ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 1145
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Sound Forge
Разработчик – Sonic Foundry
Многооконный редактор с поддержкой OLE, видеороликов в формате AVI и дополнительного монитора для их отображения в процессе работы.
При работе с файлами в 16–разрядном формате PCM (WAV) есть возможность открыть файл в режиме непосредственного доступа (Direct mode), без промежуточного копирования. Это заметно ускоряет работу, однако лишает возможности сохранить прежнюю версию файла при аварийном завершении.
Максимально достижимое увеличение – одна точка экрана на один отсчет оцифровки, чего в ряде случаев явно недостаточно для хорошего рассмотрения формы волны.
Автоматическое выравнивание при выделении – по точкам пересечения нуля и временным меткам.
При монтаже удобно пользоваться функциями Preview Cur/Cursor (прослушивание, каким будет результат вырезки, до выполнения самой вырезки) и Pre–roll to Cursor (прослушивание небольшого участка перед курсором).
Поддерживается список помеченных участков (regions) и выборочного проигрывания.
В режиме записи возможно создание «пульта дистанционного управления» – Remote Control. При этом основное окно редактора заменяется на небольшое окно «пульта», находящееся поверх других окон. Эта функция удобна при записи сигнала, формируемого другой программой, либо устройством, управление которым производится из другой программы.
В режиме записи возможен также прямой сброс данных на диск, минуя системный кэш с обратной записью. Это позволяет избавиться от долгих пауз, когда Windows сбрасывает кэш на диск, останавливая при этом все программы, однако работа диска в таком режиме становится весьма напряженной за счет непрерывного позиционирования. Надо сказать, что и при работе через кэш Sound Forge использует диск гораздо более агрессивно, чем большинство других редакторов.
Редактор может работать с внешними семплерами (Akai, E–mu, Kurzweil, Peavey), поддерживающими стандарты MIDI SDS и/или SCSI SMDI. Поддерживается также подготовка семплов для ACID – другой программы Sonic Foundry, предназначенной для создания музыки из готовых фрагментов.
Генератор сигналов выдает простые периодические сигналы и серии DTMF, а также имеет функцию FM Synthesis – частотно–модуляционный операторный синтез, популярный в электронных синтазаторах начала 80–х.
Поддерживаются собственные подключаемые модули. При помощи модуля Batch Converter можно создать последовательность операций обработки, которая затем может быть автоматически применена к одному или нескольким файлам. CD Architect предназначен для формирования и записи звуковых компакт–дисков. Spectrum Analysis служит для спектрального анализа фонограммы, Noise Reduction – для ослабления помех и шумов, Q–Sound – для придания звуку эффекта объемности.
Синхронизация по MIDI возможна в обоих режимах – ведущем и ведомом.
Имеется любительская локализация SF 4.5 на русском языке (переведены тексты меню и сообщений). Качество перевода среднее.
WaveLab
Разработчик – Steinberg
Один из наиболее мощных и удобных современных редакторов. Поддерживает форматы до 24 разрядов и 96 кГц.
Предоставляет все необходимые монтажные операции, нормализацию, преобразования динамики, коррекцию высоты/времени звучания. Операции сложной обработки немногочисленны: трехполосный эквалайзер, гармонайзер на 16 голосов (создает дополнительные гармоники основного голоса), качественный Chorus.
Основное внимание при обработке уделено поддержке модулей реального времени – собственных, DirectX и VST (от Cubase VST). Для управления модулями сделана специальная панель эффектов (Master Section), в которой можно выбрать до шести модулей одновременно. Для модулей WaveLab/VST изображаются панели управления, стилизованные под вид аппаратных стоечных блоков. Панели модулей, а также панели инструментов WaveLab (toolbars) могут находиться в любом месте экрана, а не только в окне редактора.
Имеет функции сравнения двух файлов, генерации тестового сигнала с огибающей, построения трехмерной спектрограммы с показом ее с различных точек зрения.
Функция Batch Processor позволяет сформировать алгоритм пакетной обработки набора файлов.
Поддерживает обмен данными с аппаратными семплерами AKAI, Ensoniq, E–mu, Kurzweil, Roland в стандартах SDS/SMDI. Может считывать звуковые дорожки с компакт–дисков. Содержит встроенный CD–рекордер с возможностью задания длительности пауз между дорожками.
Технология распознавания лиц
Надежность работы системы, высокие процент распознавания, точность и скорость идентификации обеспечиваются использованием специально разработанными алгоритмами. Преимущества технологии ISS позволяют успешно использовать систему "Face–Инспектор" на различных объектах: железнодорожных и автовокзалах, в аэропортах, на станциях метрополитена, в местах проведения массовых мероприятий, промышленных и стратегически важных объектах для решения широкого спектра задач обеспечения безопасности, контроля и ограничения доступа, регистрации и идентификации людей.
I этап. Поиск лица в видеопотоке
Поиск лиц в видеопотоке для их дальнейшего распознавания производится путем выделения симметрий в каждом видеокадре. Для этого применяется определенный набор симметричных сверток в заданном диапазоне масштабов изображения, после чего видеоизображение обрабатывается нейросетью.
Этот алгоритм обеспечивает такие преимущества данной технологии как устойчивость к шуму и неравномерной засветке лица.
II этап. Трекинг (отслеживание) лица между кадрами видеопотока
Лицо человека, единожды попав в поле зрения видеокамеры, с использованием алгоритма предсказания вектора движения и корреляционных алгоритмов будет автоматически отслеживаться от кадра к кадру. Все изображения будут сохраняться во временном буфере. В результате будет выбран кадр с оптимальным ракурсом лица и качеством изображения.
III этап. Выделение основных признаков лица
На этом этапе с использованием алгоритма анализа контуров производится выделение на видеоизображении лица его основных признаков: глаз, носа, рта и т.д.
Преимуществом этого метода является надежная работа при нефронтальном позиционировании лица.
IV этап. Нормализация изображения лица
После выделения основных признаков лица, его изображение приводится к стандартному виду: для надежного распознавания изображение лица должно иметь определенные размеры, необходимо выдержать расстояние между глазами, положение лица относительно центра. Для этого изображение масштабируется, разворачивается, в некоторых случаях также определяется положение лица (фас, положение в три четверти или точные 3D координаты), автоматически нормализуется яркость и контрастность.
V этап. Преобразование индивидуальных признаков лица
Непосредственное сравнение полученного изображения лица с изображениями из базы данных – ресурсоемко и неэффективно. Решение этой проблемы преобразование его характерных признаков в форму, максимально подходящую для быстрого сравнения – в вектор малой размерности.
VI этап. Сравнение полученного векторного представления с базой данных
Полученное векторное представление сравнивается с изображениями из базы данных, хранящимися в таком же формате. В итоге сравнения "один к многим" выбираются наиболее близкие по характеристикам вектора: результатом заключительного этапа является идентификация лица, попавшего в поле зрения видеокамеры с изображениями из базы данных.
Раздел 5. Автоматизированные информационные системы в профессиональной деятельности
Тема 14. Информационные системы как центры сбора, хранения и обработки служебной информации в профессиональной деятельности
ОСНОВНЫЕ ВОПРОСЫ:
1. История возникновения информационных систем (ИС).
2. Понятие автоматизированной информационной системы.
3. Этапы развития информационных систем.
4. Принципы проектирования АИС.
5. Этапы проектирования информационных систем.
6. Структура информационных систем.
7. Обеспечение АИС.
8. Классификации информационных систем.
1. История возникновения информационных систем
Сегодня человечество переживает информационный взрыв во всех областях своей жизнедеятельности. Количество и качество информации, обрабатываемой человеком, непрерывно растет. Поэтому для каждого человека, живущего в информационном обществе, очень важно овладение средствами оптимального решения задачи накопления, упорядочения и рационального использования информации. И это становится особенно актуальным в профессиональной деятельности каждого человека.
С использованием компьютеров возможности человека в обработке информации резко возросли. В применении компьютерных технологий для решения задач информационного обслуживания можно выделить два периода (рис.1):
I. Начальный период, когда решением задач обработки информации, организацией данных занимался небольшой круг людей - системные программисты. Этот период характерен тем, что создавались программные средства для решения конкретной задачи обработки данных. При этом для решения другой задачи, в которой использовались эти же данные, нужно было создавать новые программы.
II. Период системного применения ЭВМ. Для решения на ЭВМ комплекса задач создаются программные средства, оперирующие одними и теми же данными, использующие единую информационную модель объекта. Эти средства не зависят от характера объекта, его модели, их можно применять для информационного обслуживания различных задач.
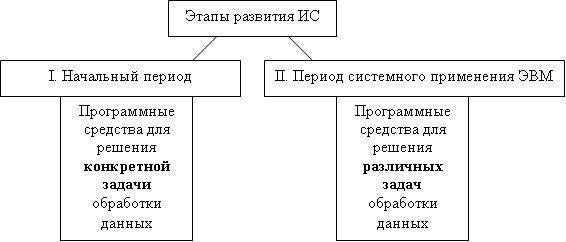
Рис.1 Этапы развития информационных систем
Человечество пришло к организации информации в информационных системах.