Файл: Направление подготовки 09. 03. 04 Программная инженерия.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 227
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
(таким образом мы добиваемся того, что данные находятся в промежутке [0;1], как и в случае изображений).
mel_spec = lsa.feature.melspectrogram(y,
sr=int(AudioHyperParams.SAMPLING_RATE), n_fft=int(AudioHyperParams.FRAME_SIZE), hop_length=int(AudioHyperParams.FRAME_SIZE / 4), n_mels=int(AudioHyperParams.NUMBER_OF_MEL_BANDS))
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram)
log_mel_spectrogram = (log_mel_spectrogram − log_mel_spectrogram.min())
/ (log_mel_spectrogram.max() − log_mel_spectrogram.min())
В режиме использования обрабатывающий компонент не обрабатывает аудиоинформацию, а передает матрицу (80, 430), заполненную нулями.
PyTorch имеет обширный набор функций для создания нейросетевых моделей. Опишем создание основных использованных слоев:
Двумерная свертка:
nn.Conv2d(in_channels=1,
out_channels=1, kernel_size=3
)
Одномерная свертка:
nn.Conv1d(in_channels=int(AudioHyperParams.EMBENDING_DIM), out_channels=125,
kernel_size=3
)
Использование двумерной свертки при работе с черно-белыми изображениями, которые по сути могут быть описаны матрицей, обусловлено спецификой работы одномерной свертки
- ядро движется только в одном направлении, то есть только вдоль входной матрицы - данный подход может быть применим к последовательностям, но не к изображениям, где нам важны пространственные характеристики.
При работе со слоями свертки мы отказались от субдискретизирующих слоев в пользу в пользу увеличения шага свертки (параметр strides).
Синоптические коэффициенты сверточных слоев инициализируются с помощью метода Хавьера, а начальные отклонения равняются одной сотой
Рекуррентный слой LSTM:
nn.LSTM(int(AudioHyperParams.MEL_SAMPLES), int(AudioHyperParams.EMBENDING_DIM), num_layers=2,
batch_first=True
)
Синоптические коэффициенты и начальные отклонения рекуррентных слоев инициали- зируются нулями.
В качестве методики обучения был выбран mini-batch. В классическом сценарии в одной итерации (предсказание модели и градиентный спуск) принимают участие шесть видеозапи- сей, данные из которых, проходя обработку, попадают в нейросетевой компонент.
Значение коэффициента α в функции ошибки генератора (2.3) в нашем случае было выбра- но как 100.
В качестве оптимизатора был выбран Adam. Adam — один из самых эффективных алго- ритмов оптимизации в обучении нейронных сетей [41]. Он сочетает в себе идеи RMSProp и оптимизатора импульса. Вместо того, чтобы адаптировать скорость обучения параметров на основе среднего первого момента (среднего значения), как в RMSProp, Adam также использует среднее значение вторых моментов градиентов. Используемые нами параметры оптимизато- ра: learning rate = 0.0002, β1 = 0.5, β2 = 0.999.
Реализация работы оптимизатора выполнялась с использованием фреймворка PyTorch.
generator = MainGenerator().to(device)
generator_optimizer = optim.Adam(generator.parameters(),
lr=TrainParams.LEARNING_RATE, betas=(TrainParams.BETA1, 0.999)
)
generator_loss = loss_from_D + TrainParams.ADDITIONAL_LOSS_COEFF * loss_from_mel generator_optimizer.zero_grad()
generator_loss.backward() generator_optimizer.step()
В данном разделе было описано построение модуля генерации аудиоинформации на осно- ве видеозаписи, а именно:
Как и для обучения модели, для экспериментальных исследований использовался набор данных AudioSet [35], который содержит различные видео, поделенные на классы. Нами был использован класс видеозаписей Hammer, на данных видео совершаются удары различными инструментами.

