Файл: В. И. Ульянова (Ленина) (СПбгэту лэти) Направление 27. 04. 04 Управление в технических системах Магистерская программа.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.10.2023
Просмотров: 277
Скачиваний: 1
СОДЕРЖАНИЕ
1.1 Explaining neural network:
1.2 Explaining the functionality of Neural Networks Works:
1.3.1 Convolutional Neural networks (CNN):
2. DESIGNING A CONVOLUTIONAL NEURAL NETWORK
2.1 Recurrent neural networks (RNNs):
2.2 Understanding Long Short-Term Memory (LSTM):
2.3 Describing LSTM mathematically:
2.4 Recurrent neural networks functionality in voice cloning applications:
3. IMPROVING DEEP LEARNING NETWORKS
3.1 Structure of Deep Learning:
3.2 Natural Language Processing using Voice Data:
4. VOICE PRE-PROCESSING USING DEEP LEARNING
4.2 Voice preprocessing implementation and logic:
4.3 Fast Fourier Transform (FFT):
4.4 Short-Time Fourier-Transform (STFT):
4.5 Mel frequency spectrum (MFCC):
4.7.3 Budling the autoencoder:
4.7.5 Results of the training process:
5.1 Explaining text to speech models (TTS):
5.2 DALL-E and its functionality:
5.3 Denoising Diffusion Probabilistic Models (DDPMs) and its functionality:
5.6 Implementing Tortoise-TTS:
5.6.2 Fine-Tuning Tortoise-TTS Model:
5.6.4 Installing Tortoise-TTS:
6.1 Compartment and validation of voice cloning output data:
7.2 Object and Company Description:
7.3 Market Analysis (Russia, Saint Petersburg):
7.4 Market Size and Growth Potential:
7.7 Marketing and Distribution Channels:
7.8 Regulatory and Cultural Considerations:
7.10 Economic Result Estimation:
7.11 Financial and Funding Plan:
Tacotron is built on an encoder-decoder architecture that creates speech from inputted text using a sequence-to-sequence paradigm. The encoder takes the input text and converts it into a list of sophisticated linguistic elements like phonemes or graphemes. These attributes are then fed into the decoder, which creates the corresponding speech waveform. The output of the decoder is sent via a post-processing module, which modifies the synthetic speech's prosody and intonation to make it seem more realistic.
Tacotron architecture offers a number of significant benefits for voice synthesis. First, it gives the model the ability to handle variable-length input sequences, which is crucial for TTS applications that call for the model to produce voice from any given text input.
Additionally, it enables the model to understand the intricate correspondences between text and voice, such as the connections between different phonemes and the prosodic elements of the speech waveform. Finally, the model can produce speech that is understandable and natural-sounding, even for challenging or confusing input sequences, thanks to the usage of an encoder-decoder architecture.
Tacotron, however, also has a number of drawbacks. It can be challenging to accurately represent natural-sounding prosody and intonation with a sequence-to-sequence model, which is one of the main issues in TTS. Tacotron solves this problem by including a post-processing module that modifies the prosody and intonation of the synthesized speech, this method can be complicated and challenging to optimize.
Tortoise-TTS, on the other hand, is based on a feed-forward transformer architecture that uses self-attention mechanisms to model the relationships between the input text and the generated speech. The transformer architecture was initially created for tasks related to machine translation that involved natural language processing, but it has since been modified for TTS applications.
Compared to Tacotron, Tortoise-TTS architecture has a number of benefits. First, the model can capture long-range dependencies between various parts of the input text thanks to the usage of self-attention mechanisms, which is helpful for producing speech with realistic-sounding prosody and intonation. Second, compared to the encoder-decoder design used in Tacotron, the feed-forward transformer architecture is extremely parallelizable, making it easier to train and use. The model may also directly learn from the acoustic properties of the target voice while training with raw audio data, which can enhance the quality of the synthetic speech.
