ВУЗ: Казахская Национальная Академия Искусств им. Т. Жургенова
Категория: Книга
Дисциплина: Не указана
Добавлен: 03.02.2019
Просмотров: 21717
Скачиваний: 19

ATSC DTV System Compression Isues 7-41
tunes into a new channel where I-frame coding is used for image refresh, it may perform the fol-
lowing steps:
•
Ignore all data until receipt of the first sequence header
•
Decode the sequence header, and configure circuits based on sequence parameters
•
Ignore all data until the next received I-frame
•
Commence picture decoding and presentation
When a receiver processes data that contains uncorrectable errors in an I- or P-frame, there
typically will be a propagation of picture errors as a result of predictive coding. Pictures received
after the error may be decoded incorrectly until an error-free I-frame is received.
Progressive Refresh
An alternative method for accomplishing image refresh is to encode only a portion of each pic-
ture using the intraframe mode [1]. In this case, the intraframe-coded regions of each picture
should be chosen in such a way that, over the course of a reasonable number of frames, all mac-
roblocks are coded intraframe at least once. In addition, constraints might be placed on motion-
vector values to avoid possible contamination of refreshed regions through predictions using
unrefreshed regions in an uninitialized decoder.
7.2.2j
Discrete Cosine Transform
Predictive coding in the MPEG-2 compression algorithm exploits the temporal correlation in the
sequence of image frames [1]. Motion compensation is a refinement of that temporal prediction,
which allows the coder to account for apparent motions in the image that can be estimated. Aside
from temporal prediction, another source of correlation that represents redundancy in the image
data is the spatial correlation within an image frame or field. This spatial correlation of images,
including parts of images that contain apparent motion, can be accounted for by a spatial trans-
form of the prediction differences. In the intraframe-coding case, where there is by definition no
attempt at prediction, the spatial transform applies to the actual picture data. The effect of the
spatial transform is to concentrate a large fraction of the signal energy in a few transform coeffi-
cients.
To exploit spatial correlation in intraframe and predicted portions of the image, the image-
prediction residual pixels are represented by their DCT coefficients. For typical images, a large
fraction of the energy is concentrated in a few of these coefficients. This makes it possible to
code only a few coefficients without seriously affecting the picture quality. The DCT is used
because it has good energy-compaction properties and results in real coefficients. Furthermore,
numerous fast computational algorithms exist for implementation of DCT.
Blocks of 8
× 8 Pixels
Theoretically, a large DCT will outperform a small DCT in terms of coefficient decorrelation
and block energy compaction [1]. Better overall performance can be achieved, however, by sub-
dividing the frame into many smaller regions, each of which is individually processed.
If the DCT of the entire frame is computed, the whole frame is treated equally. For a typical
image, some regions contain a large amount of detail, and other regions contain very little.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

7-42 Compression Technologies for Audio
Exploiting the changing characteristics of different images and different portions of the same
image can result in significant improvements in performance. To take advantage of the varying
characteristics of the frame over its spatial extent, the frame is partitioned into blocks of 8
× 8
pixels. The blocks then are independently transformed and adaptively processed based on their
local characteristics. Partitioning the frame into small blocks before taking the transform not
only allows spatially adaptive processing, but also reduces the computational and memory
requirements. The partitioning of the signal into small blocks before computing the DCT is
referred to as the block DCT.
An additional advantage of using the DCT domain representation is that the DCT coefficients
contain information about the spatial frequency content of the block. By utilizing the spatial fre-
quency characteristics of the human visual system, the precision with which the DCT coeffi-
cients are transmitted can be in accordance with their perceptual importance. This is achieved
through the quantization of these coefficients, as explained in the following sections.
Adaptive Field/Frame DCT
As noted previously, the DCT makes it possible to take advantage of the typically high degree of
spatial correlation in natural scenes [1]. When interlaced pictures are coded on a frame basis,
however, it is possible that significant amounts of motion result in relatively low spatial correla-
tion in some regions. This situation is accommodated by allowing the DCTs to be computed
either on a field basis or on a frame basis. The decision to use field- or frame-based DCT is
made individually for each macroblock.
