ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 1162
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
, именно такие растры наиболее часто используются.
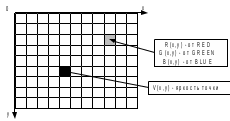
Рис. 7. Прямоугольный растр
Кроме прямоугольного растра используются другие формы: треугольника, шестиугольника, соответствующего следующим требованиям:
В качестве растрового элемента возможно использование равностороннего треугольника рис. 8, правильного шестиугольника (гексаэдра) рис. 9. Можно строить растры, используя неправильные многоугольники, но практический смысл в подобных растрах отсутствует.
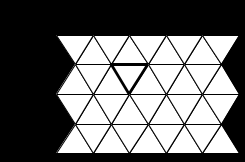
Рис. 8. Треугольный растр
Рассмотрим способы построения линий в прямоугольном и гексагональном растре.

Рис. 9. «Гексагональный растр»
В прямоугольном растре построение линии осуществляется двумя способами:
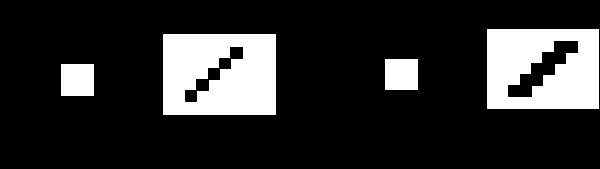
Рис. 10. Построение линии в прямоугольном растре
В гексагональном растре линии шестисвязные (см. рис. 11) такие линии более стабильны по ширине, т.е. дисперсия ширины линии меньше, чем в квадратном растре.

Рис. 11. Построение линии в гексагональном растре
Одним из способов оценки растра является передача по каналу связи кодированного, с учетом используемого растра, изображения с последующим восстановлением и визуальным анализом достигнутого качества. Экспериментально и математически доказано, что гексагональный растр лучше, т.к. обеспечивает наименьшее отклонение от оригинала. Но разница не велика.
Моделирование гексагонального растра возможно на основе квадратного. Для этого гексаугольник представляют в виде прямоугольника.
Файлы растровой графики занимают большое количество памяти компьютера. Некоторые картинки занимают большой объем памяти из-за большого количества пикселей, любой из которых занимает некоторую часть памяти. Наибольшее влияние на количество памяти занимаемой растровым изображением оказывают три факта:
Существует прямая зависимость размера файла растрового изображения. Чем больше в изображении пикселей, тем больше размер файла. Разрешающая способность изображения на величину файла никак не влияет. Разрешающая способность оказывает эффект на размер файла только при сканировании или редактировании изображений.
Связь между битовой глубиной и размером файла непосредственная. Чем больше битов используется в пикселе, тем больше будет файл. Размер файла растровой графики сильно зависит от формата, выбранного для хранения изображения. При прочих равных условиях, таких как размеры изображения и битовая глубина существенное значение имеет схема сжатия изображения. Например, BMP файл имеет, как правило, большие размеры, по сравнению с файлами PCX и GIF, которые в свою очередь больше JPEG файла.
Многие файлы изображений обладают собственными схемами сжатия, также могут содержать дополнительные данные краткого описания изображения для предварительного просмотра.
Достоинства:
Растровая графика эффективно представляет реальные образы. Реальный мир состоит из миллиардов мельчайших объектов и человеческий глаз как раз приспособлен для восприятия огромного набора дискретных элементов, образующих предметы. На своем высшем уровне качества – изображение выглядят вполне реально подобно тому, как выглядят фотографии в сравнении с рисунками. Это верно только для очень детализированных изображений, обычно получаемых сканированием фотографий. Помимо естественного вида растровые изображения имеют другие преимущества. Устройства вывода, такие как лазерные принтеры, для создания изображений используют наборы точек. Растровые изображения могут быть очень легко распечатаны на таких принтерах, потому что компьютерам легко управлять устройством вывода для представления отдельных пикселей с помощью точек.
