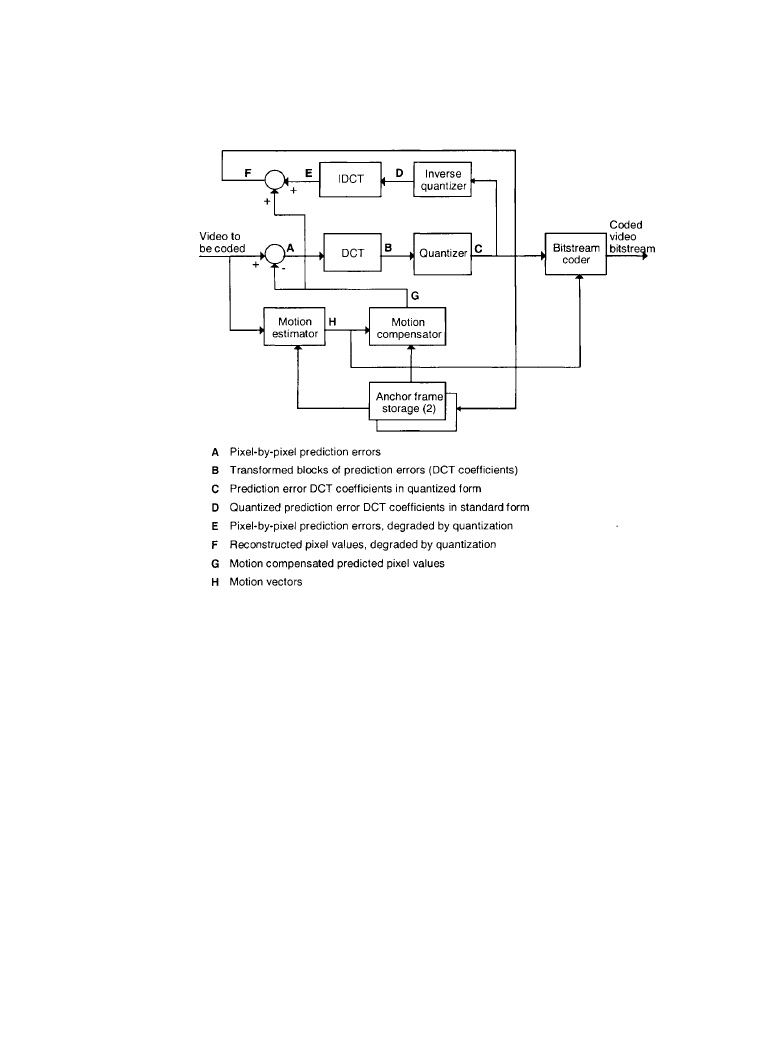
available within the loop, derived from earlier pictures. The transmission of the predicted com-
pressed information works because the same information used to make the prediction also is
available at the receiving decoder (barring transmission errors, which are usually infrequent
within the primary coverage area).
The subtraction of the predicted picture values from the new picture to be coded is at the core
of predictive coding. The goal is to do such a good job of predicting the new values that the result
of the subtraction function at the beginning of the prediction loop is zero or close to zero most of
the time.
The prediction differences are computed separately for the luminance and two chrominance
components before further processing. As explained in previous discussion of I-frames, there are
times when prediction is not used, for part of a frame or for an entire frame.
Figure 7.2.2
Simplified encoder prediction loop. (
From [1]. Used with permission.)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

ATSC DTV System Compression Isues 7-37
Spatial Transform Block—DCT
The image prediction differences (sometimes referred to as prediction errors) are organized into
8
× 8 blocks, and a spatial transform is applied to the blocks of difference values [1]. In the
intraframe case, the spatial transform is applied to the raw, undifferenced picture data. The lumi-
nance and two chrominance components are transformed separately. Because the chrominance
data is subsampled vertically and horizontally, each 8
× 8 block of chrominance (C
b
or C
r
) data
corresponds to a 16
× 16 macroblock of luminance data, which is not subsampled.
The spatial transform used is the discrete cosine transform. The formula for transforming the
data is given by:
(7.2.1)
where x and y are pixel indices within an 8
× 8 block, u and v are DCT coefficient indices within
an 8
× 8 block, and:
for w = 0
(7.2.2)
for w = 1, 2, ..., 7
(7.2.3)
Thus, an 8
× 8 array of numbers f(x, y) is the input to a mathematical formula, and the output is
an 8
× 8 array of different numbers, F(u, v). The inverse transform is given by:
(7.2.4)
It should be noted that for the DTV implementation, the inverse discrete cosine transform
(IDCT) must conform to the specifications noted in [2].
