Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 399
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
А1 <проверки нормальности распределения значений остатков>
А2 <проверки статистической независимости значений остатков>
. . .
С (если К7 = 3, то)
С1 <вычисление F-статистик>
С2 <визуальный анализ значений остатков>
Множество КФ и ФСС служат основой для построения фрейм-фраз, совокупность которых образует семантическую модель предметной области.
В качестве значения слота может выступать имя другого фрейма – так образуются сети фреймов (рис. 3.2).
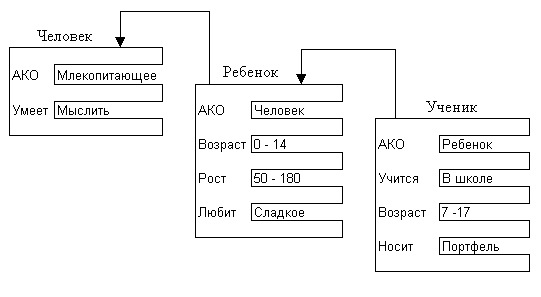
Рис. 3.2. Сеть фреймов
Существует несколько способов получения слотом значений во фрейме-экземпляре:
по умолчанию от фрейма-образца;
через наследование свойств от фрейма, указанного в системном слоте АКО (A Kind Of – «это»);
по формуле, указанной в слоте;
через присоединенную процедуру;
явно из диалога с пользователем;
из БД.
Важнейшим свойством теории фреймов является наследование свойств по АКО-связям. Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно наследуются, т.е. переносятся, значения аналогичных слотов. В общем случае на наследование свойств ориентируют указатели наследования:
U – уникальный, показывает, что значение не наследуется;
S – показывает, что значение слота наследуется;
R – показывает, что значения слота должны находиться в пределах, указанных в одноименных слотах родительского фрейма;
O – выполняет одновременно функции U и S (наследуется только при отсутствии значения).
Тип значения слота определяют указатели типа данных: frame (указатель на фрейм), real, integer, boolean, text, list, table.
Демон – это процедура, автоматически запускаемая при выполнении некоторого условия. Демоны запускаются при обращении к соот-ветствующему слоту. Демон IF-NEEDED запускается, если в момент обращения к слоту его значение не было установлено; демон IF-ADDED – при попытке изменения значения слота; демон IF-REMOVED – при удалении значения слота.
Логический вывод во фреймовой модели может осуществляться различными способами, например путем обмена сообщениями между фреймами разного уровня иерархии. Вначале получает управление корневой фрейм, затем динамически формируется необходимая для реализации запросов цепочка фреймов следующего уровня иерархии. Основной операцией при такой работе является поиск по образцу.
В рамках фреймовой модели образец – это фрейм, в котором заполнены не все структурные единицы, а только те, которые будут использованы
в качестве ключа для реализации действий в конкретных фреймах. При этом используются специальные процедуры наполнения слотов опре-деленными значениями, а также введение в систему новых фреймов – прототипов и новых связей между ними.
При решении интеллектуальных задач предметная область описывается на двух уровнях: интенсиональном (фреймы-прототипы) и экстенсиональном (фреймы-примеры). Фреймовая модель и решатель должны обеспечивать описание предметной области, возможность задания и обработки отношений и правил выбора. Каждому объекту предметной области ставится в соответствие фрейм. Получение экстенсиональных информационных характеристик из интенсиональных представляет собой выбор конкретных значений атрибутов.
Решатель содержит следующие механизмы:
логического вывода;
навигации по фреймовой сети;
реализации различных элементов интерфейса пользователя;
дополнения решателя новыми методами;
генерации фреймов-примеров из фреймов-прототипов;
установления отношений между объектами;
выбора.
Основным механизмом решателя является механизм логического вывода, остальные строятся на его основе. Логический вывод представляет собой интерпретацию решателем фрейма-прототипа с использованием данных, содержащихся во фрейме-примере. В результате формируется новый фрейм-пример, данные которого могут использоваться при интерпретации очередного фрейма-прототипа.
Сильная сторона фреймовой модели заключается в возможности включения в слоты различных предположений и ожиданий, что позволяет моделировать ситуации, в которых отсутствует упоминание о различных деталях.