Недостатки:
Растровые изображения занимают большое количество памяти. Существует так же проблема редактирования растровых изображений, так как большие растровые изображения занимают значительные массивы памяти, то для обеспечения работы функций редактирования таких изображений потребляются так же значительные массивы памяти и другие ресурсы компьютера.
Иногда характеристики растрового изображения записывают в такой форме: 1024x768x24. Это означает, что ширина изображения равна 1024 пикселям, высота – 768 и глубина цвета равна 24. Размер несжатого изображения с такими параметрами будет равен 1024*768*24 = 18874368 байт. Это более 18 мегабайт – большой объем для одного изображения, особенно если требуется хранить несколько тысяч таких изображений – это не так уж много по компьютерным меркам. Вот почему компьютерную графику используют почти всегда в сжатом виде.
RLE (Run Length Encoding) – метод сжатия, заключающийся в поиске последовательностей одинаковых пикселей в сточках растрового изображения («красный, красный, ..., красный» записывается как «N красных»).
LZW (Lempel–Ziv–Welch) – более сложный метод, ищет повторяющиеся фразы – одинаковые последовательности пикселей разного цвета. Каждой фразе ставится в соответствие некоторый код, при расшифровке файла код замещается исходной фразой.
При сжатии файлов формата JPEG (с потерей качества) изображение разбивается на участки 8x8 пикселей, и в каждом участке их значение усредняется. Усреднённое значение располагается в левом верхнем углу блока, остальное место занимается меньшими по яркости пикселями. Затем большинство пикселей обнуляются. При расшифровке нулевые пиксели получают одинаковый цвет. Затем к изображению применяется алгоритм Хаффмана.
Алгоритм Хаффмана основан на теории вероятности. Сначала элементы изображения (пиксели) сортируются по частоте встречаемости. Затем из них строится кодовое дерево Хаффмана. Каждому элементу сопоставляется кодовое слово. При стремлении размера изображения к бесконечности достигается максимальность сжатия. Этот алгоритм также используется в архиваторах.
Сжатие применяется и для векторной графики, но здесь уже нет таких простых закономерностей, так как форматы векторных файлов достаточно сильно различаются по содержанию.
Для растровых изображений, состоящих из точек, особую важность имеет понятие разрешения, выражающее количество точек, приходящихся на единицу длины. При этом следует различать:
Разрешение оригинала измеряется в точках на дюйм (dotsperinch – dpi) и зависит от требований к качеству изображения и размеру файла, способу оцифровки и создания исходной иллюстрации
, избранному формату файла и другим параметрам. В общем случае действует правило: чем выше требование к качеству, тем выше должно быть разрешение оригинала.
Для экранных копий изображения элементарную точку растра принято называть пикселем. Размер пикселя варьируется в зависимости от выбранного экранного разрешения (из диапазона стандартных значений), разрешение оригинала и масштаб отображения.
Для экранной копии достаточно разрешения 72 dpi, для распечатки на цветном или лазерном принтере 150–200 dpi, для вывода на фотоэкспонирующем устройстве 200–300 dpi. Установлено эмпирическое правило, что при распечатке величина разрешения оригинала должна быть в 1,5 раза больше, чем линиатура растра устройства вывода. В случае, если твердая копия будет увеличена по сравнению с оригиналом, эти величины следует умножить на коэффициент масштабирования.
Размер точки растрового изображения как на твердой копии (бумага, пленка и т. д.), так и на экране зависит от примененного метода и параметров растрирования оригинала. При растрировании на оригинал как бы накладывается сетка линий, ячейки которой образуют элемент растра. Частота сетки растра измеряется числом линий на дюйм (lines per inch – Ipi) и называется линиатурой.
