Файл: В. И. Ульянова (Ленина) (СПбгэту лэти) Направление 27. 04. 04 Управление в технических системах Магистерская программа.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 292
Скачиваний: 1
СОДЕРЖАНИЕ
1.1 Explaining neural network:
1.2 Explaining the functionality of Neural Networks Works:
1.3.1 Convolutional Neural networks (CNN):
2. DESIGNING A CONVOLUTIONAL NEURAL NETWORK
2.1 Recurrent neural networks (RNNs):
2.2 Understanding Long Short-Term Memory (LSTM):
2.3 Describing LSTM mathematically:
2.4 Recurrent neural networks functionality in voice cloning applications:
3. IMPROVING DEEP LEARNING NETWORKS
3.1 Structure of Deep Learning:
3.2 Natural Language Processing using Voice Data:
4. VOICE PRE-PROCESSING USING DEEP LEARNING
4.2 Voice preprocessing implementation and logic:
4.3 Fast Fourier Transform (FFT):
4.4 Short-Time Fourier-Transform (STFT):
4.5 Mel frequency spectrum (MFCC):
4.7.3 Budling the autoencoder:
4.7.5 Results of the training process:
5.1 Explaining text to speech models (TTS):
5.2 DALL-E and its functionality:
5.3 Denoising Diffusion Probabilistic Models (DDPMs) and its functionality:
5.6 Implementing Tortoise-TTS:
5.6.2 Fine-Tuning Tortoise-TTS Model:
5.6.4 Installing Tortoise-TTS:
6.1 Compartment and validation of voice cloning output data:
7.2 Object and Company Description:
7.3 Market Analysis (Russia, Saint Petersburg):
7.4 Market Size and Growth Potential:
7.7 Marketing and Distribution Channels:
7.8 Regulatory and Cultural Considerations:
7.10 Economic Result Estimation:
7.11 Financial and Funding Plan:
1.3.5 Filters:
Convolutional Neural Networks (CNNs) use filters to obtain features from the input data. Filters are small matrices that move over the input data, computing a dot product across the filter and the input at each position. The result is a new feature map that highlights certain structures or patterns in the input.
The dimensionality of the filters used in CNNs is determined by the dimensionality of the input data. In broad terms, 1D filters are used for processing sequential data, such as time series or text, while 2D filters are used for processing 2D images, and 3D filters are used for processing 3D volumes, such as MRI scans or videos, as explained in the following:
-
1D filters are often used in speech recognition, where the input data is a time series of voice samples. The filters slide over the input signal along the time axis, capturing specific patterns in the waveform. These patterns may correspond to phonemes or other acoustic features that are relevant for speech recognition. -
2D filters are frequently employed in computer vision tasks, such as object detection or image classification. The filters slide over the input image, computing a dot product between the filter and the pixel values at every position. This highlights local patterns or features in the image, such as edges or textures. -
3D filters are used for processing 3D volumes, such as medical images or video data. The filters slide over the input volume along three dimensions, recording local patterns or structures in the data. These patterns can represent anatomical features or relevant movement patterns for the given task.
The use of filters in CNNs allows the network to learn local patterns or features in the input data that are relevant to the given assignment.
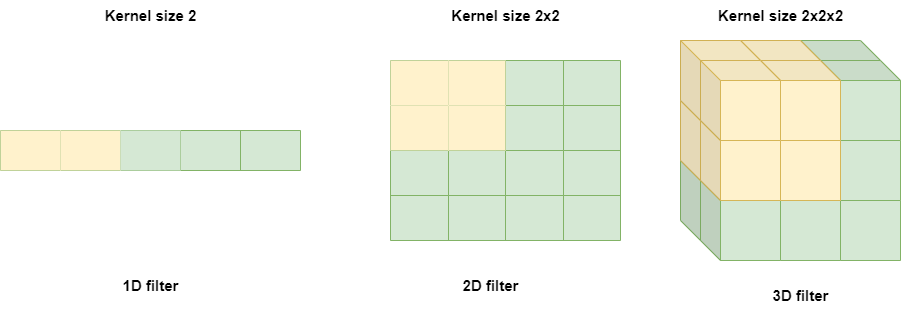
Figure 5: Filters types and structures.
