Файл: В. И. Ульянова (Ленина) (СПбгэту лэти) Направление 27. 04. 04 Управление в технических системах Магистерская программа.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 283
Скачиваний: 1
СОДЕРЖАНИЕ
1.1 Explaining neural network:
1.2 Explaining the functionality of Neural Networks Works:
1.3.1 Convolutional Neural networks (CNN):
2. DESIGNING A CONVOLUTIONAL NEURAL NETWORK
2.1 Recurrent neural networks (RNNs):
2.2 Understanding Long Short-Term Memory (LSTM):
2.3 Describing LSTM mathematically:
2.4 Recurrent neural networks functionality in voice cloning applications:
3. IMPROVING DEEP LEARNING NETWORKS
3.1 Structure of Deep Learning:
3.2 Natural Language Processing using Voice Data:
4. VOICE PRE-PROCESSING USING DEEP LEARNING
4.2 Voice preprocessing implementation and logic:
4.3 Fast Fourier Transform (FFT):
4.4 Short-Time Fourier-Transform (STFT):
4.5 Mel frequency spectrum (MFCC):
4.7.3 Budling the autoencoder:
4.7.5 Results of the training process:
5.1 Explaining text to speech models (TTS):
5.2 DALL-E and its functionality:
5.3 Denoising Diffusion Probabilistic Models (DDPMs) and its functionality:
5.6 Implementing Tortoise-TTS:
5.6.2 Fine-Tuning Tortoise-TTS Model:
5.6.4 Installing Tortoise-TTS:
6.1 Compartment and validation of voice cloning output data:
7.2 Object and Company Description:
7.3 Market Analysis (Russia, Saint Petersburg):
7.4 Market Size and Growth Potential:
7.7 Marketing and Distribution Channels:
7.8 Regulatory and Cultural Considerations:
7.10 Economic Result Estimation:
7.11 Financial and Funding Plan:
4.7.1 Budling the encoder:
The structure of the encoder is built as following:
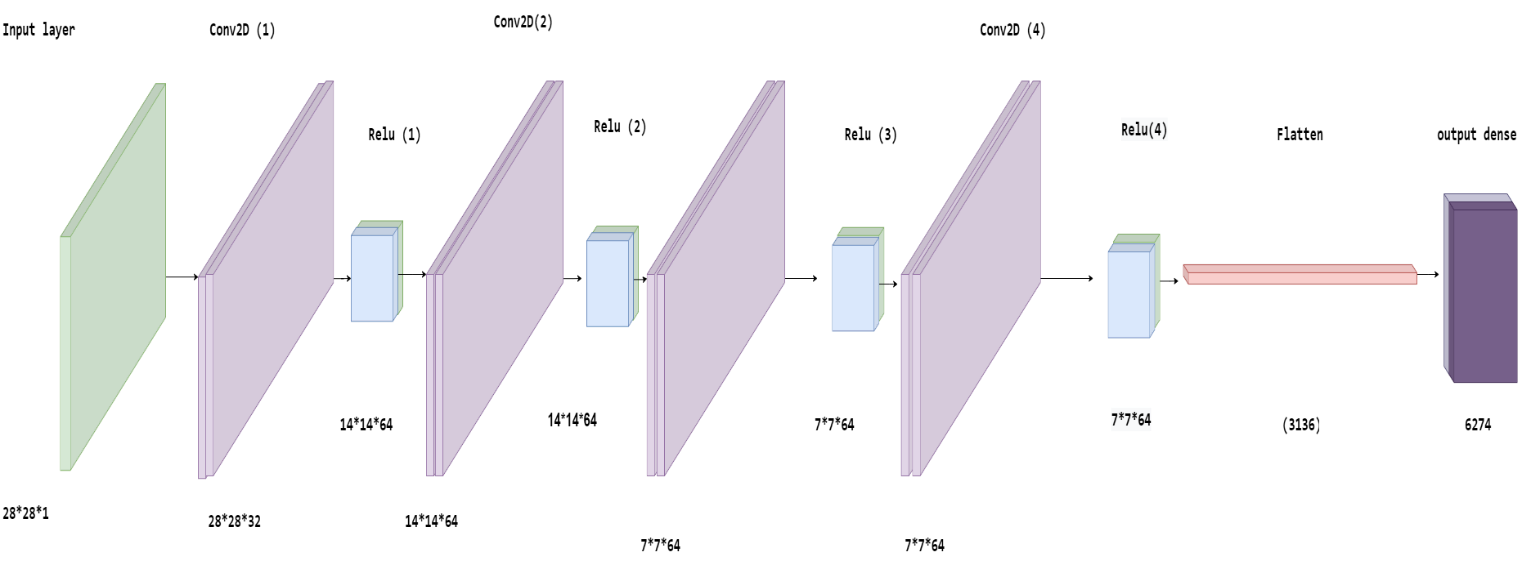

Figure 23: the encoder structure.
