Файл: Курс лекций по дисциплине Информационные технологии в юридической деятельности.rtf
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 08.11.2023
Просмотров: 547
Скачиваний: 4
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
.
В связи с тем, что последние два компонента дополнительного изучения не требуют, рассмотрим подробно понятие базы данных и СУБД.
3. Понятие и организация базы данных
Информационный фонд автоматизированных информационных систем - совокупность всех данных, подлежащих накоплению, хранению, поиску, преобразованию и выдачи в установленном порядке, а также используемых для организации общения человека с ЭВМ.
Существуют два подхода к созданию информационных фондов - локальный и интегрированный.
При локальной структуре информационного фонда создаются массивы (файлы) данных, предназначенные для решения самостоятельных (отдельных) задач управления или их комплексов.
Файлы при этом обычно бывают простыми, последовательными наборами данных, полностью зависящими от программного обеспечения, используемого для их обработки, т.е. конкретных прикладных программ, при помощи которых к этим данным обращаются их пользователи.
Многие файлы локального информационного фонда формируются отдельно для каждого расчета, решения отдельных задач. Поэтому одни и те же данных, используемые в различных приложениях, обычно представляются в другой форме. Это ведет к тому, что в фонде создается большая избыточность или дублирование данных, возникают определенные трудности при их актуализации (обновлении). Практически при большом объеме фонда очень трудно сохранять все файлы на одном и том же уровне обновления.
В связи с этим пользователи часто могут обнаруживать явные противоречия в данных и испытывать определенное недоверие к ЭВМ. Кроме того, при постоянном изменении и расширении фонда локальных файлов возникает необходимость в модификации прикладных программ, которая требует значительных затрат.
Указанные недостатки локальных информационных фондов, в основном проявлялись в системах обработки данных на базе ЭВМ второго поколения. Полностью или значительно они отсутствуют в интегрированных или так называемых единых информационных фондах.
Единые фонды также могут иметь файловую структуру, но при этом данные, включаемые в определенный файл, имеют многоцелевое назначение. Тем самым уменьшается избыточность или дублирование данных, упрощается процесс обновления данных.
Для описания структур данных выделяют два способа: логический и физический.
Логическое описание структуры данных выглядит в виде, полностью готовом для представления пользователю (например, карточки исходной информации, таблицы выходных данных, отпечатанные на ЭВМ и т.д.).
Физическое описание отражает их реальное расположение в определенных ячейках памяти ЭВМ, а также методы доступа к указанным устройствам (например, физическое расположение данных на поле магнитного диска и организация прямого, т.е. без дополнительных устройств, доступа к этому диску оперативного запоминающего устройства ЭВМ).
При создании упомянутых выше локальных информационных фондов физическая и логическая структуры данных полностью совпадали, т.е. отсутствовала возможность по иному, чем физически записано на носителе информации, представлять последовательность и взаимосвязь данных в документах, предназначенных для пользователей. Соответственно любые требуемые изменения в той или иной структуре данных вызывали необходимость изменения всей системы описания данных.
Создание единых информационных фондов потребовало разделения физических и логических структур данных.
Разделение физической и логической структуры данных позволило обеспечить их независимость от прикладных программ. Это в свою очередь создало возможность перейти к новому уровню организации единых информационных фондов, получившему название базы данных. Практическая реализация концепции баз данных связана с внедрением ЭВМ третьего поколения.
База данных - это управляемый единый информационный фонд, содержащий не только соответствующим образом организованные и логически связанные между собой данные, но и систему их описания, а также средства, поддерживающие установленные информационные связи.
Для организации структур баз данных используется три способа: иерархический, сетевой и реляционный.
Иерархические структуры организации баз данных называют также деревьями.
Дерево представляет собой иерархию (строгий порядок расположения) элементов, называемых узлами (рис. 2.).
На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, является порожденным и связан только с одним узлом более высокого уровня (исходным узлом).
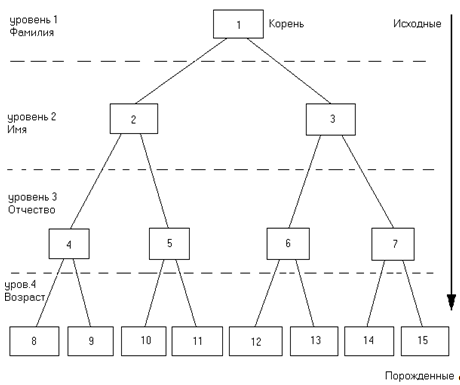
Рис. 2. Структура иерархической базы данных
По указанному принципу построена, например алфавитно-справочная картотека адресного бюро. В ней исходным элементом является фамилия зарегистрированного лица, а все остальные найденные сведения являются порожденными.