Размер точки растра рассчитывается для каждого элемента и зависит от интенсивности тона в данной ячейке. Чем больше интенсивность, тем плотнее заполняется элемент растра. То есть, если в ячейку попал абсолютно черный цвет, размер точки растра совпадет с размером элемента растра. В этом случае говорят о 100% заполняемости. Для абсолютно белого цвета значение заполняемости составит 0%. На практике заполняемость элемента на отпечатке обычно составляет от 3 до 98%. При этом все точки растра имеют одинаковую оптическую плотность, в идеале приближающуюся к абсолютно черному цвету. Иллюзия более темного тона создается за счет увеличения размеров точек и, как следствие, сокращения пробельного поля между ними при одинаковом расстоянии между центрами элементов растра. Такой метод называют растрированием с амплитудной модуляцией (AM).
Таким образом, разрешающая способность характеризует расстояние между соседними пикселями (рис. 12.). Разрешающую способность измеряют количеством пикселей на единицу длины. Наиболее популярной единицей измерения является dpi (dots per inch) – количество пикселей в одном дюйме длины (2.54 см). Не следует отождествлять шаг с размерами пикселей – размер пикселей может быть равен шагу, а может быть как меньше, так и больше, чем шаг.
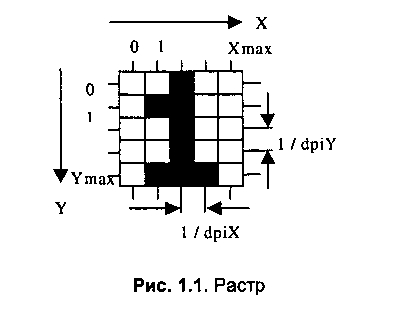
Рис. 1. Растр.
Размер растра обычно измеряется количеством пикселов по горизонтали и вертикали. Можно сказать, что для компьютерной графики зачастую наиболее удобен растр с одинаковым шагом для обеих осей, то есть dpi Х = dpi У. Это удобно для многих алгоритмов вывода графических объектов.
Форма пикселя растра определяется особенностями устройства графического вывода (рис. 13). Например, пиксели могут иметь форму прямоугольника или квадрата, которые по размерам равны шагу растра (дисплей на жидких кристаллах); пиксели круглой формы, которые по размерам могут и не равняться шагу растра (принтеры).
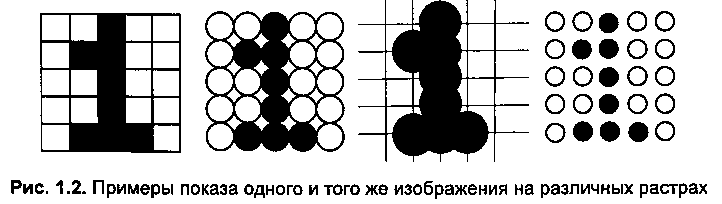
Рис. 2. Изображение на различных растрах
Интенсивность тона принято подразделять на 256 уровней. Большее число градаций не воспринимается зрением человека и является избыточным. Меньшее число ухудшает восприятие изображения (минимально допустимым для качественной полутоновой иллюстрации принято значение 150 уровней). Для воспроизведения 256 уровней тона достаточно иметь размер ячейки растра 256 = 16 х 16 точек.
При выводе копии изображения на принтере или полиграфическом оборудовании линиатуру растра выбирают, исходя из компромисса между требуемым качеством, возможностями аппаратуры и параметрами печатных материалов.
Качество воспроизведения тоновых изображений принято оценивать динамическим диапазоном (D). Это оптическая плотность, численно равная десятичному логарифму величины, обратной коэффициенту пропускания или коэффициенту отражения.
Для оптических сред, пропускающих свет, динамический диапазон лежит в пределах от 0 до 4. Для поверхностей, отражающих свет, значение динамического диапазона составляет от 0 до 2. Чем выше динамический диапазон, тем большее число полутонов присутствует в изображении и тем лучше качество его восприятия.