4.7.2 Building decoder:
The structure of decoder is built as following:
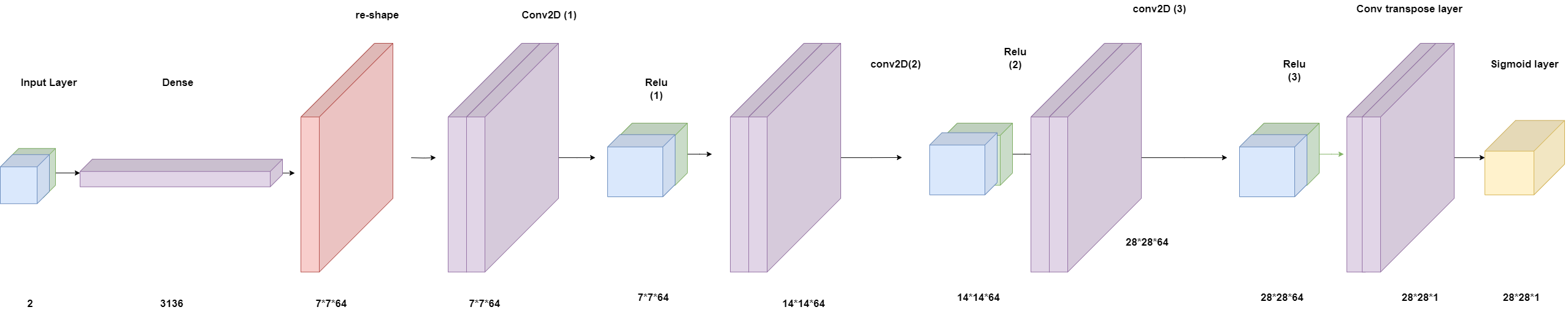

Figure 24: the decoder structure.
4.7.3 Budling the autoencoder:
"Autoencoding" is a data compression algorithm in which the compression and decompression algorithms are (1) data-specific, (2) lossy, and (3) automatically learned from examples rather than built by a human. Furthermore, the compression and decompression operations are implemented with neural networks in practically all cases where the word "autoencoder" is encountered.
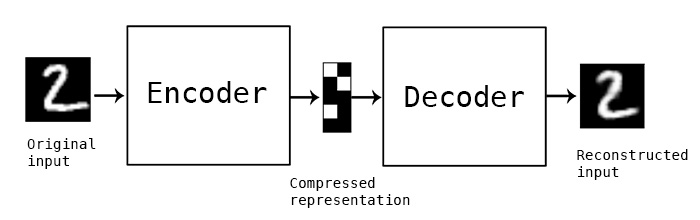
Figure 25: the autoencoder parts and their function.
As for the full auto encoder structure alongside the number of parameters resulted, it is possible to descript it as follows:

Figure 26: Autoencoder structure.
