Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 398
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Тематическая структура диалога обычно представляется в виде сценария, в рамках которого определяются структура задачи (разбиение на подзадачи); распределение подзадач между участниками общения; языковые средства. Используются два основных класса для задания сценария диалога: сценарий либо встроен в систему, либо генерируется системой. Готовый сценарий может быть задан в виде частично упорядоченного множества правил с параметрами, значения которых устанавливаются в процессе решения конкретной задачи. Использование готовых сценариев целесообразно в тех случаях, когда к системе предъявляются жесткие требования по быстродействию.
Если сценарий генерируется системой, то в диалоговый компонент включается специальный механизм вывода. Генерация сценариев диалога целесообразна в тех случаях, когда структура задачи зависит от контекста ситуации, в которой происходит ее решение, а полный перечень ситуаций не может быть определен заранее.
При задании локальной структуры шага диалог состоит из действия, реакции и характеризуется такими параметрами, как тип инициирования, способ влияния действия на реакцию и способ спецификации подзадачи, решаемой на данном шаге.
Понимание высказываний включает анализ и интерпретацию. В ме-тодах анализа обычно выделяют анализ слов, предложений и текстов. Анализ слов сводится к морфологическому анализу, обнаружению и исправлению орфографических ошибок. Цель морфологического анализа состоит в получении основ (словоформ с отсеченным окончанием) со значениями грамматических категорий для каждой из словоформ вы-сказывания на ЕЯ.
Методы обнаружения и исправления орфографических ошибок подразделяются на методы, не использующие словари и использующие их. К методам, не использующим словари, относятся частотные и поли-граммные. Частотные основаны на сортировке слов по частоте их встречаемости в текстах. Предполагается, что частота встречаемости слов, содержащих ошибки, низкая. В полиграммных методах для поиска ошибок применяют списки возможных сочетаний букв в словах. Методы, в ко-торых используются словари, зависят от типа применяемой стратегии.
К абсолютным относится «исторический» метод, основанный на словаре встречаемых ранее ошибок. Эффективность его зависит от размера проанализированных текстов. Относительный метод состоит в нахождении в словаре таких слов, которые наиболее похожи на искаженное слово, и выборе среди них правильного.
Анализ предложений обычно сводится к синтаксическому и се-мантическому анализу, выполняемому функциональным блоком-анализатором.
Существует несколько типов анализаторов:
традиционные (не допускают отклонений от грамматических норм);
концептуальные (позволяют анализировать ЕЯ предложения в условиях пропуска и повтора слов);
использующие сопоставление по образцам (позволяют анализи-ровать предложения, отклоняющиеся от традиционной грамматики в произвольной степени).
Методы анализа связного текста (дискурса). Связность текста достигается как лингвистическими средствами, имеющими языковое выражение, так и экстралингвистическими (ситуационными) средствами-«умолчаниями», не имеющими языкового выражения и основанными на общности знаний участников общения о цели общения и проблемной области. На этапе анализа связного текста решается задача выявления связей между предложениями, выражаемых лингвистическими сред-ствами, а на этапе интерпретации ситуационными.
К основным лингвистическим средствам связи предложений относятся ссылки и эллипсис. В проблеме установления ссылок могут быть выделены две задачи: поиск в предыдущих предложениях (контексте) сущности (референта), обозначаемой данной ссылкой; определение соответствия между референтом и ссылкой.
Под эллипсисом понимается сжатая форма высказывания, смысл которой определяется либо предыдущими высказываниями (текстовый эллипсис), либо ситуацией, имеющей место в проблемной области (ситуативный эллипсис).
На этапе интерпретации решаются две основные задачи: буквальная интерпретация высказываний в контексте диалога и интерпретация целей участников общения. Для решения обеих задач в рамках фрейм-представлений используется единый механизм присвоения имени фреймов, при этом структура целей участников общения определяется структурой фрейма, описывающего данную задачу, а подцели состоят в заполнении слотов.
