ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 1157
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Дадим каждому из перечисленных видов АИС краткое описание.
Автоматизированные информационно-справочной системой (АИСС) в области права – это автоматизированные информационные системы, предназначенные для сбора, систематизации, хранения и поиска правовой информации по запросам пользователей.
АИСС используются для накопления и постоянного корректирования больших массивов информации о лицах, фактах и предметах, представляющих интерес. Эти системы работают преимущественно по принципу «запрос – ответ», поэтому обработка информации в них связана в основном не с преобразованием первичных данных, а с их поиском.
Автоматизированные базы данных в значительной степени упрощают работу специалистов в области криминалистики. Современная практика эксперта-криминалиста основывается на достаточно широком ряде баз данных и автоматизированных информационных систем криминалистического профиля, позволяющих решать следующие задачи:
-
анализ взрывчатых веществ (АИС «Взрывчатые вещества»); -
анализ текстильных волокон (АИС «Волокно»); -
анализ рентгенограмм (АИС «Фазан»); -
анализ автоэмалей (АИС «Марка»); -
анализ красителей шариковых ручек (АИС «Спектр»); -
анализ стекол автомобильных фар (АИС «Стекло»); -
анализ бумаги (АИС «Бумага»); -
создание библиотек инфракрасных спектров (АИС «БИРСИ», Германия); -
анализ металлов и сплавов (или их следов).
Практическая ценность применения подобных автоматизированных информационных систем в деятельности органов внутренних дел не вызывает сомнений. Так, например, АИС по взрывчатым веществам гражданского и военного применения, а также боеприпасам предоставляет возможность определять состав, марку взрывчатых веществ на основе экспериментальных данных; банки данных «Модель оружия-гильзы» являются поисковой базой для установления типа оружия по пуле или гильзе.
В законотворческой деятельности использование автоматизированных информационно-поисковых систем также имеет большое значение. Эти системы играют роль незаменимого помощника для учета предшествующего законодательства на этапе разработки новых нормативных актов. Необходимость увязки всех вновь создаваемых нормативных актов с уже действующими, недопущение повторений одних и тех же норм в различных правовых актах, признание определенных нормативных актов утратившими силу – работа очень трудоемкая. Ручной отбор необходимых правовых документов может не только занять достаточно длительное время, но и привести к тому, что многие нормативные акты останутся вне поля зрения специалистов.
Машинный поиск существенно повышает оперативность подготовки новых нормативных актов и перечней нормативных актов, утративших силу.
Наибольшее применение автоматизированные информационно-поисковые системы находят в правоприменительной деятельности, которая связана с необходимостью работы с правовой информацией.
Получение необходимых нормативных правовых документов из средств массовой информации требует больших временных затрат. Эта задача становится еще более сложной, если речь идет о различных ведомственных нормативных актах, которые далеко не всегда издаются в периодической печати. С использованием информационно-поисковых систем задача быстрого подбора необходимых документов существенно упрощается по сравнению с поиском в средствах массовой информации. Кроме того, информационно-поисковые системы являются весьма полезным инструментом для людей, не имеющих специального юридического образования и не знающих, какие конкретно нормативные правовые акты регулируют тот или иной вопрос. Такие проблемы нередко возникают и перед юристами, не являющимися специалистами в рассматриваемой правовой области. Этих трудностей можно избежать, воспользовавшись различными поисковыми возможностями, предоставляемыми современными автоматизированными системами правовой информации. Системы классификации (хронологические, тематические, по реквизитам документов и т.п.) таких компьютерных баз позволяют на хорошем уровне решать многие задачи.
Автоматизированными информационно-логическими системами (АИЛС) правовой информации называются автоматизированные информационные системы, призванные на базе хранящегося в них, специально систематизированного массива правовой информации с помощью специальных логических процедур решать задачи анализа правовой информации.
