ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 12.11.2020
Просмотров: 2499
Скачиваний: 17

150
Глава 4. Статистические методы в политическом анализе
Таким образом, происходит «растягивание» дистанций: большие
расстояния становятся многократно больше, незначительные же уве
личиваются не столь существенно. Большим расстояниям придается
больший
вес,
отсюда и название меры близости. Для наших данных
матрица расстояний во взвешенной евклидовой метрике имела бы
следующий вид:
«Яблоко»
«Единство»
Б Ж
О В Р
К П Р Ф
С П С
«Яблоко»
«Единство»
124,81
Б Ж
695,33
262,87
ОВР
17830,31
20576,99
25378,81
К П Р Ф
96,14
405,48
1277,05 15388,04
С П С
82,49
392,12
1227,05 15803,83
27,87
Так, расстояние «"Яблоко" — СПС» увеличилось с 9 до 82, тогда
как расстояние «БЖ — ОВР» — со 159 до 25 378. Такой прием может
понадобиться тогда, когда различия расстояний между объектами не
значительны и структура объектов ненаглядна. В нашем же случае го
раздо удобнее использовать обычное евклидово расстояние.
Принципиально иной метод вычисления матрицы расстояний ос
нован на
парном корреляционном анализе Пирсона,
о котором подробно
говорилось выше. Сначала вычисляется матрица парных корреляций,
которая для наших данных будет иметь вид:
«Яблоко»
«Единство»
Б Ж
ОВР
К П Р Ф
С П С
«Яблоко»
«Единство»
- 0 , 3 1
Б Ж
-0,68
0,51
О В Р
- 0 , 7 6
-0,14
0,51
К П Р Ф
0,58
- 0 , 4 3
-0,79
-0,48
С П С
0,86
- 0 , 3 3
-0,82 -0,82 0,59
Затем коэффициенты корреляции преобразуются в расстояния с
помощью простейшей формулы:
dist=
1 -
г.
4.6. Кластер-анализ
151
«Яблоко»
«Единство»
Б Ж
О В Р
К П Р Ф
С П С
«Яблоко»
«Единство»
1,31
Б Ж
1,68
0,49
О В Р
1,76
1,14
0,49
К П Р Ф
0,42
1,43
1,79
1,48
С П С
0,14
1,33
1,82
1,82
0,41
Плотная положительная корреляция «СПС — "Яблоко"» ( г = 0,86)
стала наименьшим расстоянием — 0,14. Плотная отрицательная кор
реляция «БЖ — СПС»
(г=
-0,82) стала наибольшим расстоянием —
1,82. Следует оговориться, что мера расстояния 1 -
г
не используется;
если кластеризация случаев осуществляется на основании всего двух
переменных, она будет давать только значения -1 или + 1.
После вычисления матрицы парных расстояний можно присту
пать к ф о р м и р о в а н и ю д е н д р о г р а м м ы . Однако и н а этой
стадии мы имеем достаточно широкий набор опций. Основной во
прос состоит в том, каким образом связывать вместе несколько объ
ектов, как следует определить расстояния между кластерами, т.е. не
обходимо выбрать
правило объединения
(или
правило связи).
Как и в
случае с мерой близости, в статистических программах имеется около
семи вариантов выбора правила объединения. Основные из них: оди
ночная связь (метод ближайшего соседа), полная связь (метод даль
них соседей), невзвешенное и взвешенное попарное среднее, невзве-
ш е н н ы й и взвешенный центроидный метод, метод Варда.
Например, в случае использования метода
ближайшего соседа
(near
est neighbour, single linkage) расстояние между двумя кластерами опре
деляется расстоянием между двумя наиболее близкими объектами в
различных кластерах. Построение дендрограммы начинается с нахож
дения наименьшего значения среди всех парных расстояний. В методе
дальних соседей
(complete linkage), напротив, расстояния между класте
рами определяются наибольшим расстоянием между любыми двумя
объектами в различных кластерах. Соответственно, формирование
дендрограммы начинается с поиска самой удаленной пары объектов.
Как выбирать меры близости и правило объединения? В некото
рых случаях существуют четкие критерии. Так, процент несогласия
как мера расстояния «работает» только на категориальных данных.