Процесс генерации высказываний состоит из генерации смысла высказывания и синтеза высказывания на ЕЯ. Первый этап называется внелингвистическим (концептуальным) синтезом, а второй лингви-стическим синтезом. Результатом выполнения первого этапа является внутреннее представление смысла генерируемого высказывания (опре-деление информации, которая должна быть сообщена пользователю, определение уровня общности информации, включаемой в высказывания, разбиение сообщаемой информации на части и др.). На втором этапе определяется последовательность построения синтаксической структуры отдельных предложений, морфологического синтеза словоформ. Наиболее простым методом генерации высказываний является метод, который основан на использовании заранее заготовленных шаблонов, содержащих текст на ЕЯ и переменные, вместо которых подставляются конкретные данные (описание сущностей). При методе шаблонов генерация высказываний осуществляется совместно с диалоговым компонентом, который идентифицирует стандартную ситуацию и определяет, какая информация должна быть включена в высказывание. Генерация вы-сказываний, которые не могут быть описаны с помощью шаблонов, представляет собой более сложную задачу. К таким высказываниям, в частности, относятся объяснения,
генерируемые в качестве ответов на вопросы, областью интерпретации которых являются абстрактные знания и метазнания системы. Для генерации объяснений требуется достаточно тонкая классификация целей создания ЕЯ-текстов. Организация текста определяется дискурсными целями (например, дать определение, описать, сравнить, уточнить и т.п.). Каждой дискурсной цели может быть со-поставлен определенный способ организации текста, называемый дискурс-ной стратегией. Предполагается, что, выявив дискурсные стратегии и выразив их подходящим формальным представлением, можно получить достаточно надежный и эффективный механизм генерации смысло-порождающих текстов.
10.2. Машинное обучение
Машинное обучение – это синоним процедуры приобретения знаний, которая может быть использована, когда эксперт по знаниям отсутствует, либо недостаточно надежен, либо ограничен во времени, либо его услуги чрезмерно дороги.
Процесс обучения машины в общем случае поясняется на рис. 10.3 [16].
Система генерирует знания, полученные в результате изучения среды. В процессе сравнения выходов ИИС и объекта информатизации в соответствии с критерием выявляется расхождение между результатами реального мира и выходом системы. Цель заключается в том, чтобы трансформировать реакцию среды и оценку в соответствии с критерием
в форму знания.
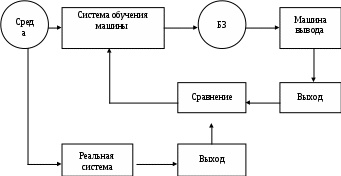
Рис. 10.3. Модель обучения
Существует три варианта приобретения знаний, которые позволяют реализовать процедуру машинного обучения, используя [1, 2]:
интерактивные программы, которые извлекали бы знания непосред-ственно у эксперта в процессе его общения с компьютером (без участия когнитолога). При этом диалоговая система должна обладать некоторым запасом базовых знаний о некоторой предметной области;
программы, способные обучаться, читая тексты. Этот метод «упирается» в проблему машинного распознавания смысла естественного текста;
программы, способные под руководством человека-учителя из-влекать из предъявляемых им примеров реализации некоторого концепта набор атрибутов и значений, определяющих этот концепт.
Любая программа обучения должна обеспечивать возможность сохранять и анализировать полученный опыт, а также обладать способностью применять его при решении новых проблем.
Индуктивное обучение заключается в том, чтобы вывести применимые правила из изучения прошлых специфических примеров. Таким образом, индуктивное обучение также является обучением с использованием примеров. В основу индуктивного обучения положены принципы индуктивных умозаключений. Индуктивным называется умозаключение, в котором на основании принадлежности признака отдельным предметам или частям некоторого класса делается вывод о его принадлежности к классу в целом. Одна из форм индуктивного обучения предусматривают демонстрацию примеров двух типов – тех, которые соответствуют концепту (это так называемые позитивные экземпляры), и тех, которые ему не соответствуют (негативные экземпляры). Задача программы обучения – выявить или сконструировать подходящий кон-цепт, т.е. такой, который включал бы все позитивные экземпляры и ни одного негативного. Такой тип обучения получил название «обучение концептам». Другая задача обучения – обобщение дескрипторов – формулируется так: программе обучения предъявляется набор экземпляров объектов некоторого класса, т.е. представляется некоторый концепт, а
программа должна сформировать описание, которое позволит иденти-фицировать (распознать) любые объекты этого класса. Отличие между задачами состоит в следующем:
задача обучения концептам предполагает включение в обучающую выборку как позитивных, так и негативных экземпляров заранее заданного набора концептов, а в процессе ее решения будет сформировано правило, позволяющее затем программе распознать ранее неизвестные экземпляры концепта;
задача обобщения дескрипторов предполагает включение в обобща-ющую выборку только экземпляров определенного класса, а в процессе выполнения создается наиболее компактный вариант описания из всех подходящих к каждому из предъявленных экземпляров.