Иерархические структуры обладают достоинством надежного хранения сформированных данных, т.к. отдельные элементы данных лишь однозначно связаны между собой. Кроме того, иерархическая структура базы дает возможность организовать несколько способов поиска данных по их адресам. Причем эти способы поиска отличаются высокой логической четкостью, последовательностью и позволяют вести поиск требуемых данных с большой точностью и максимальной полнотой.
Но иерархические базы данных имеют и ряд существенных недостатков:
1. Необходимость составления сложного и громоздкого программного обеспечения;
2. Необходимость дублирования одних и тех же данных в описании их логической структуры;
3. Сложность поиска требуемых данных сразу по нескольким связям или признакам.
Многие из указанных недостатков устраняются применением сетевых структур организации баз данных или сетевых файлов.
К сетевым структурам приходится обращаться во всех случаях, если в отношениях или связях между данными порожденный элемент имеет более одного исходного элемента. В сетевой структуре любой элемент может быть связан с любым другим элементом (рис. 3.).
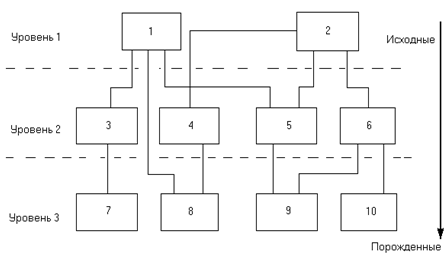
Наглядным примерам сетевых структур является генеалогическое дерево с указанием родственных связей, где каждый ребенок порожден от двух родителей.
Другим примером связи сетевых структур является квалификация степени наказания (статьи УК РФ) на основании отношения лица к преступлению (организатор, соучастник, исполнитель и т.д.), способа совершения (в группе, в одиночку и т.д.), а также возможно и других исходных данных.
Сетевые структуры имеют некоторые преимущества в описании данных по сравнению с иерархическим подходом. Смысл этих преимуществ можно свести к гораздо большему перечню возможностей и разнообразию услуг для пользователей сетевых баз данных. В первую очередь данное положение относится к многоаспектному (т.е. по многим признакам) поиску требуемых данных.
Вместе с тем расширение количества связей между элементами данных приводит к определенной трудности в общении с сетевыми базами данных (требует применения «не-фон-неймановских», например, параллельных структур ЭВМ с ассоциативным подходом). Это составляет главный недостаток сетевого подхода.
Дальнейшее развитие способов организации баз данных привело к разработке и внедрению реляционных структур данных.
Реляционный подход (табличный подход) к описанию структур данных основывается на представлении их в виде двумерных таблиц (рис. 4.). Такое представление данных является одним их наиболее естественных и понятных для пользователей.
Строкой такой таблицы является запись (документ) как единица логического описания данных, а каждый столбец является набором значений какого-либо атрибута или признака для всего перечня записей.
К основным преимуществам реляционных структур относятся:
1. Простота понимания и работы с базой.
2. Простота развития и дополнения базы.
3. Простота исключения несанкционированного доступа к закрытым данным.
4. Простота осуществления многоаспектного поиска требуемых наборов данных.
Рис. 4. Структура реляционной базы данных
В заключение необходимо указать, что в настоящее время наибольшее распространение в стране (и в мире) нашли реляционные и различным образом комбинированные способы организации баз данных. В особенности это относится к базам данных на персональных ЭВМ.
4. Системы управления базами данных и их основные функции
Приведем два определения СУБД.
СУБД – программно-логический аппарат (специальный пакет программ), организующий создание, ведение и выдачу данных.
СУБД - это программная система, обеспечивающая создание, актуализацию и выдачу данных из базы с соблюдением основных требований автоматизированной системы, в которой она установлена.
В любом варианте подчеркивается программный смысл СУБД, организованной в соответствии со структурой базы данных.
Основные функции, выполняемые СУБД, следующие:
1 - создание базы данных;
2 - ведение базы данных в банке данных;
3 - поддержание целостности данных и логический контроль вводимых данных;
4 - обеспечение выборки нужных данных и выдача результатов пользователю в заданной форме;
5 - соблюдение приоритета и санкционирование доступа к данным.
Рассмотрим содержание указанных функций на примере образца реляционной структуры базы данных - обобщенной таблицы, содержащей сведения о владельцах автомобилей.
1. Создание базы данных заключается в обеспечении необходимой упорядоченности и связности накапливаемых и хранимых данных.