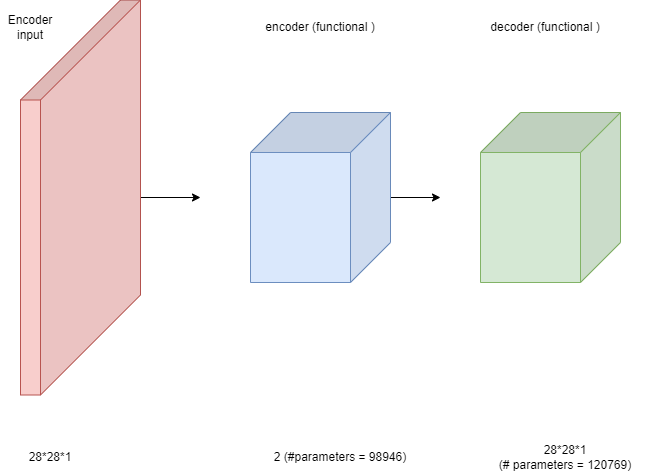
4.7.4 The training process:
As the start of training the autoencoder on the (MNIST) data set, the following summary and results is obtained:
The training process estimated time is 4 min with [500 sample] and 15 min with full data set.

Figure 27: code and training epoch for the "train" process
4.7.5 Results of the training process:
-
It is notable that the effect of the parameters [latent space demotion = 2, number of samples = 500], as shown:
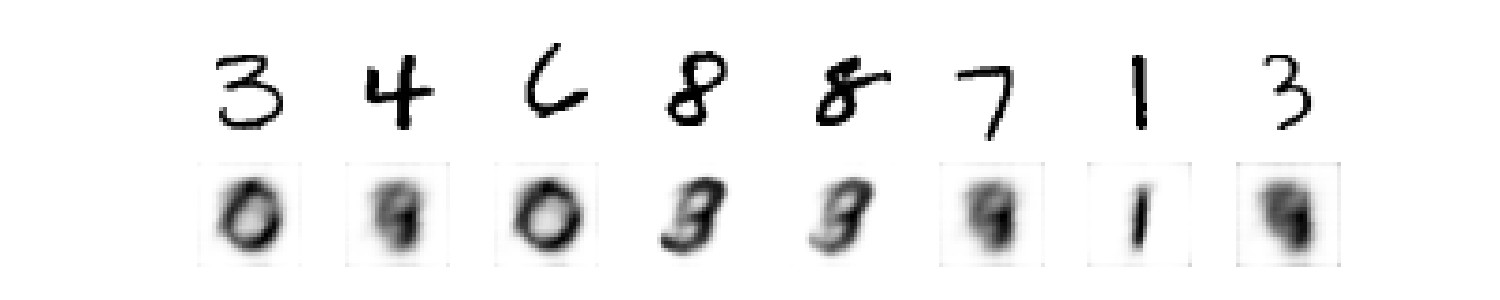

Figure 28: the random sample test.
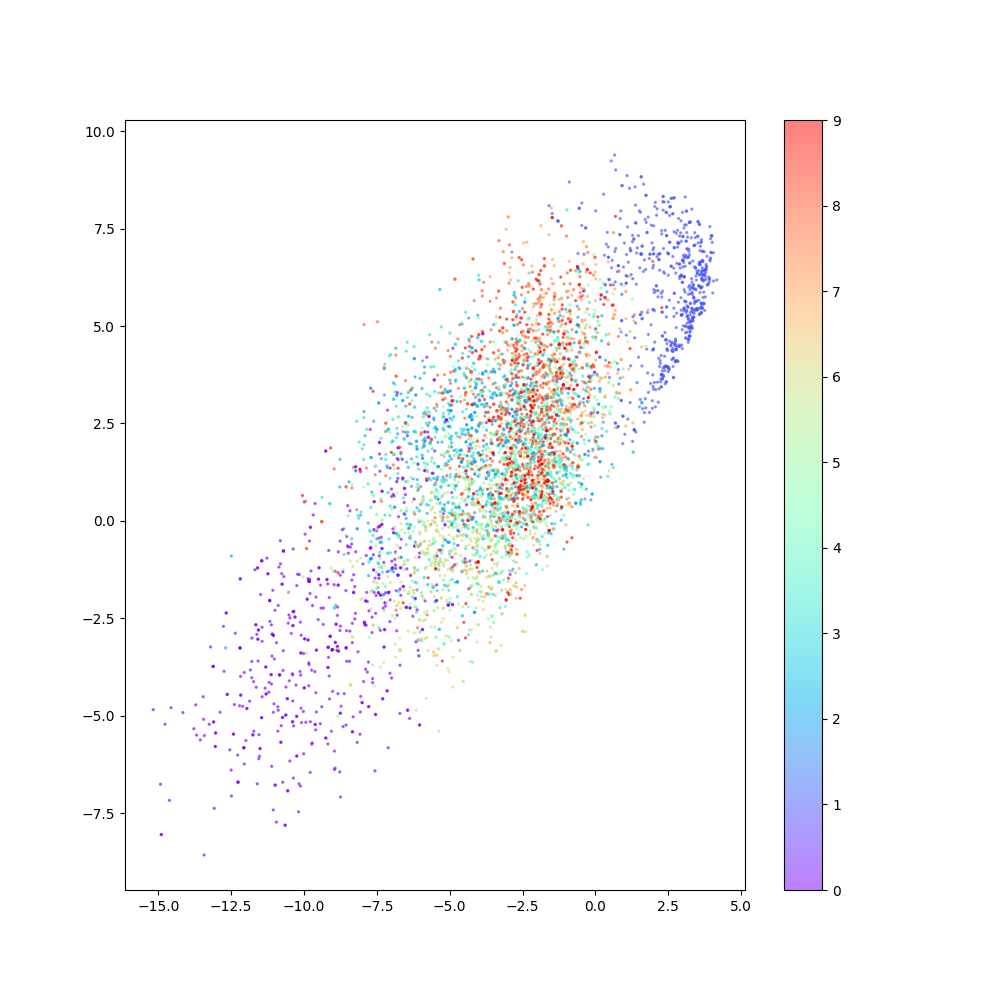
Figure 29: the samples distribution
As noticed the accuracy is not sufficient and therefore, and with changing the parameters and re run the train process.
-
changing the parameters [latent space demotion = 30, number of samples = full dataset], and the results as shown:
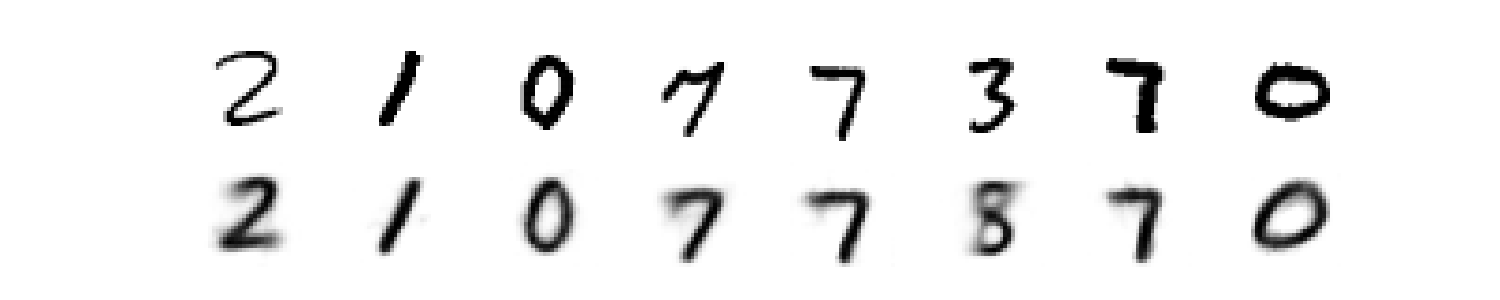
Figure 30: the random sample test (2).