Обе задачи относятся к классу методик супервизорного обучения, поскольку в распоряжении программы имеется и специально под-готовленная обучающая выборка, и пространство атрибутов.
Извлечение из текста знаний предполагает выявление в нем не только лингвистических, но и логических отношений, для чего при-меняются различные методы семантического анализа текста. Под семан-тической связью подразумевается отношение понятий в предметной области. Представителями семантических связей в лексике являются предикативные слова (например, больше; меньше; иметь значение; иметь свойство; если…, то…). Однако выделения только предикативных слов в языковой конструкции недостаточно для классификации представляемых ими семантических связей. Необходимо также выявить нелексические свойства семантических связей. Для того чтобы более полно охаракте-ризовать связь между двумя объектами (процессами, событиями), следует указать не только вид связи, направленный от первого ко второму, но и вид связи, направленный от второго к первому [12].
Модель обучения на прецедентах – это модель, в основе которой лежит принцип синтеза закономерности на примерах и ее проверки на новых примерах. Обучение на основе прецедентов задействует пред-шествующий опыт для решения новых задач путем идентификации текущей проблемы, поиска подходящего прецедента и использования найденного прецедента для решения текущей проблемы. Недостатком этого подхода является то, что в процессе обучения не создается каких-либо моделей, обобщающих предыдущий опыт, а надежность вы-водимых результатов зависит от полноты описания прецедентов (си-туаций).
Глава 11. Современные методы исследования,
моделирования и проектирования сложных систем
11.1. Интеллектуальные методы проектирования
сложных систем
Традиционное проектирование содержит задачи анализа систем, связанные с накоплением и исследованием необходимой информации, и задачи синтеза конкретных вариантов систем, удовлетворяющих задан-ным требованиям. Исследования проблем проектирования получили наибольшее развитие в области техники. Проектирование технического объекта может проводиться на основе прототипа или без него. В первом случае цель проектирования заключается в совершенствовании прото-типа, которое ориентировано либо на улучшение качества выполнения уже существующих функций, либо на обеспечение новых функций. Кроме того, задача может ставиться как изобретательская, когда одной из важнейших целей является патентоспособность создаваемого устрой-ства [1].
Задача совершенствования прототипа может включать дополни-тельные условия, связанные с технологическими возможностями кон-кретного предприятия, для перехода от производства прототипа к выпуску нового образца.
При проектировании экономических систем обычно не преследуются цели новизны. Проектированию без прототипа здесь соответствует задача создания новой экономической системы (корпорации), т.е. системы, которая не существовала прежде. При этом цели, функции, структура и многие свойства создаваемой системы могут быть известны.
Задачи проектирования на основе прототипа имеют различные постановки:
проектирование не существовавшей прежде системы по образцу уже известной;
кардинальное перепроектирование имеющейся системы, которая при этом уничтожается, а вместо нее предусматривается создание новой с использованием ряда элементов прежней системы. Данная постановка возникает тогда, когда существующая система исчерпала свои ресурсы совершенствования, стала неустойчивой и неэффективной, т.е. достигла точки бифуркации;
кардинальное перепроектирование существующей системы, ориен-тированное на ее совершенствование и не допускающее ее уничтожение (реинжиниринг);
постоянное и постепенное совершенствование существующей си-стемы на основе мониторинга ее окружения и тенденций развития организационных систем (концепция постоянно развивающегося пред-приятия).