В нашем случае СУБД задает табличную форму, «шапкой» которой является строго фиксированная последовательность атрибутов или наименований данных, а каждой строкой - соответствующая ей последовательность значений, описывающих конкретный объект учета (в данном случае – автомобиль). При этом название каждого атрибута (реквизита) характеризует некоторое общее свойство реальных объектов, например, «фамилия владельца», «марка, модель автомобиля». А конкретное значение реквизита описывает индивидуальное проявление данного свойства, например, «ПЕТРОВ», «ВОЛГА ГАЗ-31».
В связи с тем, что последние два компонента дополнительного изучения не требуют, рассмотрим подробно понятие базы данных и СУБД.
3. Понятие и организация базы данных
Информационный фонд автоматизированных информационных систем - совокупность всех данных, подлежащих накоплению, хранению, поиску, преобразованию и выдачи в установленном порядке, а также используемых для организации общения человека с ЭВМ.
Существуют два подхода к созданию информационных фондов - локальный и интегрированный.
При локальной структуре информационного фонда создаются массивы (файлы) данных, предназначенные для решения самостоятельных (отдельных) задач управления или их комплексов.
Файлы при этом обычно бывают простыми, последовательными наборами данных, полностью зависящими от программного обеспечения, используемого для их обработки, т.е. конкретных прикладных программ, при помощи которых к этим данным обращаются их пользователи.
Многие файлы локального информационного фонда формируются отдельно для каждого расчета, решения отдельных задач. Поэтому одни и те же данных, используемые в различных приложениях, обычно представляются в другой форме. Это ведет к тому, что в фонде создается большая избыточность или дублирование данных, возникают определенные трудности при их актуализации (обновлении). Практически при большом объеме фонда очень трудно сохранять все файлы на одном и том же уровне обновления.
В связи с этим пользователи часто могут обнаруживать явные противоречия в данных и испытывать определенное недоверие к ЭВМ. Кроме того, при постоянном изменении и расширении фонда локальных файлов возникает необходимость в модификации прикладных программ, которая требует значительных затрат.
Указанные недостатки локальных информационных фондов, в основном проявлялись в системах обработки данных на базе ЭВМ второго поколения. Полностью или значительно они отсутствуют в интегрированных или так называемых единых информационных фондах.
Единые фонды также могут иметь файловую структуру, но при этом данные, включаемые в определенный файл, имеют многоцелевое назначение. Тем самым уменьшается избыточность или дублирование данных, упрощается процесс обновления данных.
Для описания структур данных выделяют два способа: логический и физический.
Логическое описание структуры данных выглядит в виде, полностью готовом для представления пользователю (например, карточки исходной информации, таблицы выходных данных, отпечатанные на ЭВМ и т.д.).
Физическое описание отражает их реальное расположение в определенных ячейках памяти ЭВМ, а также методы доступа к указанным устройствам (например, физическое расположение данных на поле магнитного диска и организация прямого, т.е. без дополнительных устройств, доступа к этому диску оперативного запоминающего устройства ЭВМ).
При создании упомянутых выше локальных информационных фондов физическая и логическая структуры данных полностью совпадали, т.е. отсутствовала возможность по иному, чем физически записано на носителе информации, представлять последовательность и взаимосвязь данных в документах, предназначенных для пользователей. Соответственно любые требуемые изменения в той или иной структуре данных вызывали необходимость изменения всей системы описания данных.
Создание единых информационных фондов потребовало разделения физических и логических структур данных.
Разделение физической и логической структуры данных позволило обеспечить их независимость от прикладных программ. Это в свою очередь создало возможность перейти к новому уровню организации единых информационных фондов, получившему название базы данных. Практическая реализация концепции баз данных связана с внедрением ЭВМ третьего поколения.
База данных - это управляемый единый информационный фонд, содержащий не только соответствующим образом организованные и логически связанные между собой данные, но и систему их описания, а также средства, поддерживающие установленные информационные связи.
Для организации структур баз данных используется три способа: иерархический, сетевой и реляционный.
Иерархические структуры организации баз данных называют также деревьями.
Дерево представляет собой иерархию (строгий порядок расположения) элементов, называемых узлами (рис. 2.).
На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, является порожденным и связан только с одним узлом более высокого уровня (исходным узлом).
Рис. 2. Структура иерархической базы данных
По указанному принципу построена, например алфавитно-справочная картотека адресного бюро. В ней исходным элементом является фамилия зарегистрированного лица, а все остальные найденные сведения являются порожденными.