В цифровом мире компьютерных изображений термином пиксель обозначают несколько разных понятий. Это может быть отдельная точка экрана компьютера, отдельная точка, напечатанная на лазерном принтере или отдельный элемент растрового изображения. Эти понятия не одно и то же, поэтому чтобы избежать путаницы следует называть их следующим образом: видео пиксель при ссылке на изображение экрана компьютера; точка при ссылке на отдельную точку, создаваемую лазерным принтером. Существует коэффициент прямоугольности изображения, который введен специально для изображения количества пикселей матрицы рисунка по горизонтали и по вертикали.
Рис. 7. Прямоугольный растр
Кроме прямоугольного растра используются другие формы: треугольника, шестиугольника, соответствующего следующим требованиям:
-
все фигуры должны быть одинаковые; -
должны полностью покрывать плоскость без накладывания и зазоров.
В качестве растрового элемента возможно использование равностороннего треугольника рис. 8, правильного шестиугольника (гексаэдра) рис. 9. Можно строить растры, используя неправильные многоугольники, но практический смысл в подобных растрах отсутствует.
Рис. 8. Треугольный растр
Рассмотрим способы построения линий в прямоугольном и гексагональном растре.
Рис. 9. «Гексагональный растр»
В прямоугольном растре построение линии осуществляется двумя способами:
-
Результат – восьмисвязная линия. Соседние пиксели линии могут находится в одном из восьми возможных (см. рис. 10а) положениях. Недостаток – слишком тонкая линия при угле 45°. -
Результат – четырехсвязная линия. Соседние пиксели линии могут находится в одном из четырех возможных (см. рис. 10б) положениях. Недостаток – избыточно толстая линия при угле 45°.
Рис. 10. Построение линии в прямоугольном растре
В гексагональном растре линии шестисвязные (см. рис. 11) такие линии более стабильны по ширине, т.е. дисперсия ширины линии меньше, чем в квадратном растре.
Рис. 11. Построение линии в гексагональном растре
Одним из способов оценки растра является передача по каналу связи кодированного, с учетом используемого растра, изображения с последующим восстановлением и визуальным анализом достигнутого качества. Экспериментально и математически доказано, что гексагональный растр лучше, т.к. обеспечивает наименьшее отклонение от оригинала. Но разница не велика.
Моделирование гексагонального растра возможно на основе квадратного. Для этого гексаугольник представляют в виде прямоугольника.
Файлы растровой графики занимают большое количество памяти компьютера. Некоторые картинки занимают большой объем памяти из-за большого количества пикселей, любой из которых занимает некоторую часть памяти. Наибольшее влияние на количество памяти занимаемой растровым изображением оказывают три факта:
-
размер изображения; -
битовая глубина цвета; -
формат файла, используемого для хранения изображения.
Существует прямая зависимость размера файла растрового изображения. Чем больше в изображении пикселей, тем больше размер файла. Разрешающая способность изображения на величину файла никак не влияет. Разрешающая способность оказывает эффект на размер файла только при сканировании или редактировании изображений.
Связь между битовой глубиной и размером файла непосредственная. Чем больше битов используется в пикселе, тем больше будет файл. Размер файла растровой графики сильно зависит от формата, выбранного для хранения изображения. При прочих равных условиях, таких как размеры изображения и битовая глубина существенное значение имеет схема сжатия изображения. Например, BMP файл имеет, как правило, большие размеры, по сравнению с файлами PCX и GIF, которые в свою очередь больше JPEG файла.
Многие файлы изображений обладают собственными схемами сжатия, также могут содержать дополнительные данные краткого описания изображения для предварительного просмотра.