Этот класс информационных систем предназначен для решения на основе систематизированной правовой информации различного вида простейших логических задач. В результате работы систем этого класса происходит не только поиск необходимой при решении задач правовой информации (как в информационно-поисковых), но и с помощью определенных логических процедур синтез новых сведений, не содержащихся явно в отобранной правовой информации.
Сравнительно новым и перспективным направлением использования компьютерных технологий являются экспертные системы (ЭС), относящиеся к системам искусственного интеллекта.
Эти системы способны накапливать, обрабатывать знания из некоторой предметной области, на их основе выводить новые знания и решать на основе этих знаний практические задачи, объясняя ход решения. С помощью экспертных систем решаются задачи неформализованные, слабо структурируемые, алгоритмы решения которых не существуют в силу неполноты, неопределенности, неточности, расплывчатости рассматриваемых ситуаций и знаний о них.
Автоматизированные рабочие места (АРМ) — индивидуальный комплекс технических и программных средств, предназначенный для автоматизации профессионального труда специалиста. В состав АРМ входят, как правило, персональный компьютер, принтер, графопостроитель, сканер и другие устройства, а также прикладные программы, призванные решать конкретные задачи из профессиональной деятельности.
Автоматизированные системы управления (АСУ) — комплекс программных и технических средств, предназначенных для автоматизации управления различными объектами.
Основная функция АСУ — обеспечение руководства информацией. Автоматизированная система управления обеспечивает автоматизированный сбор и передачу информации об управляемом объекте, переработку информации и выдачу управляемых воздействий на объект управления.
Примером современной АСУ ОВД является АСУ «Дежурная часть» (АСУ ДЧ), которая предназначена для автоматизации управления силами и средствами подразделений и служб ОВД в процессе оперативного peaгирования на преступления и правонарушения. АСУ выполняет следующие основные функции: автоматизированный сбор и анализ информации об оперативной обстановке в городе, выдача решений и целеуказаний подразделениям ОВД, экипажам патрульных автомобилей, контроль за их исполнением в реальном масштабе времени; автоматизированный сбор, обработка, хранение, документирование и отображение на средствах индивидуального и коллективного пользования в ДЧ и подразделениях ОВД информации о расстановке сил и средств, о положении и числе патрульных автомобилей, фактах преступлений и правонарушений на фоне электронных карт; автоматизированный сбор по каналам связи из подразделений и служб ОВД информации о лицах, совершивших правонарушения, о похищенных вещах, угнанных транспортных средствах, другой оперативно-розыскной и справочной информации, а также выдача информации по запросам подразделений ОВД из региональных и общегородских банков данных; автоматическая регистрация деятельности подразделений ОВД, подготовка аналитических и статистических отчетов, ретроспективный анализ процессов и событий.
Автоматизированная система информационного обеспечения (АСИО) — это автоматизированная информационная система, обеспечивающая максимально полное удовлетворение информационно-правовых потребностей различных правовых образований на основе эффективной организации и использования информационных ресурсов.
Еще одним классификационным признаком АИС может выступать характер информации, которой оперирует ИС. В этом случае принято выделять следующие виды ИС: фактографические, документальные и интеллектуальные (экспертные системы), на каждом из которых подробней остановимся позднее.
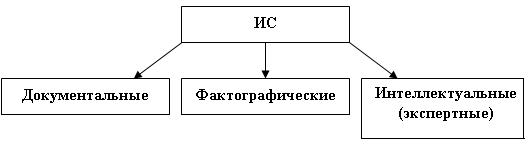
Рис. 1. Виды ИС
2. Характерные особенности
документальных информационных систем (ДИС)
Одной из особенностей документальных информационных систем является, то, что они не предполагают выдачу однозначного ответа на поставленный вопрос. Базу данных таких систем образует совокупность неструктурированных текстовых документов (статьи, книги, рефераты, тексты законов) и графических объектов, снабженная тем или иным формализованным аппаратом поиска.