By stacking multiple layers of filters and pooling processes, CNNs can learn increasingly complicated representations of the input data, leading to advanced performance in a wide range of applications
Conclusions:
In this chapter, the basics of deep learning has been discussed, featuring different concepts of artificial neural networks and different operations and the concept of activation function and its roll in the enhancement of the functionality in deep learning applications.
2. DESIGNING A CONVOLUTIONAL NEURAL NETWORK
Designing a Convolutional Neural Network (CNN) includes several important phases, including establishing the network's architecture, defining its parameters, and training it on a dataset. In the context of voice applications, such as speech recognition or speaker identification, or voice cloning, the choice of CNN architecture can have an enormous effect on performance.
When developing a CNN for voice applications, one approach is to employ a 1D convolutional layer to process the audio waveform. This layer applies a set of filters to small segments of the input signal and generates a set of feature maps that capture different aspects of the audio signal. These feature maps are then fed into one or more fully connected layers to generate predictions.
Another approach is to utilize a spectrogram representation of the audio signal as input and apply 2D convolutional layers to the spectrogram. This can be particularly useful for tasks such as speaker identification, where the frequency content of the audio signal could prove more informative than its temporal structure.
The capacity of CNNs to handle inputs of various sizes and aspect ratios is one of their key features.
This is accomplished by employing pooling layers, which shrink the size of the feature maps while keeping the most crucial data. Additionally, CNNs may be trained from beginning to end, enabling the model to directly learn both low-level and high-level characteristics from the input data as described in Figure 6.
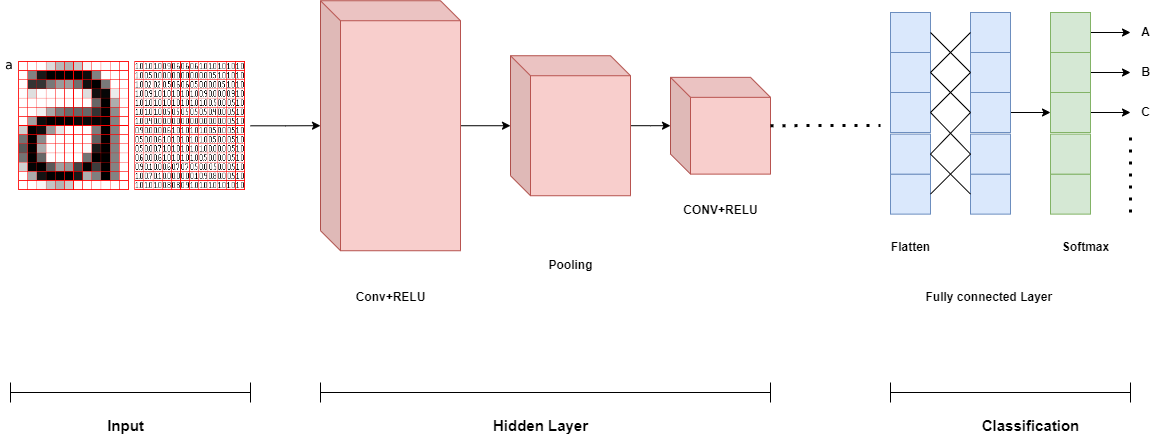
Figure 6: Architecture of a CNN.
For a variety of computer vision tasks, a number of pre-trained CNN models can be utilized as a starting point. On a number of benchmark datasets, these models—including VGG, ResNet, and Inception—achieved state-of-the-art performance. They can also be fine-tuned on new datasets with only a modest quantity of input. Transfer learning is a frequent technique used in practice to reduce the quantity of data and time needed to train a new model. Transfer learning is taking a pre-trained model and adapting it to a new task.