Рис. 4.1 – Пример кадров из использованных видео
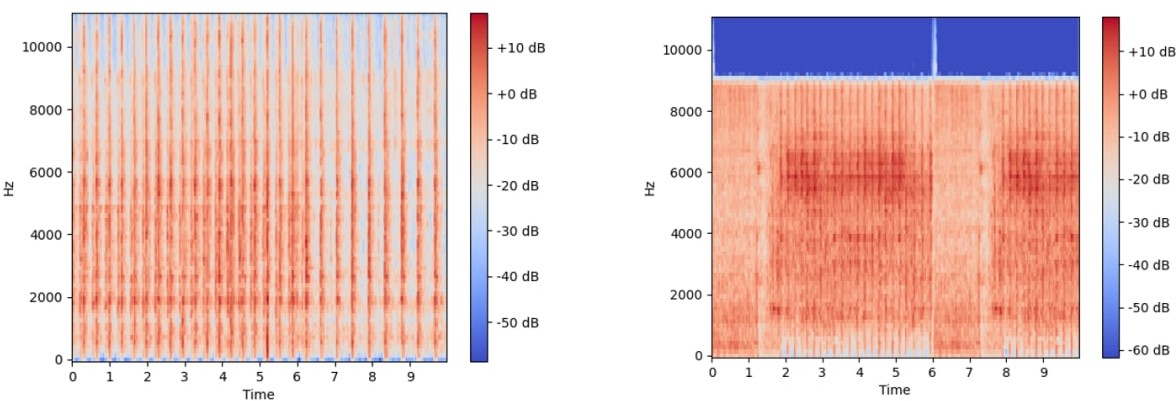
Рис. 4.2 – Пример мел-спектрограм из использованных видео
Модуль обучался на наборе данных, состоящих из 380 видео, изображения из видео мас- штабировались до размеров 512 на 215. Длительность обучения - 100 эпох, производилось на
GeForce RTX 3060 и заняло приблизительно 10
часов.
На рисунках ниже представлены оригинальные (снизу) и сгенерированные (сверху) спек- трограммы, соответствующие одному видео.
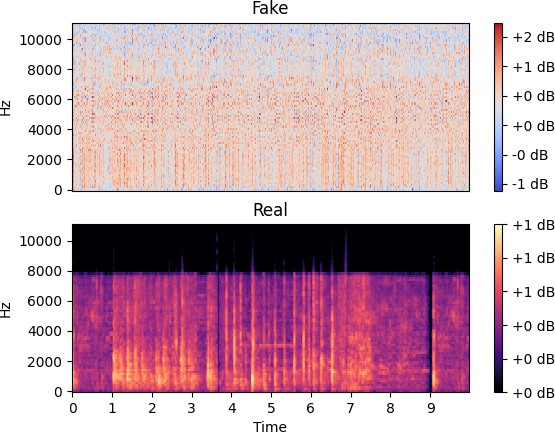
Рис. 4.3 – Первая эпоха обучения
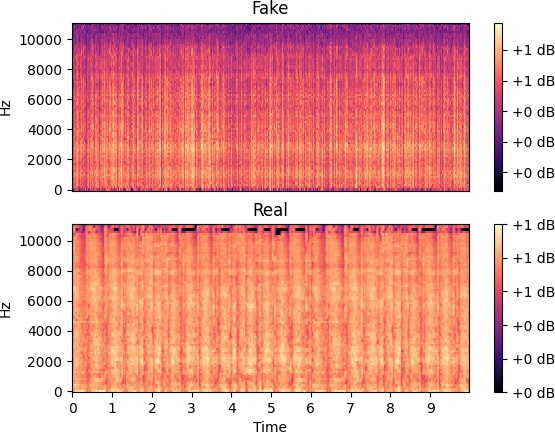
Рис. 4.4 – Вторая эпоха обучения
Сравнив результаты, изображенные на рисунках 4.3 и 4.4, можно сделать вывод, что гене-
ратор относительно быстро перешел от белого шума к более-менее правдоподобным данным. Подобная быстрая адаптация нейросетевой модели под необходимый формат данных, по на- шему мнению, обусловлено использованием не только BCE (2.1), но и MSE (2.2) в функции ошибки генератора (2.3).
Дальнейшее обучение привело к снижению влияния MSE и увеличению влияния оценки дискриминатора на обучение генератора. Следует упомянуть, что и дискриминатор на позд- них этапах обучения снизил собственную функцию ошибки (2.4) и стал эффективнее опреде- лять оригинальную спектрограмму от сгенерированной.
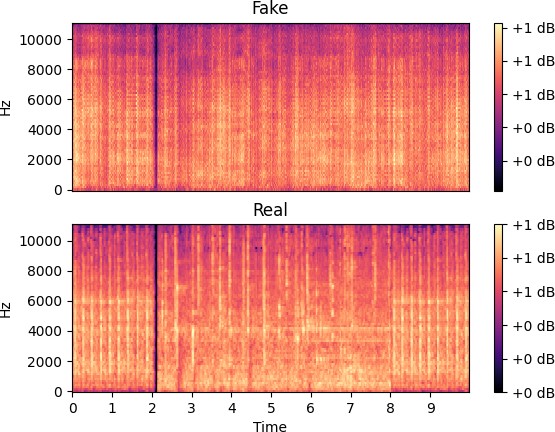
Рис. 4.5 – Девяносто восьмая эпоха обучения
Графики ошибок представлены на рисунках 4.6 и 4.7
После обучения было проведено экспериментальное исследования работы модуля. В каче- стве тестовой выборки было взято 40 видео из того же класса набора данных AudioSet. В режиме использования нейросетевой компонент в качестве входной мел-спектрограммы использует нули.