Цель системы, как правило, - выдать в ответ на запрос пользователя список документов или объектов, в какой-то мере удовлетворяющих сформулированным в запросе условиям. Например: выдать список всех статей, в которых встречается слово «закон». Принципиальной особенностью документальной системы является ее способность, с одной стороны, выдавать ненужные пользователю документы (например, где некоторое слово употреблено в ином смысле, чем предполагалось), а с другой - не выдавать нужные (например, если автор употребил какой-то синоним или ошибся в написании). Документальная система должна уметь по контексту определять смысл того или иного термина, например, различать «ромашка» (растение), «ромашка» (тип печатающей головки принтера).
Поэтому, в широком смысле под документальной информационной системой мы будем понимать – некое объемное хранилище документов с возможностью поиска (еще одно их название — информационно-поисковые системы (ИПС)) и выдачи, необходимых пользователю.
Под документом понимают хранящийся в информационной базе, объект произвольной структуры, содержащий информацию произвольного характера, доступ, к которому можно получить по его реквизитам.
Реквизитами документа являются свойства этого документа, позволяющие однозначно его идентифицировать. Примерами реквизитов могут служить название документа, его номер, дата создания, имена создателей, электронная подпись и т.д. В качестве примеров документов можно привести статьи, тексты приказов и распоряжений, бухгалтерские документы, карты местности, звуковые записи и т.д. Важно еще раз подчеркнуть, что структура объекта, который мы назвали документом, может носить самый произвольный характер: форматы для текстовых документов (обычный текстовый формат, формат Word, формат PDF, формат DjVu, формат HTML и т.д.), таблицы, графические файлы и т.п.
В зависимости от особенностей реализации хранилища документов и механизмов поиска, ДИС можно разделить на две группы: системы на основе индексирования; семантически-навигационные или гипертекстовые системы.
В гипертекстовых системах документы, которые помещаются в хранилище документов, оснащаются специальными навигационными конструкциями (гиперссылками), соответствующими смысловым связям между различными документами или отдельными фрагментами одного документа.
В системах на основе индексирования исходные документы помещаются в базу без какого-либо дополнительного преобразования, но при этом смысловое содержание каждого документа отображается в некоторое поисковое пространство. Процесс отображения документа в поисковое пространство называется индексированием и заключается в присвоении каждому документу некоторого индекса — координаты в поисковом пространстве. Формализованное представление индекса документа называется поисковым образом документа (ПОД). Пользователь выражает свои информационные потребности, посредством специального языка, формируя поисковый образ запроса (ПОЗ) к базе документов.
На основе определенных критериев ДИС осуществляет поиск и выдачу документов, поисковые образы которых соответствуют поисковым образам запроса пользователя.
Остановимся подробней на качественном и количественном показателе соответствия найденных в системе документов, информационным потребностям пользователя.
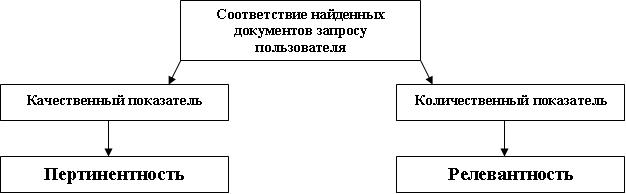
Рис. 2. Показатели соответствия найденных в системе документов,
информационным потребностям пользователя
Таким образом, под релевантностью (адекватностью) обычно понимают степень практической применимости результата или социальной применимость некоторого варианта решения задачи. В контексте указанной тематики, понятие релевантности можно уточнить следующим образом: – это соответствие найденного документа заданному информационному запросу, определяемое либо неким неформальным путем (содержательная релевантность) либо по определенному алгоритму (формальная релевантность). В терминах ДИС – это соответствие, определяемое путем сравнения поискового образа запроса (ПОЗ) с поисковым образом документа (ПОД) по определенному алгоритму [2].
Под пертинентностью в общем смысле понимают соотношение объема полезной информации к общему объему полученной информации, в терминах ИС – это соответствие найденных информационно-поисковой системой документов информационным потребностям пользователя, независимо от того, как точно и полно они выражены в тексте информационного запроса.