Иерархические структуры обладают достоинством надежного хранения сформированных данных, т.к. отдельные элементы данных лишь однозначно связаны между собой. Кроме того, иерархическая структура базы дает возможность организовать несколько способов поиска данных по их адресам. Причем эти способы поиска отличаются высокой логической четкостью, последовательностью и позволяют вести поиск требуемых данных с большой точностью и максимальной полнотой.
Но иерархические базы данных имеют и ряд существенных недостатков:
1. Необходимость составления сложного и громоздкого программного обеспечения;
2. Необходимость дублирования одних и тех же данных в описании их логической структуры;
3. Сложность поиска требуемых данных сразу по нескольким связям или признакам.
Многие из указанных недостатков устраняются применением сетевых структур организации баз данных или сетевых файлов.
К сетевым структурам приходится обращаться во всех случаях, если в отношениях или связях между данными порожденный элемент имеет более одного исходного элемента. В сетевой структуре любой элемент может быть связан с любым другим элементом (рис. 3.).
Рис. 3. Структура сетевой базы данных
Наглядным примерам сетевых структур является генеалогическое дерево с указанием родственных связей, где каждый ребенок порожден от двух родителей.
Другим примером связи сетевых структур является квалификация степени наказания (статьи УК РФ) на основании отношения лица к преступлению (организатор, соучастник, исполнитель и т.д.), способа совершения (в группе, в одиночку и т.д.), а также возможно и других исходных данных.
Сетевые структуры имеют некоторые преимущества в описании данных по сравнению с иерархическим подходом. Смысл этих преимуществ можно свести к гораздо большему перечню возможностей и разнообразию услуг для пользователей сетевых баз данных. В первую очередь данное положение относится к многоаспектному (т.е. по многим признакам) поиску требуемых данных.
Вместе с тем расширение количества связей между элементами данных приводит к определенной трудности в общении с сетевыми базами данных (требует применения «не-фон-неймановских», например, параллельных структур ЭВМ с ассоциативным подходом). Это составляет главный недостаток сетевого подхода.
Дальнейшее развитие способов организации баз данных привело к разработке и внедрению реляционных структур данных.
Реляционный подход (табличный подход) к описанию структур данных основывается на представлении их в виде двумерных таблиц (рис. 4.). Такое представление данных является одним их наиболее естественных и понятных для пользователей.
Строкой такой таблицы является запись (документ) как единица логического описания данных, а каждый столбец является набором значений какого-либо атрибута или признака для всего перечня записей.
К основным преимуществам реляционных структур относятся:
1. Простота понимания и работы с базой.
2. Простота развития и дополнения базы.
3. Простота исключения несанкционированного доступа к закрытым данным.
4. Простота осуществления многоаспектного поиска требуемых наборов данных.
| Атрибут 1 | Атрибут 2 | Атрибут 3 | |
| | | | . . . Запись 1 |
| | | | . . . Запись 2 |
| | | | . . . Запись 3 |
Рис. 4. Структура реляционной базы данных
В заключение необходимо указать, что в настоящее время наибольшее распространение в стране (и в мире) нашли реляционные и различным образом комбинированные способы организации баз данных. В особенности это относится к базам данных на персональных ЭВМ.
4. Системы управления базами данных и их основные функции
Приведем два определения СУБД.
СУБД – программно-логический аппарат (специальный пакет программ), организующий создание, ведение и выдачу данных.
СУБД - это программная система, обеспечивающая создание, актуализацию и выдачу данных из базы с соблюдением основных требований автоматизированной системы, в которой она установлена.
В любом варианте подчеркивается программный смысл СУБД, организованной в соответствии со структурой базы данных.
Основные функции, выполняемые СУБД, следующие:
1 - создание базы данных;
2 - ведение базы данных в банке данных;
3 - поддержание целостности данных и логический контроль вводимых данных;
4 - обеспечение выборки нужных данных и выдача результатов пользователю в заданной форме;
5 - соблюдение приоритета и санкционирование доступа к данным.
Рассмотрим содержание указанных функций на примере образца реляционной структуры базы данных - обобщенной таблицы, содержащей сведения о владельцах автомобилей.
1. Создание базы данных заключается в обеспечении необходимой упорядоченности и связности накапливаемых и хранимых данных.
В нашем случае СУБД задает табличную форму, «шапкой» которой является строго фиксированная последовательность атрибутов или наименований данных, а каждой строкой - соответствующая ей последовательность значений, описывающих конкретный объект учета (в данном случае – автомобиль). При этом название каждого атрибута (реквизита) характеризует некоторое общее свойство реальных объектов, например, «фамилия владельца», «марка, модель автомобиля». А конкретное значение реквизита описывает индивидуальное проявление данного свойства, например, «ПЕТРОВ», «ВОЛГА ГАЗ-31».