In principle, applying the IDCT to the transformed array would yield exactly the same array
as the original. In that sense, transforming the data does not modify the data, but merely repre-
sents it in a different form.
The decoder uses the inverse transformation to approximately reconstruct the arrays that were
transformed at the encoder, as part of the process of decoding the received compressed data. The
approximation in that reconstruction is controlled in advance during the encoding process for the
purpose of minimizing the visual effects of coefficient inaccuracies while reducing the quantity
of data that needs to be transmitted.
Quantizer
The process of transforming the original data organizes the information in a way that exposes the
spatial frequency components of the images or image differences [1]. Using information about
F u v
,
(
)
1
4
---C u
( )C v
( )
f x y
,
(
)
2x
1
+
(
)uπ
16
---------------------------
2y
1
+
(
)vπ
16
--------------------------
cos
cos
y
0
=
7
∑
x
0
=
7
∑
=
C w
( )
1
2
-------
=
C w
( )
1
=
f x y
,
(
)
1
4
---
C u
( )C v
( )F u v
,
(
)
2x
1
+
(
)uπ
16
---------------------------
2y
1
+
(
)vπ
16
--------------------------
cos
cos
v
0
=
7
∑
u
0
=
7
∑
=
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

7-38 Compression Technologies for Audio
the response of the human visual system to different spatial frequencies, the encoder can selec-
tively adjust the precision of transform coefficient representation. The goal is to include as much
information about a particular spatial frequency as necessary—and as possible, given the con-
straints on data transmission—while not using more precision than is needed, based upon visual
perception criteria.
For example, in a portion of a picture that is “busy” with a great deal of detail, imprecision in
reconstructing spatial high-frequency components in a small region might be masked by the pic-
ture’s local “busyness.” On the other hand, highly precise representation and reconstruction of
the average value or dc term of the DCT block would be important in a smooth area of sky. The
dc F(0,0) term of the transformed coefficients represents the average of the original 64 coeffi-
cients.
As stated previously, the DCT of each 8
× 8 block of pixel values produces an 8 × 8 array of
DCT coefficients. The relative precision accorded to each of the 64 DCT coefficients can be
selected according to its relative importance in human visual perception. The relative coefficient
precision information is represented by a quantizer matrix, which is an 8
× 8 array of values.
Each value in the quantizer matrix represents the coarseness of quantization of the related DCT
coefficient.
Two types of quantizer matrices are supported:
•
A matrix used for macroblocks that are intraframe-coded
•
A matrix used for non-intraframe-coded macroblocks
The video-coding system defines default values for both the intraframe-quantizer and the non-
intraframe-quantizer matrices. Either or both of the quantizer matrices can be overridden at the
picture level by transmission of appropriate arrays of 64 values. Any quantizer matrix overrides
stay in effect until the following sequence start code.
The transform coefficients, which represent the bulk of the actual coded video information,
are quantized to various degrees of coarseness. As indicated previously, some portions of the pic-
ture will be more affected in appearance than others by the loss of precision through coefficient
quantization. This phenomenon is exploited by the availability of the quantizer scale factor,
which allows the overall level of quantization to vary for each macroblock. Consequently, entire
macroblocks that are deemed to be visually less important can be quantized more coarsely,
resulting in fewer bits being needed to represent the picture.
For each coefficient other than the dc coefficient of intraframe-coded blocks, the quantizer
scale factor is multiplied by the corresponding value in the appropriate quantizer matrix to form
the quantizer step size. Quantization of the dc coefficients of intraframe-coded blocks is unaf-
fected by the quantizer scale factor and is governed only by the (0, 0) element of the intraframe-
quantizer matrix, which always is set to be 8 (ISO/IEC 13818-2).
Entropy Coder
An important effect of the quantization of transform coefficients is that many coefficients will be
rounded to zero after quantization [1]. In fact, a primary method of controlling the encoded data
rate is the control of quantization coarseness, because a coarser quantization leads to an increase
in the number of zero-value quantized coefficients.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

ATSC DTV System Compression Isues 7-39
Inverse Quantizer
At the decoder, the coded coefficients are decoded, and an 8
× 8 block of quantized coefficients
is reconstructed [1]. Each of these 64 coefficients is inverse-quantized according to the prevail-
ing quantizer matrix, quantizer scale, and frame type. The result of inverse quantization is a
block of 64 DCT coefficients.
Inverse Spatial Transform Block—IDCT
The decoded and inverse-quantized coefficients are organized as 8
× 8 blocks of DCT coeffi-
cients, and the inverse discrete cosine transform is applied to each block [1]. This results in a
new array of pixel values, or pixel difference values that correspond to the output of the subtrac-
tion at the beginning of the prediction loop. If the prediction loop was in the interframe mode, the
values will be pixel differences. If the loop was in the intraframe mode, the inverse transform
will produce pixel values directly.