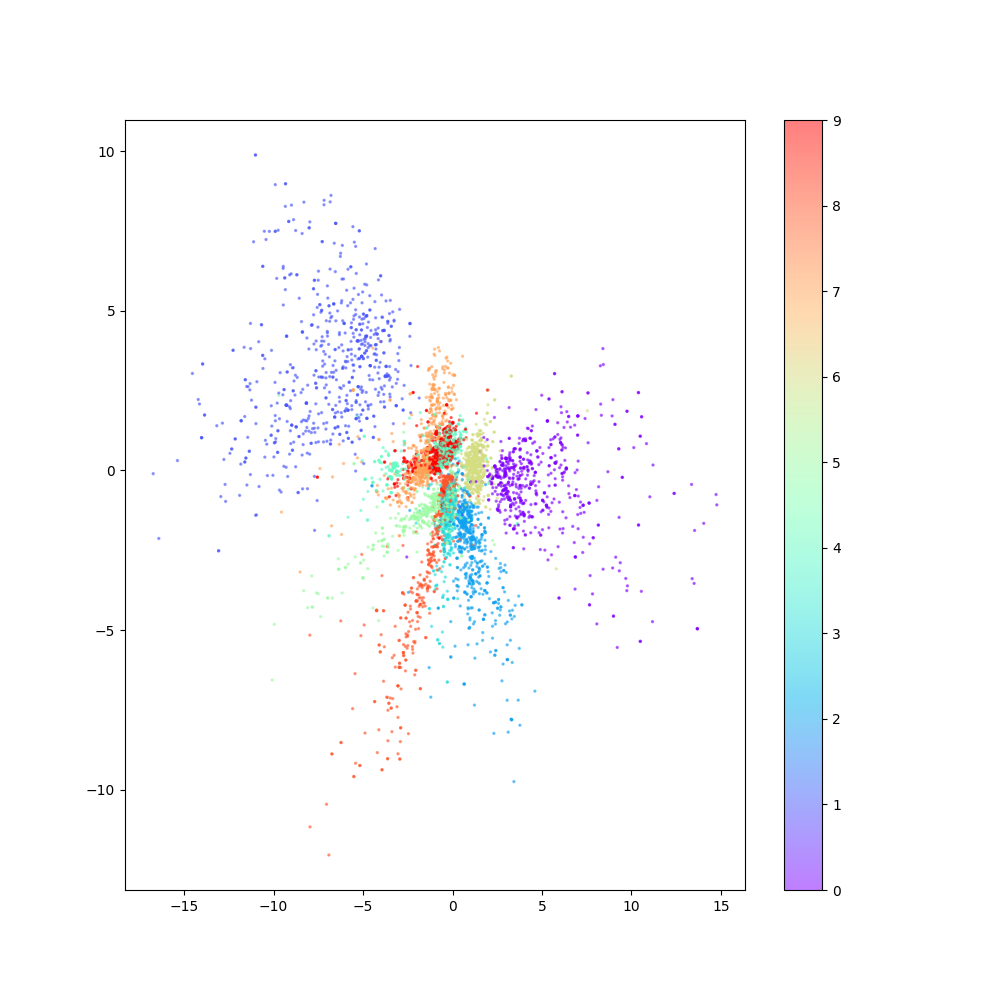
Figure 31: the samples distribution (2)
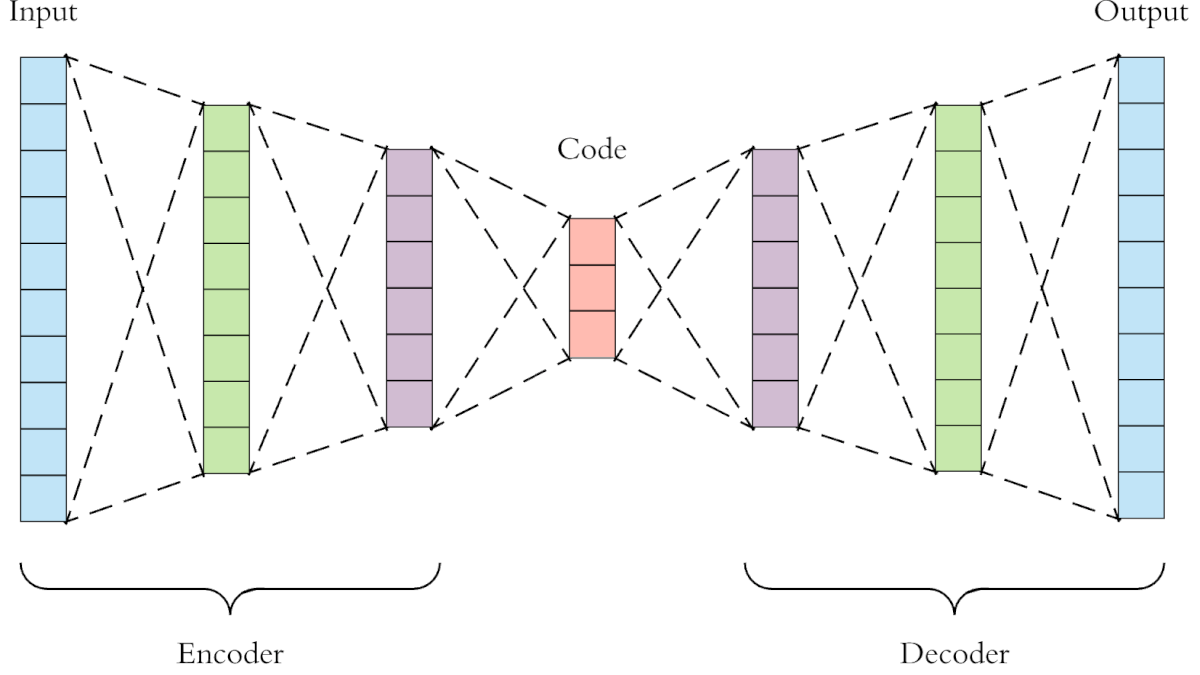
Figure 32: structure of vanilla autoencoder
This type of autoencoder depends on the bottle-nick logic-structure, by transforming voice data to mel spectrum, and process such data using an architecture similar to (encoder-decoder), it is possible to obtain a relatively acceptable results, but it won’t be sufficient to achieve the desired results from this process. [6]
As its clear, there is a significant improve in the performance of the model.
Conclusions:
In this chapter, the preprocess stage which considered to be extremely important for the voice cloning process is implemented alongside the implementation of the autoencoder neural network which is the main concept in most voice cloning models and obtained different results with variant accuracies based on parameters changing.
5 IMPLEMNTAION
5.1 Explaining text to speech models (TTS):
The method known as text-to-speech (TTS) transforms written text into spoken words. Natural language processing (NLP) has several uses, including assistive technology, language learning, and entertainment. One significant NLP application is TTS. In recent years, deep learning techniques have significantly contributed to the advancement of TTS technology.
Voice cloning, which involves creating a synthetic voice that closely mimics the voice of a specific individual, is a subset of TTS. There are a variety of potential uses for voice cloning, such as speech treatment, personal voice assistants, and entertainment. The quality and accuracy of voice cloning systems have showed considerable potential as a result of deep learning algorithms.
The three primary parts of a TTS system's basic architecture are waveform synthesis, auditory modeling, and text analysis. The written text is processed in the text analysis component to obtain linguistic and phonetic data about the words and phrases in the text. Using this data, a series of phonetic units is created to reflect the intended voice output.
The statistical model used to create the acoustic properties of the speech signal, such as the pitch, duration, and energy of each phonetic unit, is employed in the acoustic modeling component. Acoustic modeling has been enhanced in terms of accuracy and effectiveness using deep learning approaches. On benchmark datasets like the Blizzard Challenge, for instance, deep neural networks (DNNs) and recurrent neural networks (RNNs) have been used to generate acoustic features and have shown cutting-edge results.
The final speech signal is synthesized using the acoustic information in the waveform creation component. Concatenative synthesis, formant synthesis, and statistical parametric synthesis are a few of the techniques used to create waveforms. By learning to produce excellent voice signals directly from the acoustic features, deep learning techniques have been applied to raise the quality of waveform production. For instance, WaveNet models and generative adversarial networks (GANs) have been applied to produce high-quality speech signals that are nearly indistinguishable from real human speech.
