ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 1127
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Согласно тезису Черча – Тьюринга (утверждение было высказано Алонзо Черчем и Аланом Тьюрингом в середине 1930-х годов), все известные типы вычислительных машин качественно эквивалентны в своих возможностях: любое действие, выполнимое на одной вычислительной машине, также выполнимо и на другой. Данный тезис является фундаментальным эвристическим утверждением, существенным для многих областей науки. Иногда его преподносят как фундаментальный принцип информатики, обращая особое внимание на машину Тьюринга и машину фон-неймановской архитектуры, поскольку они имеют явное сходство с большинством из современных компьютеров. В рамках современной информатики ученые изучают также и другие типы машин, не только практически осуществимые, но и абстрактные математические модели.
Приоритетными направлениями исследований в информатике являются: что можно, что нельзя реализовать в программах (теория вычислимости и искусственный интеллект), каким образом можно решать специфические задачи с максимальной эффективностью (алгоритмы), в каком виде следует хранить и восстанавливать информацию специфического вида (структуры данных), как программы и люди должны взаимодействовать друг с другом (пользовательский интерфейс и языки программирования) и т.п.
Отдельной наукой информатика была признана лишь в 1970-х; до этого она развивалась в составе математики, электроники и других технических наук. Некоторые начала информатики можно обнаружить даже в лингвистике. С момента своего признания отдельной наукой информатика разработала собственные методы и терминологию.
Первый факультет информатики был основан в 1962 году в университете Пердью (Purdue University). Сегодня факультеты и кафедры информатики имеются в большинстве университетов мира.
Высшей наградой за заслуги в области информатики является премия Тьюринга.
Основная задача информатики заключается в определении общих закономерностей, в соответствии с которыми происходит создание научной информации, ее преобразование, передача и использование в различных сферах деятельности человека. Прикладные задачи заключаются в разработке более эффективных методов и средств осуществления информационных процессов, в определении способов оптимальной научной коммуникации с широким применением технических средств.
Информатика разделяется на две части: теоретическую и прикладную.
Теоретическая информатика рассматривает формы и способы получения и использования информационных ресурсов (ИР), его законы и проблемы, изучает общие свойства, присущие всем разновидностям конкретных информационных технологий (ИТ) и сред их протекания.
Необходимо отметить, что теоретическая информатика включает ряд самостоятельных направлений, которые, по степени близости решаемых задач, можно условно разделить на пять классов:
• Математическая логика
• Программирование
• Теория информации
• Системный анализ
• Теория принятия решений
Высшим результатом развития теоретической информатики является создание искусственного интеллекта.
Прикладная информатика изучает конкретные разновидности ИТ, определяя для них общие и различные черты. При этом появляются новые ветви прикладной информатики: экспертные системы, диагностические комплексы, управляющие системы и др.
Результатом деятельности прикладной информатики является создание ИТ различного назначения.
Каждая наука имеет свой предмет для изучения. Предметом изучения информатики является информация и автоматизированные технологии использования информационного ресурса в многогранной деятельности людей.
Термин «информация» происходит от латинского слова «informatio», что означает сведения, разъяснения, изложение. Несмотря на широкое распространение, понятие информации является одним из самых дискуссионных в науке. В настоящее время наука пытается найти общие свойства и закономерности, присущие многогранному понятию информация, но пока оно во многом остается интуитивным и получает различные смысловые наполнения в различных отраслях человеческой деятельности.
Существование множества определений информации обусловлено сложностью, специфичностью и многообразием подходов к толкованию сущности этого понятия. Существуют 3 наиболее распространенные концепции информации, каждая из которых по-своему объясняет ее сущность.
Первая концепция – концепция К. Шеннона – отражая количественно-информационный подход, определяет информацию как меру неопределенности (энтропия) события. Количество информации в том или ином случае зависит от вероятности его получения: чем более вероятным является сообщение, тем меньше информации содержится в нем. Этот подход, хоть и не учитывает смысловую сторону информации, оказался весьма полезным в технике связи и вычислительной технике и послужил основой для измерения информации и оптимального кодирования сообщений. Кроме того, он представляется удобным для иллюстрации такого важного свойства информации, как новизна, неожиданность сообщений.
При таком понимании информация – это снятая неопределенность, или результат выбора из набора возможных альтернатив.
Вторая концепция рассматривает информацию как свойство материи. Ее появление связано с развитием кибернетики и основано на утверждении, что информацию содержат любые сообщения, воспринимаемые человеком или приборами. Наиболее ярко и образно эта концепция информации выражена академиком В.М. Глушковым. Он писал, что «информацию несут не только испещренные буквами листы книги или человеческая речь, но и солнечный свет, складки горного хребта, шум водопада, шелест травы».
То есть, информация как свойство материи создает представление о ее природе и структуре, упорядоченности и разнообразии. Она не может существовать вне материи, а значит, она существовала и будет существовать вечно, ее можно накапливать, хранить и перерабатывать.
Третья концепция основана на логико-семантическом подходе, при котором информация трактуется как знание, причем не любое знание, а та его часть, которая используется для ориентирования, активного действия, управления и самоуправления.
