Файл: Интеллектуальные информационные системы и технологии.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 411
Скачиваний: 11
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Группа текстологических методов объединяет методы извлечения знаний, основанные на изучении текстов. Задачу извлечения знаний из текстов можно сформулировать как понимание смысла текста. Сам текст на естественном языке является лишь проводником смысла, а замысел и знания автора лежат во вторичной структуре (смысловой структуре, или макроструктуре текста), настраиваемой над естественным текстом. При этом можно выделить две смысловые структуры (рис. 2.3):
М1 – смысл, который пытался заложить автор в текст, его модель
мира;
М2 – смысл, который постигает читатель, в данном случае когнитолог, в процессе интерпретации I (понимания) текста;
Т – результат вербализации V смысла М1.
Сложность процесса извлечения знаний из текста заключается в принципиальной невозможности совпадения знаний, образующих М1 и М2. Таким образом, два когнитолога извлекут из одного текста Т две различные модели.
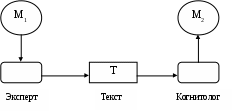
Рис. 2.3. Схема извлечения знаний из специальных текстов
Сложность интерпретации научных и специальных текстов за-ключается еще и в том, что любой текст приобретает смысл только в контексте, т.е. в окружении, в которое «погружен» текст.
2.4. Методы извлечения глубинных знаний
Большинство методов извлечения знаний не затрагивают их глубинную структуру, а отражают лишь поверхностную составляющую знаний эксперта. Для извлечения глубинных пластов экспертного знания используют методы психосемантики – науки, возникшей на стыке когнитивной психологии, психолингвистики, психологии восприятия и исследований индивидуального сознания. Психосемантика исследует структуры сознания через моделирование индивидуальной системы знаний и выявление латентных структур сознания [5, 24].
-
Основным методом экспериментальной психосемантики является реконструкция субъективных семантических пространств. В отличие от лингвистических методов, которые направлены на анализ текстов, отчужденных от субъекта, его мотивов и замыслов, психолингвистические методы обращены непосредственно к испытуемому. Большинство из них связано с различными формами субъективного шкалирования. Перед испытуемым ставится задача оценить «сходство знаний» с помощью некоторой градуированной шкалы (0÷9). В результате исследователь получает численно представленные стандартизованные данные, поддаю-щиеся статистической обработке.
В основе построения семантических пространств, как правило, лежит статистическая процедура (факторный анализ, многомерное шкалиро-вание, кластерный анализ), позволяющая группировать ряд отдельных признаков описания в более емкие категории-факторы – построение концептов более высокого уровня абстракции. При геометрической интерпретации семантического пространства значение отдельного при-знака отображается как точка или вектор с заданными координатами внутри n-мерного пространства, координатами которого выступают выделенные факторы.
На основе получаемых методами психосемантики моделей можно проводить контроль знаний. Контроль структуры знаний проводится на основе сопоставления семантических пространств опытных специалистов и новичков. Степень согласованности семантических пространств будет показателем уровня знаний новичка.
Построение семантического пространства обычно включает три этапа:
-
Выбор и применение соответствующего метода оценки семантического сходства. -
Построение структуры семантического пространства на основе математического анализа полученной матрицы сходства. -
Идентификация, интерпретация выделенных факторных структур.
Поиск смысловых эквивалентов для выделенных структур.
-
Многомерное шкалирование – это математический инструментарий, предназначенный для обработки данных о попарных сходствах, связях или отношениях между анализируемыми объектами с целью представления этих объектов в виде точек некоторого координатного пространства. При помощи многомерного шкалирования решаются задачи трех типов:
поиск и интерпретация латентных (скрытых) переменных, объясняющих заданную структуру попарных расстояний (связей);
верификация геометрической конфигурации системы анализируемых объектов в координатном пространстве латентных переменных;
сжатие исходного массива данных с минимальными потерями в их информативности.
В основе данного подхода лежит интерактивная процедура субъективного шкалирования. Эксперту предлагается оценить сходство между различными элементами с помощью некоторой градуированной шкалы (0÷9, –2÷+2). Мера близости между двумя объектами (i, j) – dij. Если dij такова, что большие значения соответствуют наиболее по-
хожим объектам, то
dij – мера сходства, в противном случае dij – мера различия.
Большинство методов извлечения знаний ориентировано на верхние вербальные уровни знания. Необходим косвенный метод, ориенти-рованный на выявление скрытых предпочтений практического опыта или операциональных составляющих опыта. Таким методом может служить метафорический подход. Метафора (от гр. «перенесение») – образное выражение, употребление слова в переносном смысле на основе сходства, сравнения. В настоящее время доказано:
метафора работает как фильтр, выделяющий посредством под-
бора адекватного объекта сравнения определенные свойства основного объекта;
метафора имеет целью не сообщить что-либо о данном объекте, т.е. ответить на вопрос «что это?», а призвать к определенному отношению
к нему, указать на некоторую парадигму (от гр. «пример, образец» – совокупность общепризнанных предпосылок, определяющих конкретное научное исследование), сигнализирующую о том, как следует вести себя по отношению к данному объекту;
объект сравнения выступает в метафоре не по своему прямому назначению («лев» не просто как представитель фауны, а как воплощение силы, ловкости, могущества.
Введение метафор – это некая игра, которая раскрепощает сознание эксперта и, как все игровые методики извлечения знаний, является хорошим катализатором трудоемких серий интервью с экспертом. Пример метафорической классификации языков программирования – мир животных (мир транспорта). При интерпретации удалось выявить такие латентные понятия и структуры, как «степень изощренности языка», «сила», «универсальность», «скорость». Полученные результаты в виде координатных пространств позволили выявить скрытые предпочтения экспертов и существенные характеристики объектов, выступающих в виде стимулов – «сила» языка С («слон»), скорость С++ («яхта»), «старо-модность» Фортрана («телега»).
Когнитивная психология – наука, изучающая то, как человек познает и воспринимает мир, других людей и самого себя, как формируется целостная система представлений и отношений конкретного человека. Среди методов когнитивной психологии особое место занимает метод репертуарных решеток. Репертуарная решетка представляет собой матрицу, которую заполняет либо сам испытуемый, либо экспери-ментатор в процессе обследования или беседы. Столбцу матрицы со-ответствует определенная группа объектов (элементов). В качестве элементов могут выступать люди, предметы, понятия, звуки, цвета – все, что интересует психодиагноста. Строки матрицы
конструкты. Конструкт – признак или свойство, по которому два или несколько объектов сходны между собой и, следовательно, отличны от третьего объекта или нескольких других объектов. Например, из трех элементов «диван», «кресло», «табурет» два элемента «диван», «кресло» выявляют конструкт «мягкость мебели». В процессе заполнения репертуарной решетки испытуемый должен оценить каждый элемент по каждому конструкту. Конструкты – не изолированные образования, они носят целостный характер. Элементы выбираются по определенным правилам так, чтобы они соответствовали какой-либо области и все вместе были связаны контекстуально, аналогично репертуару ролей в пьесе. Изменяя репертуар элементов, можно «настраивать» методики на выявление конструктов разных уровней общности, относящихся к разным системам. Репертуарная решетка не всегда является матрицей в строгом смысле, так как элементы – не обязательно числа, строки могут быть разной длины, матрица – непрямоугольного формата. Репертуарная решетка – это специфическая разновидность структурированного интервью. Анализ репертуарных решеток позволяет определить силу и направленность связей между конструктами респондента, выявить наиболее значимые (глубинные) конструкты, лежащие в основе конкретных оценок и от-ношений.
2.5. Интеллектуальный анализ данных
Методы интеллектуального анализа данных (ИАД), в частности технологии Data Mining (DM), в настоящее время широко применяются для решения задач извлечения знаний [23].
Интеллектуальный анализ данных – это процесс обнаружения в «сырых» данных неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний. При этом под «сырыми» понимается формат данных, не имеющий четкой спецификации и содержащий необработанные данные. В зарубежной литературе ИАД трактуется как Knowledge Discovery (KD) и DM. Под KD (обнаружением знаний) в БД понимается процесс идентификации достоверных, новых, потенциально полезных и хорошо интерпретируемых структур в данных, а под DM – этап процесса KD, состоящий в применении специфических алгоритмов порождения структур, извлеченных из БД. Английский термин «Data Mining» не имеет однозначного перевода на русский язык, поэтому используется в оригинале. Данное понятие приобрело высокую популярность в современной трактовке с первой половины 1990-х годов. До этого времени обработка и анализ данных осуществлялись в рамках прикладной статистики, при этом решались задачи обработки БД малой емкости.
В ИАД к обнаруживаемым знаниям предъявляются определенные требования:
ценность представляют новые, ранее неизвестные знания;
знания должны быть нетривиальными, отражать неочевидные, неожиданные закономерности, составляющие скрытые знания. Если знания могут быть получены более простыми методами, например на основе визуального анализа, то применение методов DM не оправдано;
знания должны быть доступными для интерпретации.
Процесс ИАД включает четыре основных этапа. На первом этапе аналитиком формулируется постановка задачи, на втором осуществляется подготовка данных для анализа, на третьем проводится анализ данных с помощью DM, а на четвертом осуществляется извлечение знаний, т.е. верификация и интерпретация полученных результатов. К основным задачам ИАД относятся классификация, кластеризация, регрессионный анализ, прогнозирование, поиск ассоциативных связей, анализ после-довательностей, анализ отклонений, оценивание и анализ связей.
Задача классификации заключается в том, что для каждого варианта определяется категория, или класс, к которому он принадлежит. Кластеризация заключается в делении множества объектов на группы (кластеры) схожих по параметрам. При этом, в отличие от класс-сификации, число кластеров и их характеристики не известны заранее, а определяются в ходе решения задачи исходя из степени близости объединяемых объектов по совокупности параметров. Задача ре-грессионного анализа состоит в структурно-параметрической иден-тификации модели между зависимой переменной (откликом) и неза-висимыми переменными (регрессорами), отражающей их причинно-следственную связь. При этом структура модели может быть линейной или нелинейной, аддитивной или мультипликативной. Если рассматривается недоопределенная задача регрессионного анализа (объем выборки меньше числа оцениваемых параметров), используются методы эвристической самоорганизации. Задача прогнозирования одномерных или многомерных временных рядов состоит в определении их значений на период упреждения. Поиск ассоциативных связей заключается в выявлелении часто встречающихся наборов объектов среди множества подобных наборов. Целью анализа последовательностей является обнаружение закономерностей в последовательностях событий, благодаря чему можно, например, предупредить сбой в работе информационной системы, получив сигнал о наступлении события, часто предшествующего сбою подобного типа.