Using deep learning, a neural network is trained to create a synthetic voice that closely resembles the speech of a particular person. The target person's voice recordings and associated transcripts of spoken text make up the training data. Using methods like supervised learning and reinforcement learning, the neural network is taught how to map written text to its corresponding spoken signal.
deep learning voice cloning faces a number of difficulties. One difficulty is the necessity for a lot of high-quality training data, which might be hard to come by for some people. Capturing the person's distinctive voice qualities, such as their accent, intonation, and talking style, is another issue. This necessitates the use of specialized neural network topologies and training methods, as well as the thoughtful selection and preprocessing of the training data.
Despite these difficulties, deep learning-based voice cloning has made significant progress in recent years, with some outstanding examples of synthetic voices that accurately imitate the voices of particular people. Speech therapy, personal voice assistants, and entertainment are just a few of the numerous potentials uses for this technology. Deep learning-based voice cloning is probably going to get much more precise and efficient as the technology develops, creating new possibilities for innovation and creativity.[7]
5.2 DALL-E and its functionality:
DALL-E is an artificial intelligence system developed by OpenAI, which uses deep learning to generate images from textual descriptions. The name is a combination of the artist Salvador Dali and the character EVE from the movie WALL-E. The system is built on the principles of GPT (Generative Pre-trained Transformer) and is capable of generating highly realistic and detailed images based on textual input.
The DALL-E framework has demonstrated how an autoregressive decoder can be effectively utilized for text-to-image generation, utilizing the advancements in decoder-only models in the NLP domain. However, two significant challenges remain. Firstly, the framework partially relies on full-sequence self-attention, which can be computationally expensive, particularly when working with modalities like images or audio with large sequence lengths. This issue can be challenging when addressed naively.
Secondly, the traditional autoregressive approach necessitates operating in the discrete domain, where images are encoded into sequences of discrete tokens to build a powerful Bayesian model. Although this enhances the expressiveness of the DALL-E model, it necessitates a decoder that can convert these image tokens back into the actual pixel values of an image. DALL-E 1 addresses this by utilizing a VQVAE decoder, which is susceptible to generating blurry images.
The process of generating images with DALL-E begins with the input of a textual description or prompt. The prompt can be anything from a simple sentence to a more complex paragraph. DALL-E then uses a pre-trained neural network to analyze the textual input and generate a low-resolution image that matches the description. The image is then refined by a separate neural network called a discriminator, which evaluates the image for its realism and provides feedback to the generator network.
The discriminator network is trained on a dataset of real images to learn what makes an image realistic. It compares the generated image with the real images in the dataset and provides feedback to the generator network on how to improve the image. The generator network then makes adjustments to the image based on the feedback and generates a new image. This process continues until the discriminator network determines that the image is realistic enough to match the textual description.
DALL-E uses a process called attention, which allows it to focus on different parts of the input text when generating images. This enables the system to create highly detailed images that closely match the textual description. The system is also able to generate images that combine multiple prompts or concepts, such as an armchair in the shape of a avocado or a snail made of harps.
One of the most impressive aspects of DALL-E is its ability to create images that do not exist in the real world. For example, it can generate images of animals that are a combination of multiple species or objects that have never been seen before. This is achieved through a process called hallucination, which allows the system to generate images that are not constrained by reality.
The potential applications of DALL-E are vast and varied. It can be used to create images for advertising, design, and entertainment industries. It can also be used to generate images for scientific research, such as generating images of complex molecules or biological structures. However, there are also concerns about the potential misuse of the technology, such as creating images for fake news or propaganda.
In conclusion, DALL-E is a highly advanced artificial intelligence system that uses deep learning to generate highly realistic images from textual input. It is capable of creating images that do not exist in the real world and has numerous potential applications in various industries. [8]
5.3 Denoising Diffusion Probabilistic Models (DDPMs) and its functionality:
Denoising Diffusion Probabilistic Models (DDPMs) are generative models which employ a probabilistic diffusion process to model the fundamental data distribution.
The basic idea beneath DDPMs is to start with a low-quality image or signal and then continually add noise to it. At each iteration, the model then tries to remove the added noise and reconstruct the initial signal or image. This process continues until the desired level of noise is achieved, at which point the final output is regarded to be a high-quality reconstruction of the original signal or image.