С точки зрения управления логическим выводом функции механизма наследования заключаются в поиске и определении значений слотов фреймов нижележащих уровней по значениям слотов верхних уровней, а также в запуске присоединенных процедур и демонов. Присоединенные процедуры и демоны позволяют реализовать любой механизм логического вывода, однако каждая реализация носит кон-кретный анализ, зависит от базового языка реализации и трудоемка, в связи с чем стоимость разработки фреймовой ИИС на порядок выше продукционной.
Основным преимуществом фреймов как модели представления знаний является то, что она отражает концептуальную основу организации памяти человека, а также ее гибкость и наглядность. Фреймовый подход реализуется на основе специальных языков представления знаний: FRL, KRL, фреймовой «оболочки» Карра.
3.4. Семантические сети
Семантика – это наука, которая устанавливает отношения между символами и обозначаемыми объектами, т.е. определяет смысл знаков.
Семантическую сеть можно представить в виде ориентирован-
ного графа, вершины которого – понятия, а дуги – отношения между ними.
В качестве понятия выступают абстрактные или конкретные объекты, а отношения – связи типа «принадлежит», «имеет частью», «это». Можно предложить различные классификации семантических сетей, связанных с типами отношений между понятиями:
по количеству типов отношений – однородные (с единственным типом отношений) и неоднородные (с различными типами отношений);
по типам отношений – бинарные, в которых отношения связывают два объекта; n-арные, в которых есть специальные отношения, связывающие более двух понятий.
Характерной особенностью семантических сетей является обяза-тельное наличие трех типов отношений:
класс – элемент класса (цветок – роза);
свойство – значение (цвет – красный);
пример элемента класса (роза – чайная).
Наиболее часто в семантических сетях используются отношения:
атрибутивные связи – «иметь свойство» (память – объем);
часть – целое – «имеет частью» (компьютер – дисплей);
функциональные связи – «производит», «влияет»;
количественные – «больше», «меньше», «равно»;
пространственные – «далеко», «близко», «за», «под», «над»;
временные – «раньше», «позже», «в течение»;
логические связи – «и», «или», «не».
Фрагмент семантической сети приведен на рис. 3.3 [8].
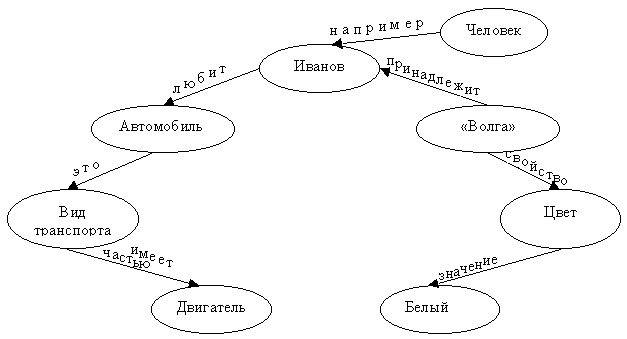
Рис. 3.3. Семантическая сеть
При построении семантической сети необходимо определить:
все вершины, связанные с заданной, конкретным отношением;
имена всех отношений для заданной вершины;
все пары вершин, связанные конкретным отношением.
Проблема поиска решения (логического вывода) в БЗ, построенной на основе семантической сети, сводится к задаче поиска фрагмента сети или выделения некоторого подпространства сети, соответствующего некоторой подсети, отражающей конкретный запрос к системе.
В общем случае семантическая сеть определяется как кортеж
N = < A, B, C, D>,
где А – множество вершин; В – множество имен вершин; С – множество дуг; D – множество имен дуг.
В семантических сетях используют различные типы структур, но требование ассоциативности, т.е. группирования информации вокруг фактов, атрибутов и объектов, является обязательным. Экстенсиональные семантические сети соответствуют БД, интенсиональные – БЗ. Их объединение образует систему представления данных и знаний в ИИС.
Частым случаем семантических сетей являются сценарии или однородные семантические сети. В однородных семантических сетях вершины, отображающие объекты, связаны между собой однонаправленными ду-гами, которые отображают отношения строгого или частичного порядка с различной семантикой. Если, например, объектами-понятиями будут виды заданий, а единственным отношением строгого порядка – от-ношение следования, то получается сетевой график выполнения ком-плекса работ.