Motion Compensator
If a portion of the image has not moved, then it is easy to see that a subtraction of the old portion
from the new portion of the image will produce zero or nearly zero pixel differences, which is the
goal of the prediction [1]. If there has been movement in the portion of the image under consid-
eration, however, the direct pixel-by-pixel differences generally will not be zero, and might be
statistically very large. The motion in most natural scenes is organized, however, and can be
approximately represented locally as a translation in most cases. For this reason, the video-cod-
ing system allows for motion-compensated prediction, whereby macroblock-sized regions in the
reference frame may be translated vertically and horizontally with respect to the macroblock
being predicted, to compensate for local motion.
The pixel-by-pixel differences between the current macroblock and the motion-compensated
prediction are transformed by the DCT and quantized using the composition of the non-
intraframe-quantizer matrix and the quantizer scale factor. The quantized coefficients then are
coded.
7.2.2g
Dual Prime Prediction Mode
The dual prime prediction mode is an alternative “special” prediction mode that is built on field-
based motion prediction but requires fewer transmitted motion vectors than conventional field-
based prediction [1]. This mode of prediction is available only for interlaced material and only
when the encoder configuration does not use B-frames. This mode of prediction can be particu-
larly useful for improving encoder efficiency for low-delay applications.
The basis of dual prime prediction is that field-based predictions of both fields in a macrob-
lock are obtained by averaging two separate predictions, which are predicted from the two near-
est decoded fields in time. Each of the macroblock fields is predicted separately, although the
four vectors (one pair per field) used for prediction all are derived from a single transmitted
field-based motion vector. In addition to the single field-based motion vector, a small differential
vector (limited to vertical and horizontal component values of +1, 0, and –1) also is transmitted
for each macroblock. Together, these vectors are used to calculate the pairs of motion vectors for
each macroblock. The first prediction in the pair is simply the transmitted field-based motion
vector. The second prediction vector is obtained by combining the differential vector with a
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

7-40 Compression Technologies for Audio
scaled version of the first vector. After both predictions are obtained, a single prediction for each
macroblock field is calculated by averaging each pixel in the two original predictions. The final
averaged prediction then is subtracted from the macroblock field being encoded.
7.2.2h
Adaptive Field/Frame Prediction Mode
Interlaced pictures may be coded in one of two ways: either as two separate fields or as a single
frame [1]. When the picture is coded as separate fields, all of the codes for the first field are
transmitted as a unit before the codes for the second field. When the picture is coded as a frame,
information for both fields is coded for each macroblock.
When frame-based coding is used with interlaced pictures, each macroblock may be selectively
coded using either field prediction or frame prediction. When frame prediction is used, a motion vec-
tor is applied to a picture region that is made up of both parity fields interleaved together. When field
prediction is used, a motion vector is applied to a region made up of scan lines from a single field.
Field prediction allows the selection of either parity field to be used as a reference for the field
being predicted.
7.2.2i
Image Refresh
As discussed previously, a given picture may be sent by describing the differences between it and
one or two previously transmitted pictures [1]. For this scheme to work, there must be some way
for decoders to become initialized with a valid picture upon tuning into a new channel, or to
become reinitialized with a valid picture after experiencing transmission errors. Additionally, it
is necessary to limit the number of consecutive predictions that can be performed in a decoder to
control the buildup of errors resulting from IDCT mismatch.
IDCT mismatch occurs because the video-coding system, by design, does not completely
specify the results of the IDCT operation. MPEG did not fully specify the results of the IDCT to
allow for evolutionary improvements in implementations of this computationally intensive oper-
ation. As a result, it is possible for the reconstructed pictures in a decoder to “drift” from those in
the encoder if many successive predictions are used, even in the absence of transmission errors.
To control the amount of drift, each macroblock is required to be coded without prediction
(intraframe-coded) at least once in any 132 consecutive frames.
The process whereby a decoder becomes initialized or reinitialized with valid picture data—
without reference to previously transmitted picture information—is termed image refresh. Image
refresh is accomplished by the use of intraframe-coded macroblocks. The two general classes of
image refresh, which can be used either independently or jointly, are:
•
Periodic transmission of I-frames
•
Progressive refresh
Periodic Transmission of I-Frames
One simple approach to image refresh is to periodically code an entire frame using only
intraframe coding [1]. In this case, the intra-coded frame is typically an I-frame. Although pre-
diction is used within the frame, no reference is made to previously transmitted frames. The
period between successive intracoded frames may be constant, or it may vary. When a receiver
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues