Файл: В. И. Ульянова (Ленина) (СПбгэту лэти) Направление 27. 04. 04 Управление в технических системах Магистерская программа.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 277
Скачиваний: 1
СОДЕРЖАНИЕ
1.1 Explaining neural network:
1.2 Explaining the functionality of Neural Networks Works:
1.3.1 Convolutional Neural networks (CNN):
2. DESIGNING A CONVOLUTIONAL NEURAL NETWORK
2.1 Recurrent neural networks (RNNs):
2.2 Understanding Long Short-Term Memory (LSTM):
2.3 Describing LSTM mathematically:
2.4 Recurrent neural networks functionality in voice cloning applications:
3. IMPROVING DEEP LEARNING NETWORKS
3.1 Structure of Deep Learning:
3.2 Natural Language Processing using Voice Data:
4. VOICE PRE-PROCESSING USING DEEP LEARNING
4.2 Voice preprocessing implementation and logic:
4.3 Fast Fourier Transform (FFT):
4.4 Short-Time Fourier-Transform (STFT):
4.5 Mel frequency spectrum (MFCC):
4.7.3 Budling the autoencoder:
4.7.5 Results of the training process:
5.1 Explaining text to speech models (TTS):
5.2 DALL-E and its functionality:
5.3 Denoising Diffusion Probabilistic Models (DDPMs) and its functionality:
5.6 Implementing Tortoise-TTS:
5.6.2 Fine-Tuning Tortoise-TTS Model:
5.6.4 Installing Tortoise-TTS:
6.1 Compartment and validation of voice cloning output data:
7.2 Object and Company Description:
7.3 Market Analysis (Russia, Saint Petersburg):
7.4 Market Size and Growth Potential:
7.7 Marketing and Distribution Channels:
7.8 Regulatory and Cultural Considerations:
7.10 Economic Result Estimation:
7.11 Financial and Funding Plan:

Figure 39: the code implemented to generate the output.
Conclusions:
In this chapter, the implementation process is explained, with variant steps, and the process of voice cloning using the model studied which is (Tortoise-TTS) is explained, the code featuring implementation of the model is displayed.
The problem that occurred which is the non-native speaker problem in voice cloning is also discussed and several enchantments are applied in order to solve this problem.
6. RESULTS
6.1 Compartment and validation of voice cloning output data:
The data obtained is a is a 15 sec wav file, and in order to validate how close it is to the original voice and thus, how good is the model preforming and how successful is that data pre-processing was, a compartment between two MFCCs that are extracted from two voice samples is required, the first voice sample is a randomly selected sample from the dataset, the other voice sample is the voice generated from the model.
import librosa
import numpy as np
from scipy.spatial.distance import cosine
import matplotlib.pyplot as plt
# Function to extract MFCC features from an audio signal
def extract_mfcc(audio, sr):
mfccs = librosa.feature.mfcc(y=audio, sr=sr)
return mfccs
# Define two audio files to compare
audio_file_1 = '/home/lawliet/PycharmProjects/Voice_Mimic/Ali3.wav'
audio_file_2 = '/home/lawliet/PycharmProjects/Voice_Mimic/Ali_gen.wav'
# Load the audio files
audio_1, sr_1 = librosa.load(audio_file_1, sr=None, mono=True)
audio_2, sr_2 = librosa.load(audio_file_2, sr=None, mono=True)
# Extract MFCC features for each audio file
mfcc_1 = extract_mfcc(audio_1, sr_1)
mfcc_2 = extract_mfcc(audio_2, sr_2)


# Ensure the MFCC feature vectors have the same length
min_length = min(mfcc_1.shape[1], mfcc_2.shape[1])
mfcc_1 = mfcc_1[:, :min_length]
mfcc_2 = mfcc_2[:, :min_length]
# Normalize the MFCC vectors
mfcc_1_normalized = mfcc_1 / np.linalg.norm(mfcc_1)
mfcc_2_normalized = mfcc_2 / np.linalg.norm(mfcc_2)
# Compute the cosine similarity between the normalized MFCC vectors
similarity = 1 - cosine(mfcc_1_normalized.flatten(), mfcc_2_normalized.flatten())
# Define a threshold to determine if the voices belong to the same speaker
threshold = 0.8
# Clear output
plt.clf()
# Display the similarity score
print("Similarity Score:", similarity)
# Plot the MFCCs
plt.figure(figsize=(10, 4))
plt.imshow(mfcc_1, cmap='viridis', origin='lower', aspect='auto')
plt.colorbar(format='%+2.0f dB')
plt.title('MFCCs of Audio 1')
plt.xlabel('Frame')
plt.ylabel('MFCC Coefficients')
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 4))
plt.imshow(mfcc_2, cmap='viridis', origin='lower', aspect='auto')
plt.colorbar(format='%+2.0f dB')
plt.title('MFCCs of Audio 2')
plt.xlabel('Frame')
plt.ylabel('MFCC Coefficients')
plt.tight_layout()
plt.show()
# Compare the similarity score with the threshold
if similarity >= threshold:
print("The voices belong to the same speaker.")
else:
print("The voices belong to different speakers.")

Figure 40: the code implemented to validate the output.
In the previous code, MFCC s features were extracted from two voice samples: the first sample from the dataset and the second sample generated by a voice cloning model. By comparing these MFCC feature vectors, it is possible to measure the similarity between the two voice samples.
MFCCs are widely used in speech recognition and voice processing tasks as they capture the essential acoustic features of a voice signal.
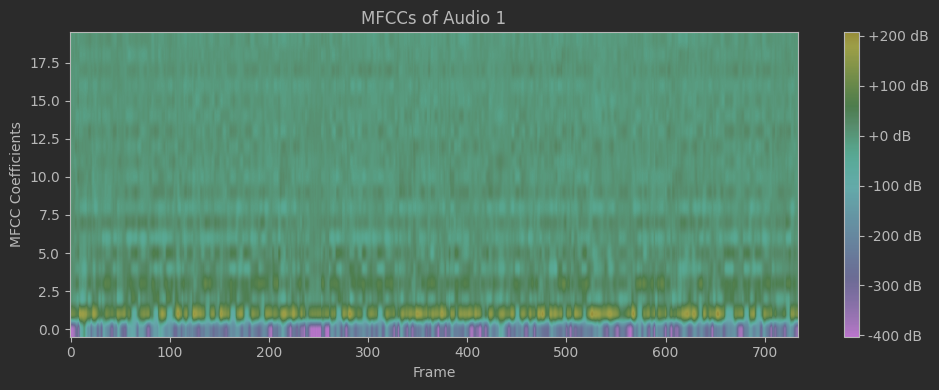
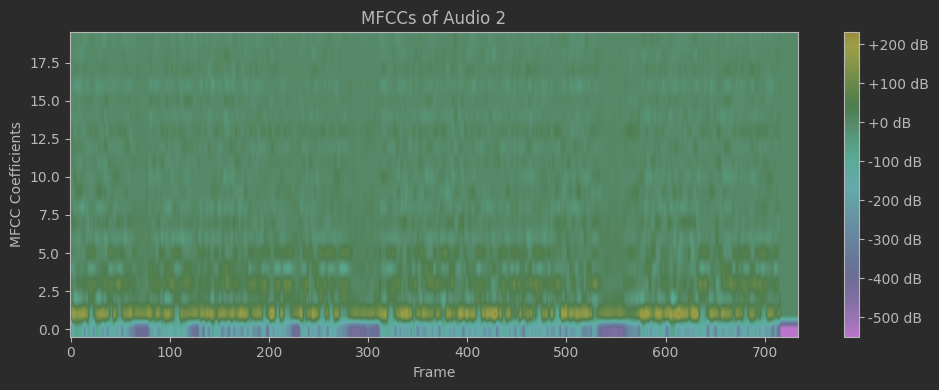
Figure 41: The plotted MFCCs features extracted top(original) bottom(cloned).
The similarity between the normalized MFCC vectors was calculated using the cosine similarity metric. From -1 to 1, the cosine similarity scales, with a value closer to 1 denoting greater similarity. To evaluate whether the voices originate from the same speaker, a threshold value of 0.8 was established. Indicating a considerable resemblance and a higher possibility that the generated voice is an accurate copy of the source voice; the similarity score should be above the threshold.
By establishing a threshold and evaluating the similarity score, it is possible to make a judgment on the accuracy of the voice cloning process. In this case, accomplishing a similarity score of 0.8 or higher indicated a substantial resemblance between the generated voice and the voice in the dataset, indicating a successful voice cloning outcome.
However, it is essential to note that comparing MFCCs alone cannot provide an absolute measure of accuracy. While MFCCs capture essential acoustic characteristics, they may not capture all the nuances and fine details of a voice. Factors such as intonation, prosody, as well as other subtle vocal nuances, may not be fully represented in the MFCC features. Hence, additional evaluation measures may be essential to assess the overall accuracy of voice cloning.