Исходя из рис. 4.8 и 4.9 можно сделать вывод
, что нейросетевой компонент эффективно обучился определять характеристики звука по видеоинформации. Стоит отметить, что задача генерации аудиоинформации только соответсвующей видео не решена до конца - модель ге- нерирует избыточное количества шума и не всегда создает необходимую периодичность сиг- налов.
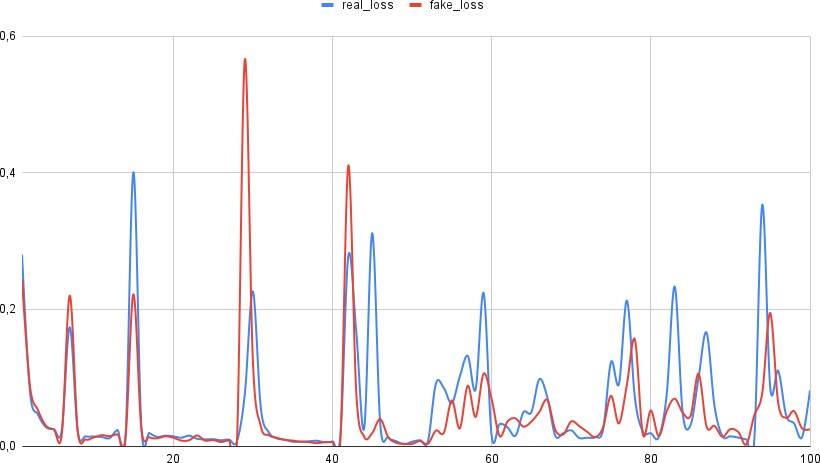
Рис. 4.6 – Средняя ошибка дискриминатора в зависимости от эпохи
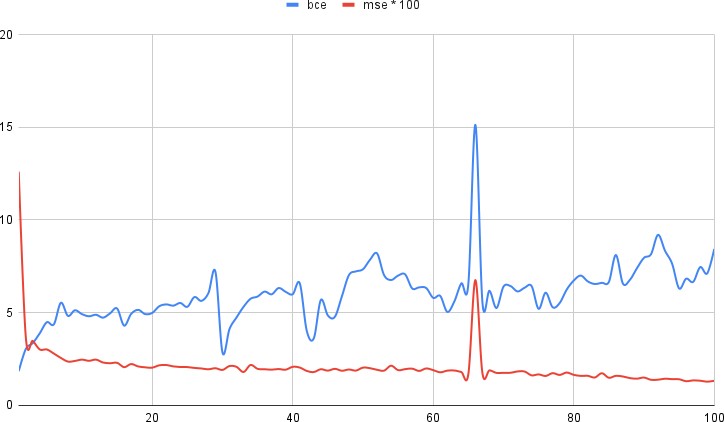
Рис. 4.7 – Средняя ошибка генератора в зависимости от эпохи
mel_spec = lsa.feature.melspectrogram(y,
sr=int(AudioHyperParams.SAMPLING_RATE), n_fft=int(AudioHyperParams.FRAME_SIZE), hop_length=int(AudioHyperParams.FRAME_SIZE / 4), n_mels=int(AudioHyperParams.NUMBER_OF_MEL_BANDS))
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram)
log_mel_spectrogram = (log_mel_spectrogram − log_mel_spectrogram.min())
/ (log_mel_spectrogram.max() − log_mel_spectrogram.min())
В режиме использования обрабатывающий компонент не обрабатывает аудиоинформацию, а передает матрицу (80, 430), заполненную нулями.
-
Нейросетевой компонент
PyTorch имеет обширный набор функций для создания нейросетевых моделей. Опишем создание основных использованных слоев:
Двумерная свертка:
nn.Conv2d(in_channels=1,
out_channels=1, kernel_size=3
)
Одномерная свертка:
nn.Conv1d(in_channels=int(AudioHyperParams.EMBENDING_DIM), out_channels=125,
kernel_size=3
)
Использование двумерной свертки при работе с черно-белыми изображениями, которые по сути могут быть описаны матрицей, обусловлено спецификой работы одномерной свертки
- ядро движется только в одном направлении, то есть только вдоль входной матрицы - данный подход может быть применим к последовательностям, но не к изображениям, где нам важны пространственные характеристики.
При работе со слоями свертки мы отказались от субдискретизирующих слоев в пользу в пользу увеличения шага свертки (параметр strides).
