Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 396
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
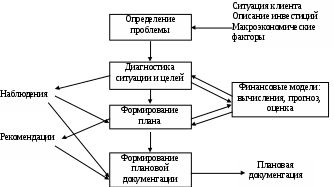
Рис. 9.3. Архитектура ЭС Plan-Power
Диагностическая подсистема анализирует финансовую ситуацию клиента, прогнозирует ее развитие и формирует список достоинств и недостатков. По этим данным формируются возможные цели инвестирования, которые сопоставляются с введенными пользователями.
Подсистема планирования (планировщик) включает модули размещения активов, страхования, налоговых платежей, продажи активов, которые в процессе планирования координируются между собой.
Подсистема оформления плановой документации включает:
результаты диагностики клиентской ситуации;
рекомендации по действиям;
объяснения рациональности этих действий.
Экспертная система функционирует как посредством прямого вывода планируемых рекомендаций, так и обратного вывода для проверки конкретных финансовых целей.
Экспертная система мониторинга портфеля инвестиций
Для решения задач мониторинга портфеля инвестиций чаще всего используются методы технического анализа и прогнозирования рыночных цен, по которым можно предсказывать изменение доходности и надежности конкретных финансовых инструментов – ценных бумаг, валюты, драгоценных металлов. В техническом анализе рассматриваются тенденции в движении цен (например, предполагается периодическое их колебание).
Технический анализ осуществляется на основе:
гистограмм цен и оборота ценных бумаг;
диаграмм скользящих средних;
графиков моделей движения цен.
В результате анализа различных графиков пользователю выдаются обобщенные рекомендации.
Для более оперативного анализа рынка в течение торгового дня могут использоваться ЭС реального времени, например J2.
В системе FOREX-94 используемые нейронные сети прогнозируют решения о покупке / продаже валюты на основе их обучения по изменениям курсов валют за определенные периоды времени.
Глава 10. Системы, ориентированные
на естественно-языковые запросы. Машинное обучение
10.1. Естественно-языковые интерфейсы
Повышение уровня интеллекта компьютера – процесс бесконечный. При создании антропоморфной (подобной человеку) искусственной интеллектуальной системы разработчики стремятся заложить в нее человеческие способности:
к выделению существенного в накопленных знаниях;
извлечению следствий из накопленных знаний, т.е. к рассуждению;
оценке знаний и действий;
аргументированному принятию решения с использованием результатов рассуждений;
рационализации идей;
целеполаганию и планированию;
поиску объяснения как ответа на вопрос «почему?»;
адаптации в условиях изменения жизненной ситуации;
созданию целостной картины относительно предмета мышления;
обучению.
В настоящее время наиболее интенсивные исследования ведутся в следующих направлениях:
внешняя интеллектуализация систем совершенствование диалоговых интерфейсов;
внутренняя интеллектуализация систем создание компиляторов новой архитектуры;
моделирование отдельных функций творческих процессов (игра
в шахматы, доказательство теорем);
целенаправленное поведение роботов, способных автономно со-вершать операции по достижению целей.
В рамках первого направления разрабатываются естественно-языковые (ЕЯ) интерфейсы «человек – компьютер», предполагающие применение БЗ.
Эксплицитные (осознанные) знания основываются на вербальных формах репрезентации (представления), а имплицитные (бессознатель-ные) базируются на вербальных и невербальных формах репрезентации (рис. 10.1).
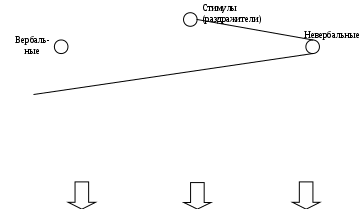
| Вербальные знания структуриро-ванные | Вербальные ассоциации структуриро-ванные, распознава- емые | Вербальные ассоциации структуриро-ванные, нераспознава- емые | Вербальные ассоциации неструктури-рованные, нераспознава- емые | Невербальные ассоциации, образные | |
| Эксплицитные знания | Имплицитные знания | ||||
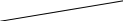







| База эксплицитных знаний | База вербальных знаний (активных) | База невербальных имплицитных знаний (пассивных) |
| База ролевых эталонных семантических структур | Невербальная ассоциативная (коннекционистская) сеть | |
| Вербальная семантическая сеть | Вербальная ассоциативная сеть | |
Рис. 10.1. Связь между видами знаний
и формами их репрезентации
Под экспликацией понимается процедура уточнения знания тер-минов в рамках данной научной теории. Эксплицитные знания всегда дискретны, вербальны и структурированы. Второй формой эксплицитных вербальных знаний являются ассоциации, которые должны обладать всеми
признаками формальных языков (такими как входной алфавит, правила преобразований и образования выражений, правила интерпретации). Как и структурированные вербальные знания, экспликация содержания ассоциаций предполагает наличие ролевых эталонных семантических структур, представляющих собой фреймы, в слотах которых находятся маркеры ролей элементов, составляющих сценарий. Подстановка ролей в слоты осуществляется во время обучения системы.