Tortoise-TTS also has a number of drawbacks. The model cannot handle variable-length input sequences as successfully as Tacotron since it has a feed-forward architecture. This could be a drawback in TTS applications where the model must produce speech from unrestricted text inputs. Additionally, because the model is trained on raw audio input, obtaining sufficient training data for it to function well in particular applications can be difficult.
Overall, the choice of architecture depends on the specific needs and constraints of the TTS application. Tacotron is a good choice for applications that require the model to generate speech from arbitrary text inputs and prioritize natural-sounding prosody and intonation. Tortoise-TTS is a good choice.[10]
5.5 Tortoise-TTS:
Tortoise-TTS is a deep learning-based text-to-speech (TTS) system that synthesizes human-like speech from text inputs. It is a neural network-based TTS model that uses deep learning to model the relationship between text inputs and their corresponding speech outputs. The model consists of three main components: a text encoder, an acoustic model, and a vocoder.
The text encoder is responsible for converting text inputs into a numerical representation that can be used as input to the acoustic model. In Tortoise-TTS, the text encoder is a bidirectional Long Short-Term Memory (LSTM) network that takes in sequences of characters and outputs a sequence of hidden states. The bidirectional nature of the LSTM allows it to capture both forward and backward dependencies in the text input.
The acoustic model is responsible for predicting the acoustic features of the speech output given the text input. In Tortoise-TTS, the acoustic model is a convolutional neural network (CNN) that takes in the hidden states from the text encoder and outputs a sequence of acoustic features. The CNN is composed of multiple layers of convolutional and pooling operations, followed by a few fully connected layers. The convolutional layers extract high-level features from the hidden states, while the fully connected layers predict the acoustic features.
The acoustic features predicted by the acoustic model are in the form of Mel-spectrograms, which are representations of the speech signal in the frequency domain. The vocoder is responsible for converting these Mel-spectrograms into time-domain waveforms that can be played back as speech. In Tortoise-TTS, the vocoder is a variant of the WaveRNN model, which is a type of autoregressive model that generates waveforms one sample at a time.
Tortoise-TTS also uses several techniques to improve the quality of the synthesized speech. One such technique is data augmentation, which involves randomly perturbing the text inputs and acoustic features during training to increase the robustness of the model. Another technique is the use of multi-speaker models, which are trained on speech data from multiple speakers to increase the diversity of the synthesized speech.
In terms of training, Tortoise-TTS uses a combination of supervised and unsupervised learning. The text encoder and acoustic model are trained in a supervised manner using pairs of text and speech data, while the vocoder is trained in an unsupervised manner using only the Mel-spectrograms predicted by the acoustic model. The unsupervised training of the vocoder allows it to learn to generate more natural-sounding waveforms without being biased by the training data.
Overall, Tortoise-TTS is a powerful and flexible TTS system that uses deep learning to synthesize high-quality, human-like speech from text inputs. Its modular architecture allows for easy customization and experimentation with different components, and its use of advanced deep learning techniques ensures that the synthesized speech is of the highest quality possible.[11]
5.6 Implementing Tortoise-TTS:
5.6.1 Theoretical Background:
Datasets with audio samples from only one speaker, commonly known as single-speaker datasets, such as LJSpeech, enable models to synthesize speech from a specific speaker. Conversely, multi-speaker datasets, such as LibriTTS, provide the capacity to learn to synthesize speech from multiple speakers. Depending on the learning strategy and architecture utilized, it's possible to synthesize speech from unheard speakers not included in the dataset, known as zero-shot learning. As it is aimed to examine the effectiveness of voice cloning without dedicating hours to recording voice.