Достоинства:
Растровая графика эффективно представляет реальные образы. Реальный мир состоит из миллиардов мельчайших объектов и человеческий глаз как раз приспособлен для восприятия огромного набора дискретных элементов, образующих предметы. На своем высшем уровне качества – изображение выглядят вполне реально подобно тому, как выглядят фотографии в сравнении с рисунками. Это верно только для очень детализированных изображений, обычно получаемых сканированием фотографий. Помимо естественного вида растровые изображения имеют другие преимущества. Устройства вывода, такие как лазерные принтеры, для создания изображений используют наборы точек. Растровые изображения могут быть очень легко распечатаны на таких принтерах, потому что компьютерам легко управлять устройством вывода для представления отдельных пикселей с помощью точек.
Недостатки:
Растровые изображения занимают большое количество памяти. Существует так же проблема редактирования растровых изображений, так как большие растровые изображения занимают значительные массивы памяти, то для обеспечения работы функций редактирования таких изображений потребляются так же значительные массивы памяти и другие ресурсы компьютера.
Иногда характеристики растрового изображения записывают в такой форме: 1024x768x24. Это означает, что ширина изображения равна 1024 пикселям, высота – 768 и глубина цвета равна 24. Размер несжатого изображения с такими параметрами будет равен 1024*768*24 = 18874368 байт. Это более 18 мегабайт – большой объем для одного изображения, особенно если требуется хранить несколько тысяч таких изображений – это не так уж много по компьютерным меркам. Вот почему компьютерную графику используют почти всегда в сжатом виде.
RLE (Run Length Encoding) – метод сжатия, заключающийся в поиске последовательностей одинаковых пикселей в сточках растрового изображения («красный, красный, ..., красный» записывается как «N красных»).
LZW (Lempel–Ziv–Welch) – более сложный метод, ищет повторяющиеся фразы – одинаковые последовательности пикселей разного цвета. Каждой фразе ставится в соответствие некоторый код, при расшифровке файла код замещается исходной фразой.
При сжатии файлов формата JPEG (с потерей качества) изображение разбивается на участки 8x8 пикселей, и в каждом участке их значение усредняется. Усреднённое значение располагается в левом верхнем углу блока, остальное место занимается меньшими по яркости пикселями. Затем большинство пикселей обнуляются. При расшифровке нулевые пиксели получают одинаковый цвет. Затем к изображению применяется алгоритм Хаффмана.
Алгоритм Хаффмана основан на теории вероятности. Сначала элементы изображения (пиксели) сортируются по частоте встречаемости. Затем из них строится кодовое дерево Хаффмана. Каждому элементу сопоставляется кодовое слово. При стремлении размера изображения к бесконечности достигается максимальность сжатия. Этот алгоритм также используется в архиваторах.
Сжатие применяется и для векторной графики, но здесь уже нет таких простых закономерностей, так как форматы векторных файлов достаточно сильно различаются по содержанию.
Для растровых изображений, состоящих из точек, особую важность имеет понятие разрешения, выражающее количество точек, приходящихся на единицу длины. При этом следует различать:
-
разрешение оригинала; -
разрешение экранного изображения; -
разрешение печатного изображения.
Разрешение оригинала измеряется в точках на дюйм (dotsperinch – dpi) и зависит от требований к качеству изображения и размеру файла, способу оцифровки и создания исходной иллюстрации
, избранному формату файла и другим параметрам. В общем случае действует правило: чем выше требование к качеству, тем выше должно быть разрешение оригинала.
Для экранных копий изображения элементарную точку растра принято называть пикселем. Размер пикселя варьируется в зависимости от выбранного экранного разрешения (из диапазона стандартных значений), разрешение оригинала и масштаб отображения.
Для экранной копии достаточно разрешения 72 dpi, для распечатки на цветном или лазерном принтере 150–200 dpi, для вывода на фотоэкспонирующем устройстве 200–300 dpi. Установлено эмпирическое правило, что при распечатке величина разрешения оригинала должна быть в 1,5 раза больше, чем линиатура растра устройства вывода. В случае, если твердая копия будет увеличена по сравнению с оригиналом, эти величины следует умножить на коэффициент масштабирования.