Conclusions:
In this chapter, the results of voice cloning process is displayed and the accuracy of the outputted cloned voice is discussed as well
Another approach to estimate the accuracy of the voice cloning is implemented and the results are displayed and explained as well.
7. DRAFTTING A BUISNESS PLANE
7.1 Executive Summary:
This business plan outlines the key elements and strategies for a voice cloning project in the market of Russia, specifically targeting Saint Petersburg. The project aims to develop and offer a voice cloning service that leverages advanced deep learning techniques to replicate and synthesize human voices with high accuracy and naturalness. The company undertaking this project envisions becoming a leader in the field of voice cloning, catering to various industries and individuals seeking personalized voice solutions.
7.2 Object and Company Description:
The objective of the voice cloning project is to develop a state-of-the-art voice cloning service that leverages advanced deep learning techniques to replicate and synthesize human voices with high accuracy and naturalness. The company, Deep Mimic Cloning Services (DMCS), is a technology-driven startup that aims to become a leader in the field of voice cloning by providing cutting-edge solutions to meet the growing demand for realistic and customizable voices.
Deep Mimic Cloning Services (DMCS) is founded by a team of experienced researchers and engineers who specialize in deep learning, speech processing, and artificial intelligence. The company's vision is to revolutionize the way voices are synthesized and reproduced, offering a range of applications across industries and catering to individuals seeking personalized voice solutions.
The company's mission is centered around three main pillars:
Innovation and Technological Excellence: Deep Mimic Cloning Services (DMCS) is committed to staying at the forefront of technological advancements in the field of voice cloning. The company invests heavily in research and development to enhance its algorithms, models, and methodologies. By continually pushing the boundaries of what is possible in voice synthesis, DEEP MIMIC CLONING SERVICES (DMCS)aims to deliver the most realistic and high-quality voice cloning solutions.
Customer-Centric Approach: Deep Mimic Cloning Services (DMCS) places a strong emphasis on understanding and meeting the unique needs of its customers. The company recognizes that every individual and business have specific requirements when it comes to voice solutions. Whether it's providing a voice for a virtual assistant, creating engaging audiobook narrations, or delivering captivating voice-overs for advertisements, DEEP MIMIC CLONING SERVICES (DMCS)strives to deliver personalized and tailored voice clones that align with the customer's preferences and objectives.
To achieve this, Deep Mimic Cloning Services (DMCS) offers a user-friendly platform that allows customers to customize and fine-tune various voice characteristics such as tone, pitch, accent, and emotional expressiveness. The platform provides an intuitive interface that enables users to interact seamlessly with the voice cloning technology, ensuring a user-friendly experience.
Ethical Considerations and Privacy: Deep Mimic Cloning Services (DMCS) recognizes the ethical concerns associated with voice cloning technology. The company is committed to upholding the highest standards of ethics and privacy in its operations. It adheres to strict data protection protocols and ensures that customer data is securely stored and used solely for the purpose of voice cloning. DEEP MIMIC CLONING SERVICES (DMCS)places great emphasis on obtaining proper consent and respecting the privacy rights of individuals whose voices are used in the cloning process.
Moreover, Deep Mimic Cloning Services (DMCS) actively promotes transparency and informs users about the limitations and potential risks associated with voice cloning.
The company encourages responsible usage of its technology and fosters open dialogue with customers, researchers, and regulatory bodies to address any ethical concerns or potential misuse of voice cloning technology.
As part of its commitment to the environment and sustainability, Deep Mimic Cloning Services (DMCS) also takes measures to minimize its carbon footprint. The company adopts energy-efficient infrastructure and employs environmentally friendly practices in its operations.
Deep Mimic Cloning Services (DMCS) envisions itself as a trusted partner for businesses and individuals seeking high-quality voice cloning solutions. The company aims to establish long-term relationships with its customers, providing ongoing support, updates, and enhancements to its voice cloning platform to meet evolving needs and technological advancements.
In summary, the object of the voice cloning project is to develop a cutting-edge voice cloning service that offers personalized, realistic, and high-quality voice clones. Deep Mimic Cloning Services (DMCS) is driven by innovation, customer-centricity, and ethical considerations. The company's mission is to lead the voice cloning industry by delivering advanced technological solutions, maintaining customer satisfaction, and upholding the highest standards of ethics and privacy.