Adaptive Quantization
The goal of video compression is to maximize the video quality at a given bit rate, and this
requires a careful distribution of the limited number of available bits [1]. By exploiting the per-
ceptual irrelevancy and statistical redundancy within the DCT domain representation, an appro-
priate bit allocation can yield significant improvements in performance. Quantization is
performed to reduce the precision of the DCT coefficient values, and through quantization and
code word assignment, the actual bit-rate compression is achieved. The quantization process is
the source of virtually all the loss of information in the compression algorithm. This is an impor-
tant point, as it simplifies the design process and facilitates fine-tuning of the system.
The degree of subjective picture degradation caused by coefficient quantization tends to
depend on the nature of the scenery being coded. Within a given picture, distortions of some
regions may be less apparent than in others. The video-coding system allows for the level of
quantization to be adjusted for each macroblock in order to save bits, where possible, through
coarse quantization.
Perceptual Weighting
The human visual system is not uniformly sensitive to coefficient quantization error [1]. Percep-
tual weighting of each source of coefficient quantization error is used to increase quantization
coarseness, thereby lowering the bit rate. The amount of visible distortion resulting from quanti-
zation error for a given coefficient depends on the coefficient number, or frequency, the local
brightness in the original image, and the duration of the temporal characteristic of the error. The
dc coefficient error results in mean value distortion for the corresponding block of pixels, which
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

ATSC DTV System Compression Isues 7-43
can expose block boundaries. This is more visible than higher-frequency coefficient error, which
appears as noise or texture.
Displays and the HVS exhibit nonuniform sensitivity to detail as a function of local average
brightness. Loss of detail in dark areas of the picture is not as visible as it is in brighter areas.
Another opportunity for bit savings is presented in textured areas of the picture, where high-fre-
quency coefficient error is much less visible than in relatively flat areas. Brightness and texture
weighting require analysis of the original image because these areas may be well predicted.
Additionally, distortion can be easily masked by limiting its duration to one or two frames. This
effect is most profitably used after scene changes, where the first frame or two can be greatly dis-
torted without perceptible artifacts at normal speed.
When transform coefficients are being quantized, the differing levels of perceptual impor-
tance of the various coefficients can be exploited by “allocating the bits” to shape the quantiza-
tion noise into the perceptually less important areas. This can be accomplished by varying the
relative step sizes of the quantizers for the different coefficients. The perceptually important
coefficients may be quantized with a finer step size than the others. For example, low spatial fre-
quency coefficients may be quantized finely, and the less important high-frequency coefficients
may be quantized more coarsely. A simple method to achieve different step sizes is to normalize
or weight each coefficient based on its visual importance. All of the normalized coefficients may
then be quantized in the same manner, such as rounding to the nearest integer (uniform quantiza-
tion). Normalization or weighting effectively scales the quantizer from one coefficient to
another. The MPEG-2 video-compression system utilizes perceptual weighting, where the differ-
ent DCT coefficients are weighted according to a perceptual criterion prior to uniform quantiza-
tion. The perceptual weighting is determined by quantizer matrices. The compression system
allows for modifying the quantizer matrices before each picture.
7.2.2k
Entropy Coding of Video Data
Quantization creates an efficient, discrete representation for the data to be transmitted [1]. Code
word assignment takes the quantized values and produces a digital bit stream for transmission.
Hypothetically, the quantized values could be simply represented using uniform- or fixed-length
code words. Under this approach, every quantized value would be represented with the same
number of bits. Greater efficiency—in terms of bit rate—can be achieved with entropy coding.
Entropy coding attempts to exploit the statistical properties of the signal to be encoded. A sig-
nal, whether it is a pixel value or a transform coefficient, has a certain amount of information, or
entropy, based on the probability of the different possible values or events occurring. For exam-
ple, an event that occurs infrequently conveys much more new information than one that occurs
often. The fact that some events occur more frequently than others can be used to reduce the
average bit rate.