Размер точки растрового изображения как на твердой копии (бумага, пленка и т. д.), так и на экране зависит от примененного метода и параметров растрирования оригинала. При растрировании на оригинал как бы накладывается сетка линий, ячейки которой образуют элемент растра. Частота сетки растра измеряется числом линий на дюйм (lines per inch – Ipi) и называется линиатурой.
Размер точки растра рассчитывается для каждого элемента и зависит от интенсивности тона в данной ячейке. Чем больше интенсивность, тем плотнее заполняется элемент растра. То есть, если в ячейку попал абсолютно черный цвет, размер точки растра совпадет с размером элемента растра. В этом случае говорят о 100% заполняемости. Для абсолютно белого цвета значение заполняемости составит 0%. На практике заполняемость элемента на отпечатке обычно составляет от 3 до 98%. При этом все точки растра имеют одинаковую оптическую плотность, в идеале приближающуюся к абсолютно черному цвету. Иллюзия более темного тона создается за счет увеличения размеров точек и, как следствие, сокращения пробельного поля между ними при одинаковом расстоянии между центрами элементов растра. Такой метод называют растрированием с амплитудной модуляцией (AM).
Таким образом, разрешающая способность характеризует расстояние между соседними пикселями (рис. 12.). Разрешающую способность измеряют количеством пикселей на единицу длины. Наиболее популярной единицей измерения является dpi (dots per inch) – количество пикселей в одном дюйме длины (2.54 см). Не следует отождествлять шаг с размерами пикселей – размер пикселей может быть равен шагу, а может быть как меньше, так и больше, чем шаг.
Рис. 1. Растр.
Размер растра обычно измеряется количеством пикселов по горизонтали и вертикали. Можно сказать, что для компьютерной графики зачастую наиболее удобен растр с одинаковым шагом для обеих осей, то есть dpi Х = dpi У. Это удобно для многих алгоритмов вывода графических объектов.
Форма пикселя растра определяется особенностями устройства графического вывода (рис. 13). Например, пиксели могут иметь форму прямоугольника или квадрата, которые по размерам равны шагу растра (дисплей на жидких кристаллах); пиксели круглой формы, которые по размерам могут и не равняться шагу растра (принтеры).
Рис. 2. Изображение на различных растрах
Интенсивность тона принято подразделять на 256 уровней. Большее число градаций не воспринимается зрением человека и является избыточным. Меньшее число ухудшает восприятие изображения (минимально допустимым для качественной полутоновой иллюстрации принято значение 150 уровней). Для воспроизведения 256 уровней тона достаточно иметь размер ячейки растра 256 = 16 х 16 точек.
При выводе копии изображения на принтере или полиграфическом оборудовании линиатуру растра выбирают, исходя из компромисса между требуемым качеством, возможностями аппаратуры и параметрами печатных материалов.
Качество воспроизведения тоновых изображений принято оценивать динамическим диапазоном (D). Это оптическая плотность, численно равная десятичному логарифму величины, обратной коэффициенту пропускания или коэффициенту отражения.
Для оптических сред, пропускающих свет, динамический диапазон лежит в пределах от 0 до 4. Для поверхностей, отражающих свет, значение динамического диапазона составляет от 0 до 2. Чем выше динамический диапазон, тем большее число полутонов присутствует в изображении и тем лучше качество его восприятия.
В цифровом мире компьютерных изображений термином пиксель обозначают несколько разных понятий. Это может быть отдельная точка экрана компьютера, отдельная точка, напечатанная на лазерном принтере или отдельный элемент растрового изображения. Эти понятия не одно и то же, поэтому чтобы избежать путаницы следует называть их следующим образом: видео пиксель при ссылке на изображение экрана компьютера; точка при ссылке на отдельную точку, создаваемую лазерным принтером. Существует коэффициент прямоугольности изображения, который введен специально для изображения количества пикселей матрицы рисунка по горизонтали и по вертикали.