To increase their effectiveness and performance, CNN architectures have undergone a number of modifications in recent years. Utilizing residual connections is one such advancement that enables the model to learn residual functions rather than direct mappings, simplifying deep model optimization. The application of attention methods, which enable the model to choose attend to various input components and enhance both accuracy and interpretability, is another advancement. [1][2]
2.1 Recurrent neural networks (RNNs):
Recurrent neural networks (RNNs) are a subset of neural networks that are employed for time series, speech, and other sequences of data. They have a loop structure that enables them to keep a state inside that is dependent on the inputs from before.
In practical situations, there are several possibilities for implementation for RNNs, each with its own advantages and limitations.
One popular implementation is the Long Short-Term Memory (LSTM) architecture. LSTMs are a type of RNN that include additional memory cells and gating processes that allow the network to selectively recall or forget information from previous inputs. LSTMs can be especially effective for tasks that require long-term memory, such as speech recognition or machine translation.
2.2 Understanding Long Short-Term Memory (LSTM):
Long Short-Term Memory (LSTM) is a form of Recurrent Neural Network (RNN) that is developed to handle the vanishing gradient problem that occurs in standard RNNs. LSTMs can be especially effective at processing sequential data, such as time series, audio, and natural language, due to their ability to selectively remember or forget information from prior inputs.
At a high level, an LSTM is composed of a series of memory cells and gating mechanisms which regulate the flow of information between the current input and the previous hidden state. The memory cells are responsible for storing information over an extended period, while the gating mechanisms regulate the flow of information by selectively permitting or prohibiting certain inputs.
The three main components of an LSTM cell are:
-
Forget Gate: This gate decides what information from the previous cell state should be overlooked or retained. It takes the previous hidden state and the current input as input and outputs a vector of values between 0 and 1, which demonstrates which parts of the previous cell state should be kept (1) or forgotten (0) -
Input Gate: This gate determines what information from the current input should be added to the cell state. It utilizes the previous hidden state and the current input as input and outputs a vector of values between 0 and 1, which demonstrates how much of the new information should be added to the cell state. -
Output Gate: This gate decides what information from the cell state can be outputted. It utilizes the previous hidden state and the current input as input and outputs a vector of values between 0 and 1, which indicates how much of the current cell state must be outputted.
The input gate and forget gate are controlled by sigmoid activation functions, which output values between 0 and 1, and the output gate is regulated by a tanh activation function, which outputs values between -1 and 1.
These gates allow the LSTM to selectively store or discard information from previous time steps, based on the current input and the task at hand.
The Gated Recurrent Unit (GRU) architecture, which resembles LSTM but has a more straightforward structure, is another alternative for implementation. GRUs use gating mechanisms to control the flow of information between the current input and the previous hidden state. They are more computationally effective than LSTMs and are often used for assignments that require faster inference, such as speech synthesis or music generation.
In addition to LSTM and GRU, there are also simpler RNN architectures, such as vanilla RNN or Elman networks, which are suited to tasks that do not require long-term memory or complex sequence modeling.