Huffman Coding
Huffman coding, which is utilized in the ATSC DTV video-compression system, is one of the
most common entropy-coding schemes [1]. In Huffman coding, a code book is generated that
can approach the minimum average description length (in bits) of events, given the probability
distribution of all the events. Events that are more likely to occur are assigned shorter-length
code words, and those less likely to occur are assigned longer-length code words.
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues
7-44 Compression Technologies for Audio
Run Length Coding
In video compression, most of the transform coefficients frequently are quantized to zero [1].
There may be a few non-zero low-frequency coefficients and a sparse scattering of non-zero
high-frequency coefficients, but most of the coefficients typically have been quantized to zero.
To exploit this phenomenon, the 2-dimensional array of transform coefficients is reformatted
and prioritized into a 1-dimensional sequence through either a zigzag- or alternate-scanning pro-
cess. This results in most of the important non-zero coefficients (in terms of energy and visual
perception) being grouped together early in the sequence. They will be followed by long runs of
coefficients that are quantized to zero. These zero-value coefficients can be efficiently repre-
sented through run length encoding.
In run length encoding, the number (run) of consecutive zero coefficients before a non-zero
coefficient is encoded, followed by the non-zero coefficient value. The run length and the coeffi-
cient value can be entropy-coded, either separately or jointly. The scanning separates most of the
zero and the non-zero coefficients into groups, thereby enhancing the efficiency of the run
length encoding process. Also, a special end-of-block (EOB) marker is used to signify when all
of the remaining coefficients in the sequence are equal to zero. This approach can be extremely
efficient, yielding a significant degree of compression.
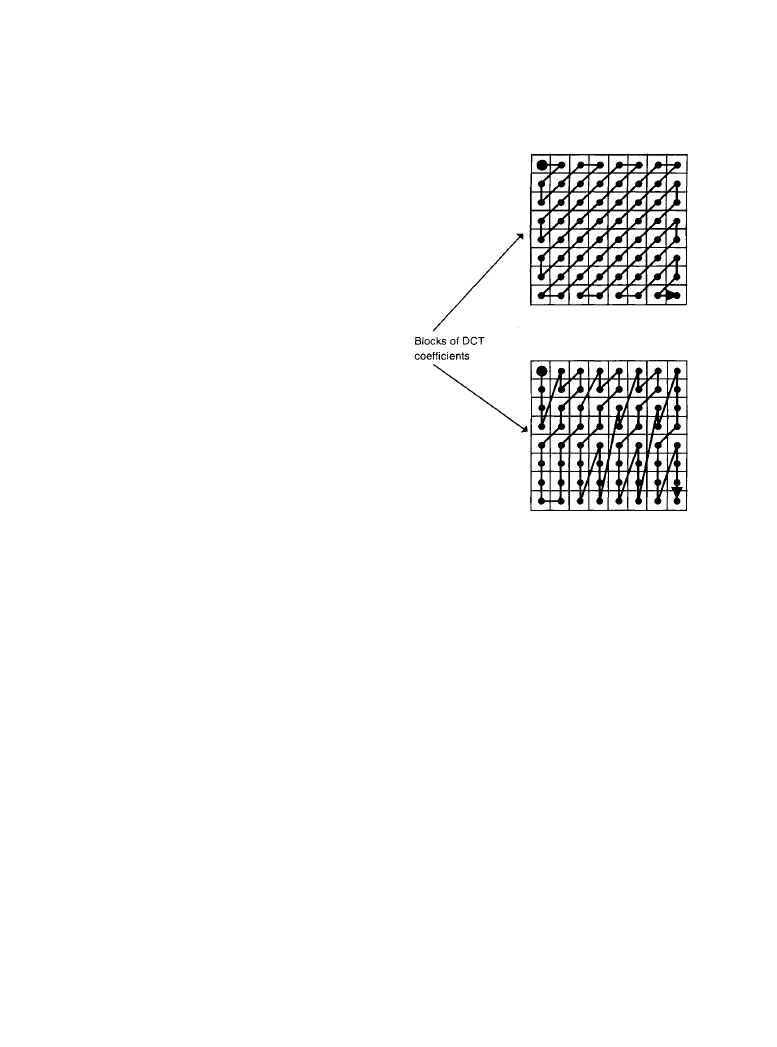
In the alternate-/zigzag-scan technique, the array of 64 DCT coefficients is arranged in a 1-
dimensional vector before run length/amplitude code word assignment. Two different 1-dimen-
sional arrangements, or scan types, are allowed, generally referred to as zigzag scan (shown in
Figure 7.2.3a) and alternate scan (shown in Figure 7.2.3b). The scan type is specified before
coding each picture and is permitted to vary from picture to picture.