Однако чаще простых и ясных критериев не существует. Чтобы с ходу
«попасть в яблочко», требуются серьезная статистическая подготовка
и глубокое понимание специфики изучаемых объектов. Практичес
кие же советы таковы:
Вариацией евклидова расстояния является
взвешенное евклидово
расстояние.
Эта мера близости отличается тем, что отсутствует опера
ция извлечения квадратного корня:

152
Глава 4. Статистические методы в политическом анализе
1
. Следует, не ограничиваясь одной мерой близости и одним пра
вилом объединения, пробовать различные комбинации (конечно, в
разумных пределах). Особого внимания заслуживает общее в кластер
ной структуре объектов, обнаруживаемое в разных сочетаниях.
2. Необходимо проводить содержательную интерпретацию получа
емых результатов, ни в коем случае не ограничиваясь «механическим
перебором».
В продолжение рассмотрения нашего примера с электоральной
статистикой построим четыре дендрограммы, используя комбинации
мер расстояния (евклидово и
1 -
г)
и правил связи (полная и одиноч
ная связь).
Сопоставляя полученные результаты, попробуем найти общие мо
менты и дать им содержательное объяснение.
Так, на трех дендрограммах (1,2,4) четко видно изолированное по
ложение блока «Отечество — вся Россия» (ОВР). Н а п о м н и м , что кла
стер-анализ осуществлялся на данных избирательных комиссий рай
онов Москвы, мэр которой Ю.М. Лужков являлся одним из лидеров
4.6. Кластер-анализ
!53
блока. При этом парламентские выборы в декабре 1999 г. проходили
одновременно с выборами столичного главы. Несомненно, все это
способствовало более четкому позиционированию ОВР в глазах сто
личных избирателей.
На всех дендрограммах фиксируется близость «Яблока» и С П С ,
причем в двух случаях (3,4) это наименьшее расстояние между объек
тами. Здесь «московская специфика», скорее всего, ни при чем — бли
зость электората С П С и «Яблока» в территориальном разрезе являлась
на тот момент общероссийской тенденцией (мы уже рассматривали
этот вопрос в параграфе, посвященном корреляционному анализу).
Общероссийской закономерностью на парламентских выборах 1999 г.
являлась также близость в территориальном разрезе электоратов
«Единства» и «Блока Жириновского» (все дендрограммы).
Больше вопросов вызывает близость, с одной стороны, С П С и
«Яблока», с другой — К П Р Ф . Казалось бы, эти партии в значительной
мере полярны по своим идеологическим установкам. Ключ к ответу
содержится, вероятно, в дендрограммах 3 и 4, демонстрирующих кар
тину двух противостоящих кластеров: «"Единство" — БЖ — ОВР» и
«СПС — " Я б л о к о " — КПРФ». Содержательное различие между двумя
кластерами можно представить как признак отсутствия/наличия вы
раженной политической идеологии. «Правые» С П С и «Яблоко» и «ле
вая» К П Р Ф были четко позиционированы в политико-идеологичес
ком спектре, в отличие от «партий власти» ОВР и «Единства» (и в
меньшей степени «Блока Жириновского»). Таким образом, можно
предполагать наличие «раскола» (электорального размежевания) в
Москве по л и н и и «идейные» — «властные» партии.
К проблеме интерпретации структур электорального выбора мы
вернемся, когда будем рассматривать факторный анализ.
Метод К-средних
При всех сильных сторонах иерархического кластер-анализа он обла
дает одним существенным недостатком. С ним трудно работать при
наличии большого числа объектов, так как дендрограммы становятся
перегруженными и теряют наглядность. В таких случаях используют
другой метод кластеризации —
метод К-средних.
Впрочем, этот метод
весьма эффективен и при незначительном количестве объектов: его
можно и нужно сочетать с древовидной классификацией для получе
ния более надежных результатов.
Принципиальное отличие метода К-средних от иерархического кла
стер-анализа заключается в том, что исследователю необходимо изна-
154
Глава 4. Статистические методы в политическом анализе
чально определить число кластеров, на которое требуется разбить
изучаемую совокупность. Соответственно, желательно еще до начала
анализа иметь гипотезу о структуре исследуемой совокупности. В ином
случае рекомендуется «разведочный» алгоритм: сначала совокупность
делится на два кластера, затем на три и так до тех пор, пока не будет
найдено оптимальное число кластеров.