In computer vision applications, convolutional neural networks (CNNs) are a common type of neural network. By extracting spatial features from the data, they are specifically created to handle image data. In order to recognize particular patterns and characteristics, CNNs subject the image to a number of convolutional filters. CNNs are particularly good at handling complicated images because they can learn features at many sizes and hierarchies. [3]
2.3 Describing LSTM mathematically:
It is possible to explain the math and logic behind LSTM as follows:
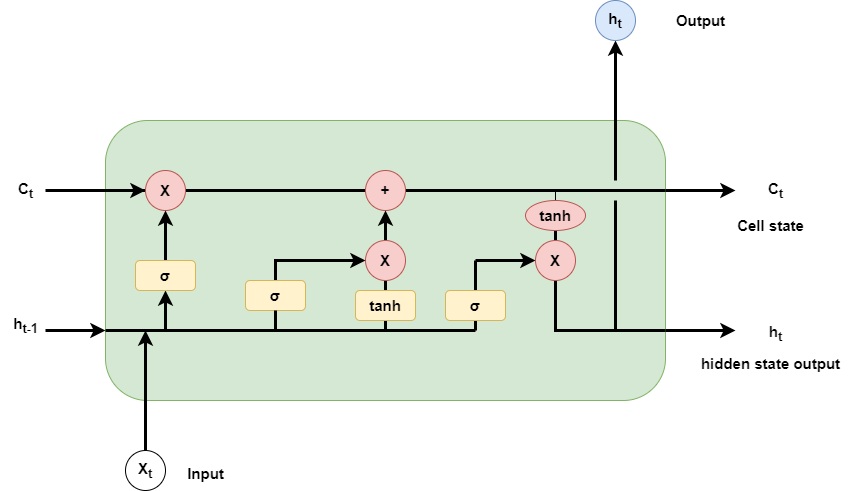
Figure 7: Long-short term memory (LSTM) cell.
It is possible to formalize this equation:
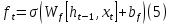
Where
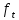 is a forget matrix for t which is a result of a forget gate.
is a forget matrix for t which is a result of a forget gate.And
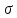 is a sigmoid dens layer,
is a sigmoid dens layer, 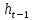 is the hidden state from the previous cell,
is the hidden state from the previous cell, 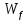 is the wights matrix,
is the wights matrix, 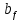 in a bias term.
in a bias term.Thus, obtaining a matrix which is a filter to what is forgettable.
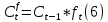
where
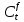 is the cell state from the previous time step, which it is decided what to forget in the current step.
is the cell state from the previous time step, which it is decided what to forget in the current step. 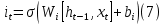
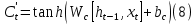
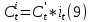
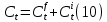
where
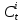 indicate to what is important to add as new information which sum to
indicate to what is important to add as new information which sum to 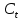 which is the cell state.
which is the cell state.The output is formulated as the following:
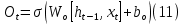

Finding the ideal hyperparameters for the neural network is one of the main issues in deep learning. The learning rate, number of layers, and size of each layer are examples of hyperparameters, which are parameters that are established prior to training a neural network. The effectiveness of the model is substantially impacted by these hyperparameters. It can be difficult to determine the best hyperparameters and requires thorough experimentation. The best hyperparameters can be found using methods like grid search and random search. To effectively explore the hyperparameter space, automated methods like genetic algorithms and Bayesian optimization can be applied.
2.4 Recurrent neural networks functionality in voice cloning applications:
Voice cloning is a task in which a machine-learning model is trained to generate speech that sounds like a specific person. This task can be approached using a variety of neural network architectures, including Recurrent Neural Networks (RNNs).
One RNN structure that has been utilized in voice cloning applications is the WaveNet architecture. WaveNet is a type of RNN that is specially designed for generating raw audio waveforms. It uses a dilated convolutional neural network (CNN) as the core processing block, enabling it to generate long-term dependencies in the audio signal.
The WaveNet architecture uses a causal convolutional structure, which means that each output sample only depends on previous samples. Making it suitable for generating speech or other audio signals in a streaming process, where the output is generated a single sample at a time.
In voice cloning applications, WaveNet is typically trained on a large dataset of speech recordings from the intended speaker. The network learns to model the speaker's unique patterns of speech, involving their intonation, pronunciation, and cadence. Once the model is trained, it can be used to generate new speech that sounds like the intended speaker, either by synthesizing new audio from scratch or by altering existing audio recordings.
Several voice cloning applications, such as producing natural-sounding speech for virtual assistants, voice-overs for video games, and customized text-to-speech systems, have successfully used WaveNet.[4]
2.5 Gated Activation Units:
The primary source of non-linearity in the WaveNet architecture applies from the activation units complying with the dilated causal convolution operation in the residual.
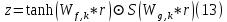
where (r) is the input of the residual unit, (*) stands for dilated causal convolution, (⊙) is an element-wise multiplication, (k) is the layer index, (f) and (g) respectively denote filter (activation function tanh) and gate (sigmoid activation S), and (W) stand for learnable convolution filters.