Иными словами, информация – это действующая, полезная часть знаний. Представитель этой концепции В.Г. Афанасьев, развивая логико-семантический подход, дает определение социальной информации: «Информация, циркулирующая в обществе, используемая в управлении социальными процессами, является социальной информацией. Она представляет собой знания, сообщения, сведения о социальной форме движения материи и о всех других формах в той мере, в какой она используется обществом...».
Для современного понятия информации характерен содержательный подход. Такой подход к понятию информации впервые появился в фундаментальных работах основоположника кибернетики Н. Винера. Согласно современным представлениям, информация есть некая форма отражения или отображения внешней среды, имеющей одну физическую форму, в так называемое информационное сообщение или модель, имеющие другую физическую форму. Так, например, все многообразие окружающего нас реального мира (вода, земля и т.д.) отражается в мозге человека с помощью одной физической формы, а именно, с помощью электрохимических потенциалов. В компьютере подобное многообразие может быть отражено с помощью высокого и низкого потенциала (нулей и единиц).
Рассмотренные подходы в определенной мере дополняют друг друга, освещают различные стороны сущности понятия информации и облегчают тем самым систематизацию ее основных свойств. Обобщив данные подходы, можно дать следующее определение информации:
Информация – это сведения об объектах и явлениях окружающего мира (их параметрах, свойствах и состоянии), которые воспринимаются, обрабатываются и при этом обязательно уменьшают имеющуюся о них степень неопределенности или неполноты знаний о них.
Информацию, представленную в форме, которая позволяет осуществлять ее преобразование с целью передачи, обработки практического использования, называют сообщением.
Всякое сообщение является совокупностью сведений о состоянии какой-либо материальной системы, которые передаются человеком (или устройством), наблюдающим эту систему, другому человеку (или устройству), не имеющему возможностей получить эти сведения из непосредственных наблюдений. Наблюдаемая материальная система вместе с наблюдателем представляет собой источник информации, а человек или устройство, которому предназначаются результаты наблюдения – получатель информации.
Источник информации может вырабатывать непрерывное или дискретное сообщения. Передача сообщений на расстояние осуществляется с помощью какого-либо материального носителя (бумажный носитель, электронный носитель) или физического процесса (звуковых или электромагнитных волн, тока и т.п.).
Физический процесс, отображающий (несущий) передаваемое сообщение, называется сигналом. Сигналы формируются путем изменения тех или иных параметров физического носителя по закону передаваемых сообщений. Этот процесс изменения параметров сигнала в соответствии с передаваемым сообщением называется модуляцией и осуществляется в системах связи с помощью модулятора.
Информация является объективно существующей реальностью окружающего нас мира и как любой другой объект обладает рядом свойств, позволяющих отличать один информационный объект от другого. Приведем общую классификацию свойств информации (рис. 2).

Рис. 2. Свойства информации
К атрибутивным относятся свойства, без которых информация не может существовать. Например, неотрывность информации от физического носителя и языковая природа информации, дискретность, непрерывность.
Под прагматическими будем понимать те свойства, которые проявляются в процессе использования информации и характеризующие степень ее полезности для пользователя. К прагматическим свойствам информации относятся: смысл и новизна, полезность, ценность, кумулятивность, полнота, достоверность, адекватность и другие.
Динамические свойства характеризуют изменение информации во времени. Например, к динамическим свойствам информации относятся рост информации и старение.
2. Количественная мера информации
Количество информации – число, адекватно характеризующее разнообразие (структурированность, определенность, выбор состояний и т.д.) в оцениваемой системе.
Классическая количественная теория информации состояла и ныне состоит из двух частей: теории преобразования сообщений и сигналов (сущность теории заключается в рассмотрении вопросов кодирования и декодирования информации) и теории передачи сообщений и сигналов без шумов и с шумами в канале связи.
Трактовка информации как меры уменьшения неопределенности некоторого случайного процесса дает возможность, используя математический аппарат теории вероятностей и математической статистики, ввести единицу измерения информации и понятие количественной меры информации. Это весьма важно с точки зрения практического использования для понимания процессов передачи и хранения информации. Необходимо отметить, что вероятность конкретного исхода некоторого события непосредственно связана с количеством информации, содержащемся в сообщении об этом исходе.
Считается, что чем более вероятен конкретный исход события, тем меньше информации несет сообщение об этом исходе. Математическая запись данного тезиса выглядит следующим образом:
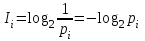 (i=1...n), (1)
(i=1...n), (1)где Ii – количество информации, содержащееся в сообщении обi-ом исходе события, pi – вероятность исхода i-го события.
Из формулы (1) видно, чем выше значение вероятности pi исхода конкретного события, тем меньше будет величина log2(1/pi) и, следовательно, тем меньшее количество информации будет содержаться в информации об исходе данного события.
Введем в рассмотрение случайную величину I, представляющую собой количество информации, содержащееся в сообщении о конкретном исходе того или иного события. В соответствии с формулой (1) данная случайная величина может быть задана следующей таблицей (табл.1):
Таблица 1.
| I | log2 1/p1 | log2 1/p2 | … | log2 1/pn |
| Р | p1 | p2 | … | pn |