Вычислительный алгоритм кластеризации в методе К-средних
можно проиллюстрировать простейшим примером. Предположим,
мы имеем пять объектов —
а, Ь, с, d, е, —
для каждого из которых за
даны координаты:
а
Ъ
с
d
е
X
1
3
2
10
9
У
1
2
0
11
12
Уже на диаграмме рассеяния мы видим, что объекты должны быть
сгруппированы в два четких кластера. Однако к этому еще необходи
мо прийти математическим путем.
1. Центры кластеров (их число определено исследователем, в на
шем случае их два) задаются случайным образом. Предположим, слу
чайные координаты центра первого кластера (3;3), второго — (8;8).
2. Рассчитываются расстояния от центров кластеров до всех объек
тов (используется евклидово расстояние). В нашем случае матрица ев
клидовых расстояний будет такой:
а
b
с
d
е
Центр 1
2,83
1
3,16
10,63
10,82
Центр 2
9,89
7,81
10
3,60
4,13
3. Объекты «приписываются» к тем кластерным центрам, к кото
рым они ближе находятся. Так, объекты
a, b
и
с
приписываются к пер
вому кластеру, объекты
d
и
е
— ко второму.
4.6. Кластер-анализ
Затем производится смещение центров кластеров таким образом,
чтобы минимизировать расстояние между объектами внутри класте
ров и максимизировать расстояние между кластерами.
4. Вычисляются средние значения переменных для объектов каж
дого кластера:
Средние — кластер 1 Средние — кластер 2
X
2
9,5
У
1
11,5
5. Вычисленные средние становятся координатами нового центра
каждого кластера.
6. Повторяются шаги 2—5 до момента, когда кластерные центры
перестанут «мигрировать» и займут устойчивое положение.
В нашем простейшем случае это происходит уже на первой итера
ции. Координаты центра первого кластера — (2;1), второго — (9,5;
11,5). Расстояния от центров кластеров до всех объектов:
а
b
с
d
е
Центр 1
1
1,4
1
13
12,9
Центр 2
13,5
11,5
13,7
0,7
0,7

156
Глава 4. Статистические методы в политическом анализе
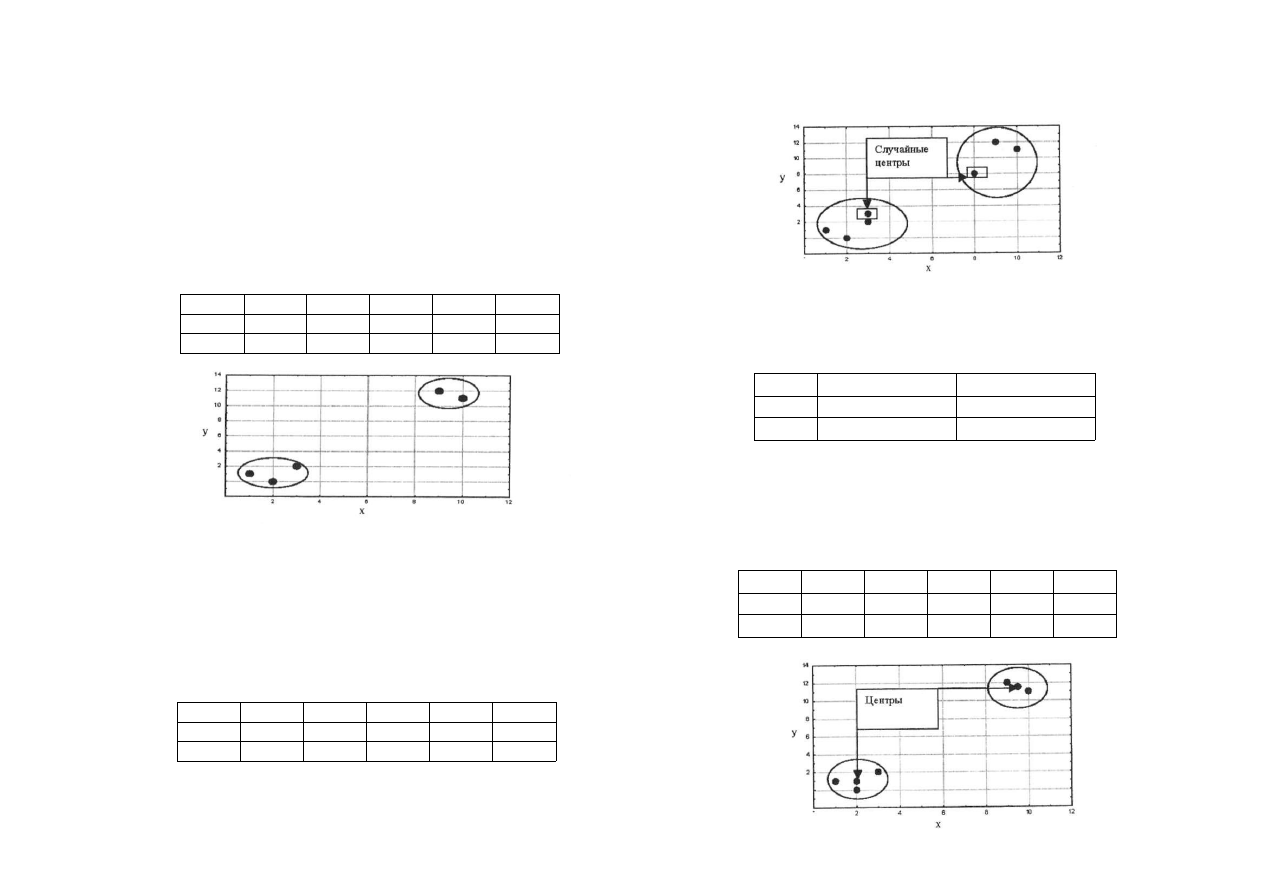
Одна из проблем метода К-средних состоит в том, что результат
классификации может оказаться зависимым от начальных позиций
кластерных центров, которые выбираются случайно. Если существует