(
a)
(
b)
Figure 7.2.3
Scanning of coefficient
blocks: (
a) alternate scanning of coeffi-
cients, (
b) zigzag scanning of coefficients.
(
From [1]. Used with permission.)
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues

ATSC DTV System Compression Isues 7-45
Channel Buffer
Whenever entropy coding is employed, the bit rate produced by the encoder is variable and is a
function of the video statistics [1]. Because the bit rate permitted by the transmission system is
less than the peak bit rate that may be produced by the variable-length coder, a channel buffer is
necessary at the decoder. This buffering system must be carefully designed. The buffer controller
must allow efficient allocation of bits to encode the video and also ensure that no overflow or
underflow occurs.
Buffer control typically involves a feedback mechanism to the compression algorithm
whereby the amplitude resolution (quantization) and/or spatial, temporal, and color resolution
may be varied in accordance with the instantaneous bit-rate requirements. If the bit rate
decreases significantly, a finer quantization can be performed to increase it.
The ATSC DTV standard specifies a channel buffer size of 8 Mbits. The model buffer is
defined in the DTV video-coding system as a reference for manufacturers of both encoders and
decoders to ensure interoperability. To prevent overflow or underflow of the model buffer, an
encoder may maintain measures of buffer occupancy and scene complexity. When the encoder
needs to reduce the number of bits produced, it can do so by increasing the general value of the
quantizer scale, which will increase picture degradation. When it is able to produce more bits, it
can decrease the quantizer scale, thereby decreasing picture degradation.
Decoder Block Diagram
As shown in Figure 7.2.4, the ATSC DTV video decoder contains elements that invert, or undo,
the processing performed in the encoder [1]. The incoming coded video bit stream is placed in
the channel buffer, and bits are removed by a variable length decoder (VLD).
The VLD reconstructs 8
× 8 arrays of quantized DCT coefficients by decoding run length/
amplitude codes and appropriately distributing the coefficients according to the scan type used.
These coefficients are dequantized and transformed by the IDCT to obtain pixel values or predic-
tion errors.
In the case of interframe prediction, the decoder uses the received motion vectors to perform
the same prediction operation that took place in the encoder. The prediction errors are summed
with the results of motion-compensated prediction to produce pixel values.
7.2.2l
Spatial and S/N Scalability
Because MPEG-2 was designed in anticipation of the need for handling different picture sizes
and resolutions, including standard-definition television and high-definition television, provi-
sions were made for a hierarchical split of the picture information into a base layer and two
enhancement layers [1]. In this way, SDTV decoders would not be burdened with the cost of
decoding an HDTV signal.
An encoder for this scenario could work as follows. The HDTV signal would be used as the
starting point. It would be spatially filtered and subsampled to create a standard resolution
image, which then would be MPEG-encoded. The higher-definition information could be
included in an enhancement layer.
Another use of a hierarchical split would be to provide different picture quality without
changing the spatial resolution. An encoder quantizer block could realize both coarse and fine
filtering levels. Better error correction could be provided for the more coarse data, so that as sig-
Downloaded from Digital Engineering Library @ McGraw-Hill (www.digitalengineeringlibrary.com)
Copyright © 2004 The McGraw-Hill Companies. All rights reserved.
Any use is subject to the Terms of Use as given at the website.
ATSC DTV System Compression Issues