-
Speaker encoder: The speaker encoder is a critical component in the process, aiming to generate a latent, fixed-dimensional embedding (vector) that captures diverse features of a specific human voice. It's desirable for the speaker encoder to be robust and unaffected by background noise or any other low-quality audio characteristics. The high-dimensional space should have similar human voice embeddings close together and very different ones far apart. Speaker encoders can be learned in various ways, some of which require transcripts for all audio samples, while others do not. Since using a transcript-dependent speaker encoder in subsequent zero-shot applications necessitates transcripts, it was intrigued by transcript-independent approaches. -
Synthesizer: Text-to-Speech (TTS) system comprises a synthesizer and a vocoder, mainly due to prior research emphasis on speech synthesis for a single speaker. However, to support multiple speakers, the synthesizer requires additional speaker information. One common approach in zero-shot learning is to utilize the embeddings produced by the speaker encoder for this purpose. Before discussing the synthesizer's role, it's essential to understand its function, which can be summarized as synthesizing a mel-spectrogram from a text transcript. While some models, like EfficientTTS or Char2Wav, are end-to-end trained, synthesizing a mel-spectrogram rather than a waveform format has advantages. The mel-spectrogram provides a speech representation requiring fewer dimensions, making it simpler to learn the projection from text to the mel-spectrogram for the synthesizer. Additionally, the mel-spectrogram considers that humans do not perceive audio frequencies linearly but logarithmically, making differences in lower frequency ranges more distinguishable than in higher frequencies, which is consistent with human hearing. As a result, separating speech synthesis into a synthesizer and a vocoder instead of end-to-end training appears to be yielding better outcomes. -
Vocoder: The vocoder is the last stage in the process and converts the synthesized mel-spectrogram into an audio waveform. WaveNet is the most widely used vocoder, known for its excellent speech quality and introduced by DeepMind in 2016. However, it's very slow during inference because it generates audio samples sequentially. WaveGlow and Clarinet are quicker alternatives. [12] -
Evaluation: In the field of text-to-speech synthesis, there is an interesting aspect related to model evaluation. The most common method to assess the quality of a text-to-speech model is through the mean opinion score (MOS), which involves rating synthesized and ground-truth audio samples on a scale of 1 to 5 based on speech quality. Although MOS is a reliable method, it can be time-consuming to evaluate MOS for every new text-to-speech model.
5.6.2 Fine-Tuning Tortoise-TTS Model:
In order to obtain the best and closest results to reality. Some basic problems that may be encountered in the process of cloning audio from a manually recorded database must be taken into account:
The speaker may be proficient in the target language but not a native speaker, resulting in less natural-sounding generated voice if overly eloquent.
When generating speech from written text, pauses that a person makes in natural speech must be taken into account, as they are important for breathing, organizing ideas, clarifying sentences, and other factors that contribute to naturalness and spontaneity in the generated sound. These factors should be considered in the training data to increase the naturalness and spontaneity of the generated sound.
When comparing the generated sound with the target sound, it is important to ensure that the tone, loudness, and other parameters are the same as those used by a bilingual person when speaking their native or second language.
It should be noted that the model used for training was previously trained on datasets of native speakers only.
5.6.3 Creating Audio Samples:
About fifteen minutes were recorded, divided into ten files in wav format and 22050 Hz frequency, which is recommended by the creators of the model.
The recorded files were graded starting from pronouncing the numbers from 1 to 10 and short sentences used in daily life and interactions between people, passing through more complex sentences such as talking about building a data set for the purpose of voice reproduction, ending with the scientific explanation of some terms in long sentences, taking into account pauses Take a breath or think before continuing.