несколько устойчивых положений центров кластеров, анализ остано
вится только на одном из них, не обязательно оптимально отражаю
щем структуру изучаемой совокупности. Один из таких примеров
приводится на рисунке ниже.
О О
© О о •
Вернемся к нашему примеру с голосованием за политические пар
тии и попробуем поработать с этими данными с помощью метода К-
средних.
Сначала разобьем объекты на два кластера. Мы уже имеем пред
ставление о структуре совокупности благодаря ранее проведенному
иерархическому анализу, поэтому можем сформулировать предполо
жение о том, как произойдет разбиение. Скорее всего, оно будет соот
ветствовать дендрограммам 1 и 2, поскольку метод К-средних исполь
зует евклидову метрику, т.е. мы получим классификацию «ОВР — все
остальные».
Так и происходит (числа указывают расстояние каждого объекта до
кластерного центра):
Кластер 1 «Яблоко» «Единство»
Б Ж
К П Р Ф
С П С
Расстояние
1,003274
1,826990
5,639210
3,332240
3,184501
Кластер 2
ОВР
Расстояние
0
При разбиении совокупности объектов на три кластера картина
получается также вполне ожидаемая — в полном соответствии с на
шей содержательной интерпретацией дендрограмм.
4.6. Кластер-анализ
157
Сравнивая внутрикластерные расстояния, можно заметить, что клас
тер «"Единство" — БЖ» является менее плотным (однородным), нежели
кластер «"Яблоко" — С П С — К П Р Ф » . Это также вполне согласуется с
результатами иерархического кластер-анализа. Кроме того, с помощью
данных о расстоянии объекта до центра кластера можно определить, на
сколько «типичным» является данный объект для кластера. Иными сло
вами, находится ли он на периферии (и, следовательно, вполне может
быть «притянут» другим кластером) или непосредственно возле центра
кластера (т.е. является типичным представителем кластера).
Кроме принадлежности объектов к кластерам и размера расстоя
ний до кластерных центров метод К-средних может дать нам и другую
полезную и н ф о р м а ц и ю , в частности позволит узнать координаты
каждого кластерного центра. В нашем случае их будет 16 (по числу
районов).