Процедурой логического вывода в семантической сети является поиск по образцу. Он может либо представлять собой полностью определенный фрагмент знаний, либо содержать свободные переменные. Информационная потребность, определяющая содержание и цель за-проса и БЗ, описываются автономной БЗ-сетью запроса, построенной по тем же правилам и отображающей те же объекты и отношения, что представлены в системе знаний. Поиск ответа на запрос реализуется сопоставлением сети запроса с фрагментами семантической сети, представляющей БЗ. Положительный результат сопоставления по-зволяет получить один из ответов на запрос. Операция сопоставления сводится к следующему. Для семантической сети задается набор до-пустимых преобразований, переводящих исходную семантическую сеть в логически эквивалентную ей. Операция сопоставления выявляет
все фрагменты исходной и эквивалентных сетей, изоморфных сети запроса.
Семантические сети чаще всего используются для решения
задач распознавания образов, в частности для извлечения знаний
из текстов при разработке естественно-языковых интерфейсов ИИС.
При извлечении поверхностных знаний на основе интервью с экс-
пертом задача услож-няется из-за ситуационной обусловленности содержания текстов, анафорических (межфазовых) связей, явлений эл-липсиса (сокращений, пропуска некоторых элементов словосочетаний
и фраз) и др.
Семантические сети – это общее название методов описания, использующих сети. Так же называют один из способов представления знаний. На основе сетей осуществляются выводы, однако для этого необходимы специальные алгоритмы. Поскольку «семантические сети» служат обобщенным названием систем представления, использующих сети, нет смысла определять для них специфические алгоритмы выводов. Для каждого конкретного формализма определяются собственные правила вывода, поэтому усиливается элемент произвольности, вносимый
человеком. Выводы, которые не подверглись тщательной проверке
, таят в себе угрозу создания противоречий. Следовательно, в семантических сетях необходимо больше, чем в продукционных системах, уделять внима-
ния устранению противоречий. Поскольку сама система такими воз-можностями не обладает, во многих случаях эта функция возлагается на человека. Просматривая все знания, человек способен управлять их непротиворечивостью, однако если объем знаний будет увеличиваться, то их представление резко усложнится, что ограничит круг решаемых проблем.
Семантическая сеть является весьма мощным средством пред-ставления знаний. По сети можно осуществлять поиск, используя знания о смысле отношений и операции сопоставления по образцам. Логи-ческие выводы на семантических сетях определяются через отноше-
ния между множеством дуг, имеющих общие узлы. В последнее время были проведены исследования по определению выводов более об-
щего вида для фрагментов сетей, однако получить удовлетворитель-
ные результаты до сих пор не удалось из-за трудности унификации выводов.
К достоинствам семантических сетей можно отнести следую-
щее:
знания хорошо структурированы;
имеется соответствие современным представлениям об организации долговременной памяти человека;
структура модели понятна человеку.
Недостатки семантической сети:
при большом ее объеме все операции выполняются очень долго;
сложная сеть труднообозрима;
сложно организовать процедуру логического вывода;
при решении многих конкретных задач представления знаний только в виде семантической сети данная модель оказывается неудобной и не-эффективной.
В общем случае семантические сети позволяют расширить воз-можности продукционных моделей. Для реализации семантических сетей существуют специальные сетевые языки, например NET, SIMER + MIR. Широко известны ЭС, использующие семантические сети в качестве языка представления знаний, – PROSPECTOR, CASNET, TORUS.
Глава 4. Структура и этапы проектирования
интеллектуальных информационных систем
4.1. Классификация интеллектуальных информационных систем
Интеллектуальные информационные системы предназначены для решения задач, требующих высочайшей квалификации. Характерной особенностью ИИС является наличие БЗ – совокупности знаний, записанной на магнитный носитель в форме, понятной эксперту и поль-зователю. Эксперт – квалифицированный специалист, готовый к передаче своей компетентности и опыта БЗ. Пользователь – специалист предметной области, для которого предназначена ИИС. Под