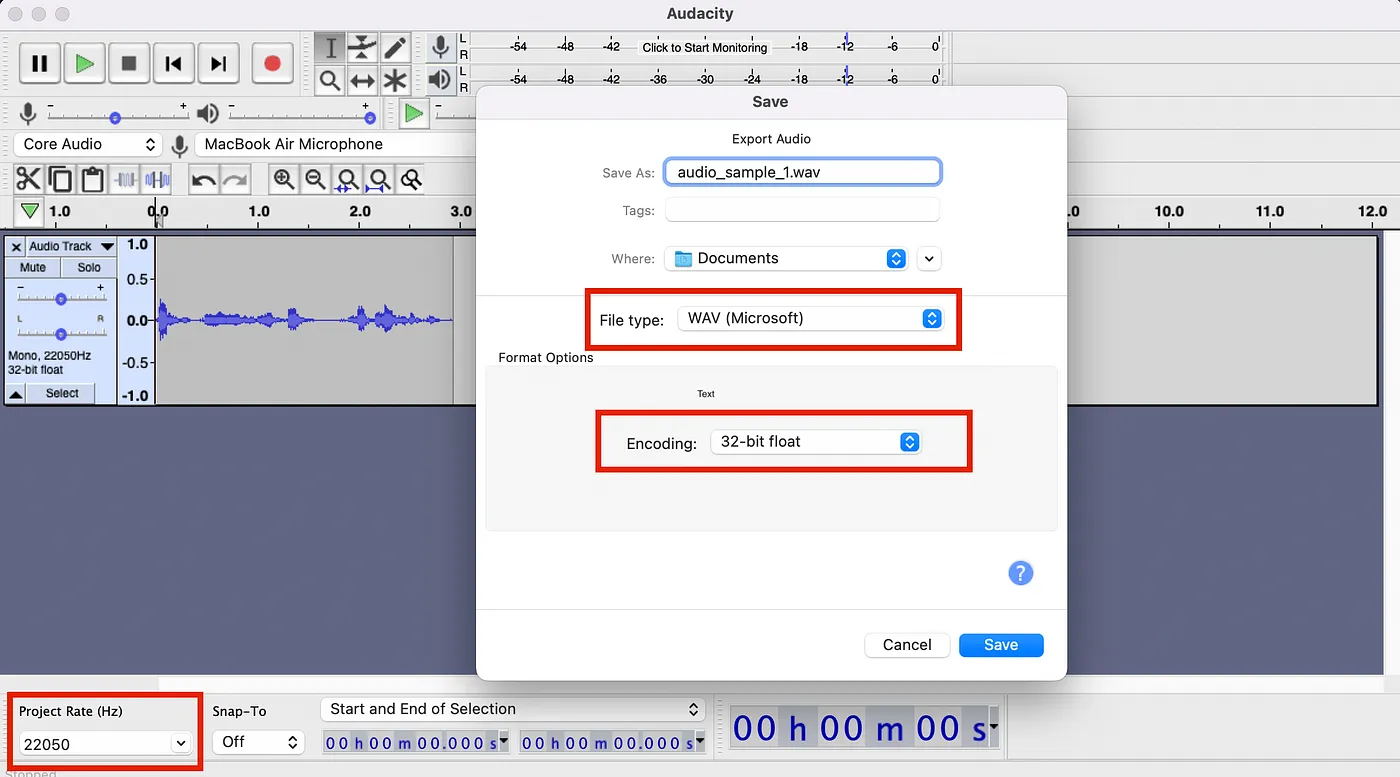
Figure 34: the program interface.
The voice dataset is recorded and processed in (Audacity).
The data set is named Ali (Targeted voice to clone) and followed with a serial number to indicate the level of complexity starting from 1 which is the most complex and longer in terms of time.
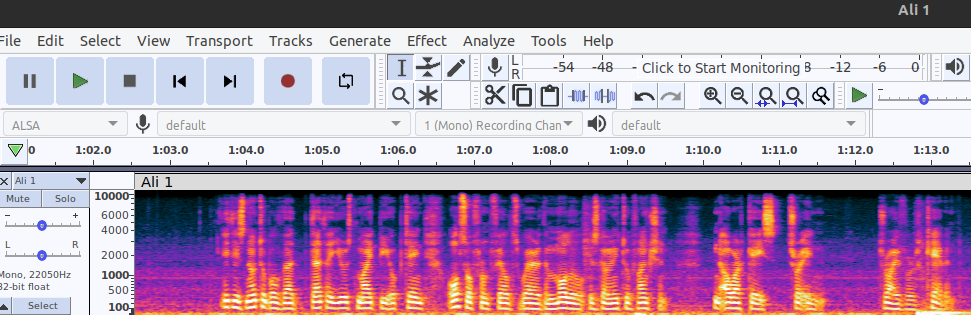


Figure 35: voice data in the form of spectrum.
