ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 1160
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Специальным языком, посредством которого формируется ПОЗ, принято называть информационно-поисковым языком (ИПЯ) и определять его как некую формализованную семантическую систему, предназначенную для выражения содержания документа и поискового запроса.
Основными элементами ИПЯ являются алфавит, лексика (словарный состав) и грамматика.
Алфавит ИПЯ – система знаков, используемых для записи слов и выражений ИПЯ.
Словарный состав (лексика) ИПЯ – совокупность слов, словосочетаний и выражений, используемых для построения текстов ИПЯ.
Грамматика ИПЯ – совокупность средств и способов построения, изменения и сочетания лексических единиц. Грамматика включает морфологию и синтаксис.
Так как ИПЯ может быть определен различными способами, выделим ряд требований, которым он должен удовлетворять:
-
располагать лексико-грамматическими средствами для точного отображения темы документа и запроса; -
не содержать полисемии (когда одно и то же слово выражает пучок родственных понятий); -
не содержать синонимии (совпадение слов по значению и несовпадение по написанию); -
не содержать омонимии (совпадение слов по написанию или звучанию и несовпадение по смыслу); -
отображать только объективные характеристики предметов и отношений между ними; -
быть удобным для алгоритмического сопоставления ПОД и ПОЗ.
Естественный язык обладает высокой многозначностью. В ИПЯ недопустима многозначность. Поэтому необходимо учитывать отношения синонимии и омонимии слов естественного языка, используемых в ИПЯ.
Построение выражений ИПЯ требует решения ряда проблем.
Первая проблема связана с выбором лексических единиц ИПЯ, необходимых для построения выражений. Выбор слов определяется их смыслом, обусловленным парадигматическими отношениями между предметами и явлениями, которые они определяют.
Парадигматические отношения – это отношения, обусловленные наличием логических связей между предметами и явлениями, обозначенными данными словами.
Рассмотрим самые очевидные парадигматические отношения:
-
«вид – род», например, «огурец – овощ». В данном случае понятие «огурец» является видовым по отношению к понятию «овощ». Родовое понятие всегда включает в себя видовое; -
«часть – целое», например «нога – человек»; -
«причина – следствие», например, «лампа – свет»; -
«функциональное сходство», например, «лопата – экскаватор».
Вторая проблема построения фраз ИПЯ связана с определением последовательности выбранных слов.
Синтагматические отношения – отношения слов при соединении их в словосочетания и фразы. Для уточнения смысла документа или запроса, помимо ключевых слов, часто необходимо указывать, в каких синтагматических отношениях эти слова находятся.
Многообразие используемых в ИПЯ парадигматических и синтагматических отношений определяет семантическую силу ИПЯ.
По способу организации понятий различают следующие ИПЯ: предкоординируемые (классификационные) ИПЯ; посткоординируемые (дескрипторные) ИПЯ.
Предкоординация предполагает предварительное (до использования при индексировании) построение сложных классов путем логического умножения (координации) простых классов. Словарный состав задается в виде фиксированного списка слов, словосочетаний и фраз. Введение в язык новых лексических единиц строго ограничено и возможно лишь до индексирования документов, т. е. при создании языка.
Посткоординируемые (дескрипторные) языки основаны на методе координатного индексирования. В посткоординируемых ИПЯ лексические единицы объединяются в поисковом образе лишь во время индексирования документа. Словарь дескрипторного ИПЯ состоит отдельных слов или словосочетаний естественного языка, отобранных специальным образом, так называемых – ключевых слов и дескрипторов.
Координатное индексирование — индексирование, при котором основное смысловое содержание текста (документа) или информационного запроса представляется в виде сочетания ключевых слов или дескрипторов.
Ключевые слова — это наиболее существенные для отображения содержания документа слова и словосочетания, обладающие назывной функцией.
Одним из важнейших показателей эффективности функционирования ИС, характерным для документальных информационных систем является полнота и точность информационного поиска. Рассмотрим подробней указанные понятия.
Полнота информационного поиска
Обозначим полноту информационного поиска
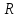 , тогда определяется отношением числа найденных релевантных документов к общему числу релевантных документов, имеющихся в системе, т.е.
, тогда определяется отношением числа найденных релевантных документов к общему числу релевантных документов, имеющихся в системе, т.е. 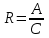 , где
, где 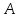
– число найденных релевантных документов,
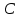 – общее число релевантных документов в системе.
– общее число релевантных документов в системе.Точность информационного поиска
Обозначим точность информационного поиска
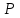 , тогда определяется отношением числа найденных релевантных документов к общему числу документов, выданных на запрос пользователя, т.е.
, тогда определяется отношением числа найденных релевантных документов к общему числу документов, выданных на запрос пользователя, т.е. 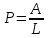 , где
, где 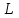 – общее число документов, выданных на запрос пользователя.
– общее число документов, выданных на запрос пользователя.Информационный шум
Наличие среди отобранных на запрос пользователя нерелевантных документов называется информационным шумом системы. Коэффициент информационного шума
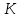 определяется отношением нерелевантных документов, выданных в ответе пользователю, к общему числу документов, выданных на запрос пользователя:
определяется отношением нерелевантных документов, выданных в ответе пользователю, к общему числу документов, выданных на запрос пользователя: 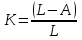
3. Использование документальных информационных систем (ДИС) в профессиональной деятельности сотрудника ОВД
Рассмотрим возможности применения ДИС в профессиональной деятельности сотрудников ОВД.