Softmax Distribution:
WaveNet estimates a non-normalized probability distribution and converts it into a proper probability distribution through using a normalized exponential function referred to as the SoftMax function.
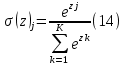
The SoftMax function is a generalized logistic function that takes as input a vector of real values and outputs positive real numbers that sum to 1.
2.6 Conditional WaveNet:
Conditioners add parameters to the probability distribution function so that it depends not only on the previously generated samples, but also on some variables that describe the audio to be generated.
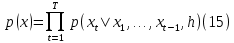
where ℎ is a set of conditioners. lacking ℎ, the autoregressively generated sample might have the most probable value based on the previously generated samples.
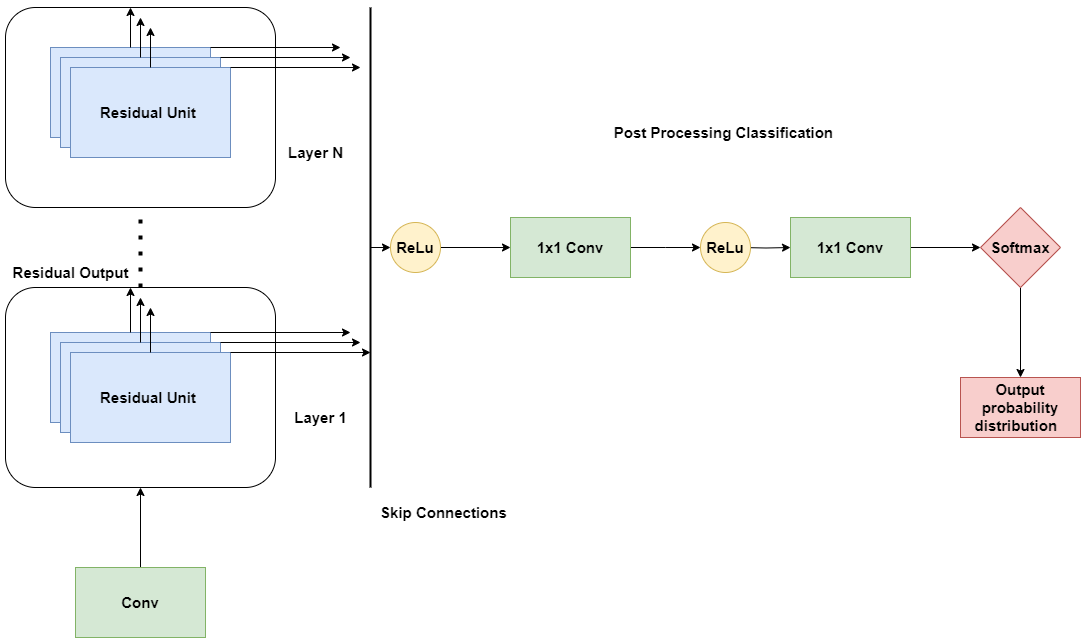
Figure 8: The architecture of WaveNet.
Conclusions:
In this chapter, the basics of designing recurrent neural networks is discussed alongside some of the used models in the process of voice cloning which functions recurrent neural networks such as WaveNet and some effective architecture such as LSTM.
3. IMPROVING DEEP LEARNING NETWORKS
Optimizing the network's hyperparameters is a necessary step in improving deep learning networks. The learning rate, batch size, number of layers, number of neurons in each layer, activation functions, and regularization methods are examples of hyperparameters that affect how the network behaves during training. For a model to perform well and avoid overfitting, certain hyperparameters must be tuned properly.
Deep learning networks can be improved using a variety of methods. Grid search is a popular method that involves selecting a set of hyperparameters and training the network on every possible combination of those hyperparameters. The final model's hyperparameters are then chosen based on their performance. Despite being efficient, grid search can be computationally expensive, especially for big networks and datasets.