DDPMs utilize a Markov chain Monte Carlo (MCMC) process to sample from the posterior distribution of the model. During instruction, the model learns the parameters of a sequence of diffusion steps, that are then used to sample from the posterior distribution. The diffusion steps constitute a series of conditional distributions which explain how the noise should be added to the signal at each step. These steps tend to be parameterized by a neural network that takes as input the previous state and generates a new state with added noise.
DDPMs also use a score-based approach to train the model. In this approach, the model is trained to maximize the probability associated with the observed data, but instead of directly computing the likelihood, the model is trained to maximize a lower bound on the the probability known as the log-likelihood ratio. This lower bound is easier to compute and optimize than the real probability and has been shown to be effective in practice.
One advantage of DDPMs is that they are able to generate high-quality images with very little mode collapse, which has been a problem with many other generative models. Another advantage is that they are able to use low-quality guidance signals, such as low-resolution images, to reconstruct high-dimensional data.
DDPMs do have some restrictions, though. One drawback is that they can't learn to convert signals that aren't aligned, like text-to-audio, because they need the guidance signal to be in phase with the output. Another drawback is that for strong multi-modal performance, they need a lot of computing.
In the figure (33) x₀, x₁, x₂,…, x_T are d-dimensional multivariate Gaussian random variables. using the random variable x₀ to represent natural images.
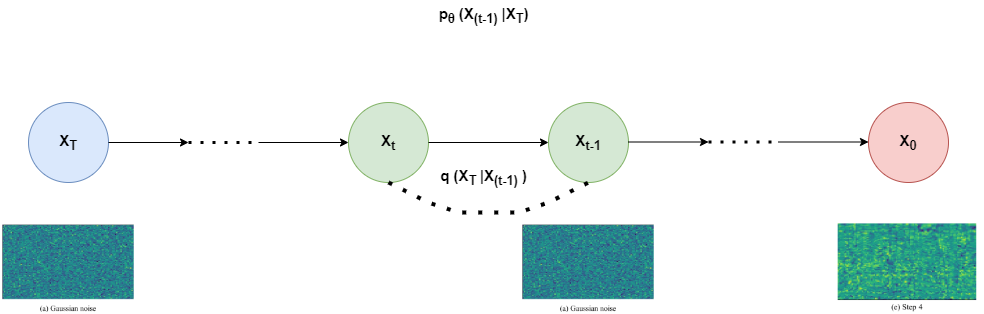
Figure 33: directed graphical model of DDPMs.
Despite their effectiveness, there are two limitations to DDPMs. In the beginning, they rely on guidance signals being aligned with the output, which means they cannot learn to convert unaligned inputs like text into signals that are audio. In addition, DDPMs require an extended sampling process, resulting in an inherent limitation of multi-modal inductive prior which calls for more computing power.
DALL-E introduced the concept of re-ranking, which involves randomly sampling from an autoregressive model and selecting the highest quality output of k outputs for downstream use. To achieve this, a strong discriminator is necessary, one that can distinguish good text-image pairings from bad ones. DALL-E used CLIP, a model trained with a contrastive text and image pairing objective, as a discriminator.
Gaussian noise, also known as white noise, is a type of random noise that follows a Gaussian distribution. It is characterized by unpredictability in amplitude and frequency throughout the entire spectrum. In the framework of voice cloning, Gaussian noise refers to the existence of random fluctuations in the generated voice signal that can degrade its quality and realism.
Gaussian noise can be established during the voice cloning process due to various factors such as imperfect training data, constraints in the voice cloning model, or inherent noise in the recording environment. These noise artifacts can manifest as unwanted background sounds, distortions, or discrepancies in the generated voice.[9]
5.4 Tacotron and Tortoise:
Tacotron and Tortoise-TTS are two neural text-to-speech (TTS) systems that use deep learning to generate speech from text input. While both systems strive to provide high-quality, comprehensible voice samples, they differ in their underlying architecture and method of speech synthesis.