Синоптические коэффициенты сверточных слоев инициализируются с помощью метода Хавьера, а начальные отклонения равняются одной сотой
Рекуррентный слой LSTM:
nn.LSTM(int(AudioHyperParams.MEL_SAMPLES), int(AudioHyperParams.EMBENDING_DIM), num_layers=2,
batch_first=True
)
Синоптические коэффициенты и начальные отклонения рекуррентных слоев инициали- зируются нулями.
В качестве методики обучения был выбран mini-batch. В классическом сценарии в одной итерации (предсказание модели и градиентный спуск) принимают участие шесть видеозапи- сей, данные из которых, проходя обработку, попадают в нейросетевой компонент.
Значение коэффициента α в функции ошибки генератора (2.3) в нашем случае было выбра- но как 100.
В качестве оптимизатора был выбран Adam. Adam — один из самых эффективных алго- ритмов оптимизации в обучении нейронных сетей [41]. Он сочетает в себе идеи RMSProp и оптимизатора импульса. Вместо того, чтобы адаптировать скорость обучения параметров на основе среднего первого момента (среднего значения), как в RMSProp, Adam также использует среднее значение вторых моментов градиентов. Используемые нами параметры оптимизато- ра: learning rate = 0.0002, β1 = 0.5, β2 = 0.999.
Реализация работы оптимизатора выполнялась с использованием фреймворка PyTorch.
generator = MainGenerator().to(device)
generator_optimizer = optim.Adam(generator.parameters(),
lr=TrainParams.LEARNING_RATE, betas=(TrainParams.BETA1, 0.999)
)
generator_loss = loss_from_D + TrainParams.ADDITIONAL_LOSS_COEFF * loss_from_mel generator_optimizer.zero_grad()
generator_loss.backward() generator_optimizer.step()
- 1 ... 7 8 9 10 11 12 13 14 15
Выводы
В данном разделе было описано построение модуля генерации аудиоинформации на осно- ве видеозаписи, а именно:
-
Описаны требования к модулю. -
Выбор инструментальных средств: языка программирования, фреймворков и библиотек. -
Описана общая архитектуры модуля. -
Описана программная реализация модуля и этапы тестирования.
-
Экспериментальное исследование метода генерации аудиоинформации на основе видеозаписи
-
Набор данных для проведение экспериментальных исследований
Как и для обучения модели, для экспериментальных исследований использовался набор данных AudioSet [35], который содержит различные видео, поделенные на классы. Нами был использован класс видеозаписей Hammer, на данных видео совершаются удары различными инструментами.
Рис. 4.1 – Пример кадров из использованных видео
Рис. 4.2 – Пример мел-спектрограм из использованных видео
-
Экспериментальная оценка эффективности модуля метода генерации аудиоинформации на основе видеозаписи
Модуль обучался на наборе данных, состоящих из 380 видео, изображения из видео мас- штабировались до размеров 512 на 215. Длительность обучения - 100 эпох, производилось на
GeForce RTX 3060 и заняло приблизительно 10
часов.
На рисунках ниже представлены оригинальные (снизу) и сгенерированные (сверху) спек- трограммы, соответствующие одному видео.
Рис. 4.3 – Первая эпоха обучения
Рис. 4.4 – Вторая эпоха обучения
Сравнив результаты, изображенные на рисунках 4.3 и 4.4, можно сделать вывод, что гене-
ратор относительно быстро перешел от белого шума к более-менее правдоподобным данным. Подобная быстрая адаптация нейросетевой модели под необходимый формат данных, по на- шему мнению, обусловлено использованием не только BCE (2.1), но и MSE (2.2) в функции ошибки генератора (2.3).
Дальнейшее обучение привело к снижению влияния MSE и увеличению влияния оценки дискриминатора на обучение генератора. Следует упомянуть, что и дискриминатор на позд- них этапах обучения снизил собственную функцию ошибки (2.4) и стал эффективнее опреде- лять оригинальную спектрограмму от сгенерированной.
Рис. 4.5 – Девяносто восьмая эпоха обучения
Графики ошибок представлены на рисунках 4.6 и 4.7
После обучения было проведено экспериментальное исследования работы модуля. В каче- стве тестовой выборки было взято 40 видео из того же класса набора данных AudioSet. В режиме использования нейросетевой компонент в качестве входной мел-спектрограммы использует нули.
Исходя из рис. 4.8 и 4.9 можно сделать вывод
, что нейросетевой компонент эффективно обучился определять характеристики звука по видеоинформации. Стоит отметить, что задача генерации аудиоинформации только соответсвующей видео не решена до конца - модель ге- нерирует избыточное количества шума и не всегда создает необходимую периодичность сиг- налов.
Рис. 4.6 – Средняя ошибка дискриминатора в зависимости от эпохи
Рис. 4.7 – Средняя ошибка генератора в зависимости от эпохи
- 1 ... 7 8 9 10 11 12 13 14 15