As it is notable: the program represents the recorded wave form in spectrum form, and also can export the required data in the frequency and type, the implemented type is float 32 which stands for Single-precision floating-point format.
Note: Tortoise’s speaker encoder is not robust to background noise, and thus, it is a place of high impotency to clean the data from any unwanted background voices of any kind, and also empty seconds where there is no voice, which occurs is the beginning and the ending of voice records usually
5.6.4 Installing Tortoise-TTS:
In order of using this model or library, and with the aid of Colab, it is required to follow the following steps:
-
Downloading and installing the Tortoise-TTS model:
# the scipy version packaged with colab is not tolerant of misformated WAV files.
# install the latest version.
!pip3 install -U scipy
!git clone https://github.com/jnordberg/tortoise-tts.git
%cd tortoise-tts
!pip3 install -r requirements.txt
!pip3 install transformers==4.19.0 einops==0.5.0 rotary_embedding_torch==0.1.5 unidecode==1.3.5
!python3 setup.py install


Figure 36: the code implemented to set the Colab environment
-
Importing the required libraries and download the model from hugging-face server: -
import torch
import torchaudio
import torch.nn as nn
import torch.nn.functional as F
import IPython
from tortoise.api import TextToSpeech
from tortoise.utils.audio import load_audio, load_voice, load_voices
# This will download all the models used by Tortoise from the HuggingFace hub.
tts = TextToSpeech()

Figure 37: the code implemented to import required libraries.

-
Uploading audios samples:
CUSTOM_VOICE_NAME = "Ali"
import os
from google.colab import files
custom_voice_folder = f"tortoise/voices/{CUSTOM_VOICE_NAME}"
os.makedirs(custom_voice_folder)
for i, file_data in enumerate(files.upload().values()):
with open(os.path.join(custom_voice_folder, f'{i}.wav'), 'wb') as f:
f.write(file_data)

Figure 38: the code implemented to upload dataset.
After uploading audios samples, uploading the prompt is also required, in order of fine tuning the required audio speech without native speaker accent,
It is more effective to use some words that are included in the dataset, but the ratio must not exclude 20% in order of achieving real voice cloning.
-
The prompt used for this project is as the following:
“By understanding such thing, we can clearly say that the method we implemented in this process was a great success, Thus In order to create a truly comprehensive and representative dataset of spoken language, I recorded my own voice and created this dataset.”.
Note: the highlighted words are words included in the dataset.
Note: the highlighted words are used based on the high probability of responding to a certain accent, thus it is important to mention them in a foreign accent dialog.
-
Generating speech from the file
from tortoise.utils.text import split_and_recombine_text
from time import time
import os
outpath = "results/longform/"
textfile_path = "../Ali_prompt.text" # dir to text file
# Process text
with open(textfile_path, 'r', encoding='utf-8') as f:
text = ' '.join([l for l in f.readlines()])
if '|' in text:
print("Found the '|' character in your text, which I will use as a cue for where to split it up. If this was not"
"your intent, please remove all '|' characters from the input.")
texts = text.split('|')
else:
texts = split_and_recombine_text(text)
seed = int(time())
voice_outpath = os.path.join(outpath, CUSTOM_VOICE_NAME)
os.makedirs(voice_outpath, exist_ok=True)
voice_samples, conditioning_latents = load_voice(CUSTOM_VOICE_NAME)
all_parts = []
for j, text in enumerate(texts):
gen = tts.tts_with_preset(text, voice_samples=voice_samples, conditioning_latents=conditioning_latents,
preset="fast", k=1, use_deterministic_seed=seed)
gen = gen.squeeze(0).cpu()
torchaudio.save(os.path.join(voice_outpath, f'{j}.wav'), gen, 24000)
all_parts.append(gen)
full_audio = torch.cat(all_parts, dim=-1)
torchaudio.save(os.path.join(voice_outpath, 'combined.wav'), full_audio, 24000)
IPython.display.Audio(os.path.join(voice_outpath, 'combined.wav'))