Имплицитные знания могут быть как вербальными, так и невер-бальными. Имплицитность выражается в смутном представлении каких-либо объектов, их свойств или состояний и отличается отрывочностью, хаотичностью бессвязных нагромождений вербальных ассоциаций или невербальных образов. С формальной точки зрения имплицитность ха-рактеризуется отсутствием одного или нескольких признаков формальных систем.
По своей природе имплицитные знания делят на активные и пассивные. Активные – дискретные знания, форма представления которых позволяет обрабатывать их непосредственно формальными правилами комбинаторной семантики. Пассивные – недискретные и невербальные знания.
Первый уровень машинного понимания предполагает использование при ответе на вопросы содержания, отражаемого текстом. Модели, с помощью которых воссоздаются знания экспертов, характеризуются различным уровнем синтаксичности. Высокий уровень синтаксичности приводит к ошибочной автоматической интерпретации модели.
Естественно-языковое общение с ИИС предполагает выполнение функций:
ведения диалога – определение его структуры и той роли, которую система и пользователь выполняют на текущем шаге диалога;
понимания – преобразование поступающих от пользователя вы-сказываний на ЕЯ в высказывания на языке внутреннего представления;
обработки высказываний – формирование или определение знаний для решения задач на данном шаге диалога;
генерации – формирование выходных высказываний на ЕЯ (рис. 10.2).
Ведение диалога состоит в обеспечении целесообразных действий системы на текущем шаге. При этом диалог может вести пользователь или система. Вторая задача диалогового компонента обусловлена тем, что реакция одного участника может не соответствовать ожиданиям другого. В зависимости от того, кто перехватывает инициативу, система либо формирует перехват, либо обрабатывает его.
Диалоговый компонент
Обработка перехватов инициативы
Ведение диалога
Компонент понимания высказываний
Компонент генерации высказываний
Анализ высказываний
Интерпретация высказываний
Генерация смысла высказываний
Синтез высказываний
Рис. 10.2. Обобщенная схема ЕЯ-системы
Компонент понимания высказываний предназначен для выделения смысла входного высказывания и выражения этого смысла на внутрен-
нем языке системы. Под смыслом понимается семантико-прагматическая информация, которую пользователь хочет передать системе. На этапе анализа выделяются описания сущностей, упомянутых во входном высказывании, выявляются свойства этих сущностей и отношения между ними. Анализ обычно выполняется отдельным блоком. Интерпретация заключается в отображении входного высказывания на знания системы. Основными задачами данного этапа являются буквальная интерпретация высказывания в контексте диалога. Буквальная интерпретация заключается в том, чтобы, учитывая контекст диалога, идентифицировать образы тех сущностей области интерпретации, которые имел в виду говорящий. Другая задача интерпретации состоит в том, чтобы, применяя имеющиеся у системы методы вывода, определить, как обрабатываемое высказывание соотносится с целями и планами участников диалога.
Компонент генерации высказываний решает в соответствии с ре-зультатами, полученными остальными компонентами системы, две основ-ные задачи:
генерации смысла, т.е. определения типа и смысла выходного высказывания системы во внутреннем представлении;
синтеза высказывания – преобладание смысла в высказывании на ЕЯ.
Диалог можно рассматривать на трех уровнях структуры:
общей, характеризующей тип диалога и класс решаемых задач;
тематической, отражающей структуру конкретной задачи;
шага диалога, отражающей взаимодействие участников в элемент-ном акте диалога.
На уровне глобальной структуры действия системы обычно задаются в виде последовательности этапов, определяемых в зависимости от класса решаемых задач. В случае общения с ЭС глобальная структура включает инструктаж, определение задачи, решение задачи, объяснение в ходе решения задачи, выдачу результатов и их оценку, объяснение после решения задачи, определение причин неудачи. Глобальная структура задается декларативно с помощью правил-продукций.