Для этого подробно остановимся на правовых информационных системах, которые являются типичным примером документальных информационных систем Поисковые интернет системы также являются представителями документальных систем.
Разобьем их условно на АИС, используемые в правотворчестве, правоприменительной практике, правоохранительной деятельности, правовом образовании и воспитании. Естественно, следует понимать, что подобного рода классификация достаточно условна, так как одни и те же АИС могут использоваться в различных видах правовой деятельности.
Можно также рассмотреть правовые информационные системы с точки зрения правового образования, в рамках которого они сложились, и задачи которого решают в процессе своего функционирования, — автоматизированные системы органов прокуратуры, юстиции, судов и др.
Один из основных подходов к классификации АИС в правовой сфере связан с видами обрабатываемой социально-правовой информации.
Так можно выделить АИС, основанные на системе нормативных правовых актов. Например, информационно-поисковые по законодательству и справочные правовые системы. Для этих систем проблемы систематизации информации связаны с вопросами классификации и систематизации нормативных правовых актов.
С другой стороны, можно выделить системы, аккумулирующие и обрабатывающие разнообразную социально-правовую информацию ненормативного характера: криминологическую, криминалистическую, судебно-экспертную, оперативно-розыскную, научную правовую и др.
В ДИС собираются и систематизируются тексты документов или их библиографическое описание. Поскольку документированная информация — это зафиксированная на материальном носителе путем документирования информация с реквизитами, позволяющими определить такую информацию, или в установленных законодательством Российской Федерации случаях ее материальный носитель, то указанные реквизиты являются основанием для классификации обрабатываемой информации.
Всю документированную правовую информацию можно разбить на официальную и неофициальную. К официальной правовой информации относятся сведения и данные о праве или о законодательстве в широком смысле слова, т.е. обо всех действующих и уже прекративших действие нормативных актах. В автоматизированных системах, основанных на официальной правовой информации, большую роль играет ее классификация по источникам права: законы Российской Федерации, нормативные акты правительства страны и правительств республик, министерств и ведомств страны и республик и местных органов государственной власти и государственного управления, общественных организаций и др.
В качестве неофициальной правовой информации, лежащей в основе функционирования АИС, рассматриваются все сведения и данные о праве и связанных с ним явлениях, которые отражены в юридической научной литературе, не являющейся официальной (юридических монографиях, учебниках, статьях, обзорах, докладах, справочниках и других материалах), и сведения, содержащиеся в материалах, полученных от предприятий, учреждений, общественных организаций, граждан и других источников.
Большое значение, с точки зрения создания и функционирования АИС, имеет классификация информации по степени доступа на общедоступную и ограниченного доступа. Использование подобного рода информации в автоматизированных системах требует организации технической и программной защиты ее от несанкционированного доступа.
Наиболее известными системами, относящимися к данному виду, являются: информационная система «Эталонный банк правовых актов», созданная в НТЦ «Система» при Государственном правовом управлении Президента РФ; база данных по законодательству «Эталон», разработанная Научным центром правовой информации; справочная правовая система «Гарант», разработанная научно-производственным объединением «Гарант-Сервис» (МГУ); информационная правовая система «Кодекс», созданная в «Центре компьютерных разработок» (Санкт-Петербург); справочно-правовые системы семейства «КонсультантПлюс», созданные ЗАО «КонсультантПлюс».
ДИС используются для накопления и постоянного корректирования больших массивов информации о лицах, фактах и предметах, представляющих интерес. Эти системы работают преимущественно по принципу «запрос — ответ», поэтому обработка информации в них связана в основном не с преобразованием первичных данных, а с их поиском.
Принципиальную особенность ДИС составляет понятие «информационный поиск». Информационный поиск — это процесс отыскания в каком-то множестве тех сведений, которые посвящены указанной в информационном запросе теме (предмету), информация о которой необходима пользователю.
Большое количество автоматизированных информационно-справочных систем создано и функционирует в правоохранительной и судебной сферах: «Убийство», «Следователь», «Рэкет», «Разбой», «Хищение оружия из хранилищ», «Расследование» — по организации расследования отдельных видов преступлений; «Сейф» — по информационному обеспечению расследования хищений из сейфов; «Девиз-М» — по расследованию поддельных денежных знаков; «Рецепт» — по расследованию поддельных рецептов на получение наркотических средств; «Досье» — по автоматизированному учету особо опасных преступников (рецидивистов, гастролеров, организаторов преступных групп, авторитетов уголовной среды и т.п.); «Папилон» — по проверке отпечатков пальцев и дактилокарт; «Криминал-И» — по учету правонарушений и преступлений, совершенных иностранными гражданами и гражданами России за рубежом; «Автопоиск» — по учету и организации поиска угнанного и бесхозного автотранспорта; «Антиквариат» — по учету похищенных культурных ценностей; «Наказание» — об отбывающих наказание;