Район
Номер кластера
Район
3
1
2
Алексеевский
3,93
39,83
12,77
Алтуфьевский
5,56
43,57
9,42
Бабушкинский
4,86
42,03
10,71
Бибирево
6,40
40,25
10,47
Бутырский
4,83
40,51
11,45
Лианозово
4,94
45,20
9,71
Лосиноостровский
4,46
43,64
10,85
Марфино
4,69
44,25
10,51
Марьина Роща
4,67
41,07
11,43
Останкинский
3,85
39,97
12,52
Отрадное
5,06
42,42
10,57
Ростокино
4,60
41,66
11,11
Свиблово
4,55
43,16
10,49
Северное Медведково
4,94
45,27
9,83
Южное Медведково
4,72
44,52
10.19
Ярославский
4,78
44,25 10,31

158
Глава 4. Статистические методы в политическом анализе
Можно классифицировать любой объект, не участвовавший в ана
лизе, зная его значения по переменным и координаты центров (в на
шем случае — еще одна партия с результатами голосования по райо
нам). Для этого надо вычислить расстояния (в евклидовой метрике)
до центра первого, второго и третьего кластеров и отнести объект к
ближайшему из них.
Мы также имеем данные расстояний между кластерными центра
ми. В нашем случае наиболее удаленным от всех других является кла
стер с единственным объектом — ОВР (№ 1).
№ 1
№ 2
№ 3
№ 1
№ 2
31,9
№ 3
37,8
6,1
Профессиональные статистические программы позволяют про
сматривать результаты дисперсионного анализа переменных, по ко
торым проходит классификация объектов методом К-средних. Так,
можно оценить вклад каждой переменной в разбиение совокупности
на кластеры. Об этом свидетельствуют следующие показатели:
• насколько кластеры различаются между собой по этой перемен
ной (межгрупповая дисперсия);
• вариативность объектов внутри кластера по данной переменной
(внутригрупповая дисперсия);
• отношение межгрупповой и внутригрупповой дисперсий (^-от
ношение). Чем сильнее различия между кластерами и чем выше одно
родность объектов внутри кластеров, тем больше /"-отношение.
Рассмотрим некую «инверсию» нашего примера с голосованием за
партии в Москве: в качестве объектов классификации возьмем райо
ны Северо-Восточного АО, а в качестве переменных — политические
партии. Разбив совокупность из 16 районов на 4 кластера, посмотрим
на статистику дисперсионного анализа:
Межгрупповая
дисперсия
Внутригрупповая
г
3 v vl
F-отношение
дисперсия
«Яблоко»
5,96
2,23
10,67
«Единство»
4,31
6,07
2,84
Б Ж
2,20
1,63
5,40
ОВР
48,59
4,83
40,22
К П Р Ф
3,09
4,72
2,61
С П С
35,41 3,30
42,95
4.6. Кластер-анализ
159
Как видим, вклад переменных в формирование кластеров очень
неравномерен. Кластерообразующими являются прежде всего пере
менные С П С и ОВР.
Кластер-анализ в исследовании образов политических лидеров
Одна из сфер применения кластер-анализа, наряду с исследованиями
электорального поведения, — изучение образов политиков, формиру
ющихся в сознании населения.
Подобные исследования прежде всего требуют особым способом
представленной исходной информации. Сам по себе образ политика
как субъективное отражение его личности — сложная, синкретичная
совокупность представлений, ощущений, оценок, ассоциаций. Непо
средственный анализ образа статистическими методами невозможен.
Поэтому в политической психологии и социологии существует прием
«разложения» целостного образа на совокупность признаков, кото
рые выступают его
дескрипторами.
Наиболее часто в качестве дес
крипторов берутся качества, которые респондент приписывает (или
не приписывает) данному политику.
Ниже приводятся данные социологического опроса, проведенного
Всероссийским центром изучения общественного мнения ( В Ц И О М )
в марте—апреле 2000 г. Исследование было посвящено представле
н и я м о л и ч н ы х качествах р о с с и й с к и х политиков (В.В. Путин,
Е.М. Примаков, Г.А. Зюганов, Г.А. Явлинский, В.В. Жириновский,
Б.Н. Ельцин) в глазах населения. Основным вопросом анкеты был:
«Какие из перечисленных качеств российских политиков в наиболь
шей степени свойственны ... ?» Ниже в таблице приводятся результа
ты исследования (данные стандартизированы — переведены из чис
лового в процентный формат).
Путин Примаков Зюганов Явлинский
Жири
новский
Ельцин
Опыт политической дея
тельности
5,8
25,0
22,1
16,8
10,1
20,2
Активность, энергич
ность
32,5
3,8
9,6
11,5
37,6
5,1
Профессиональные, ин
теллектуальные качества 17,5
31,5
16,1
22,4
4,9
7,7
Умение связно излагать
свои мысли
23,2
14,8
15,5
26,1
16,9
3,5