Файл: Направление подготовки 09. 03. 04 Программная инженерия.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 214
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Последние слои СНС, представляющие собой комбинацию персептронов, формируются ис- ходя из решаемой задачи и желаемых выходных данных сети.
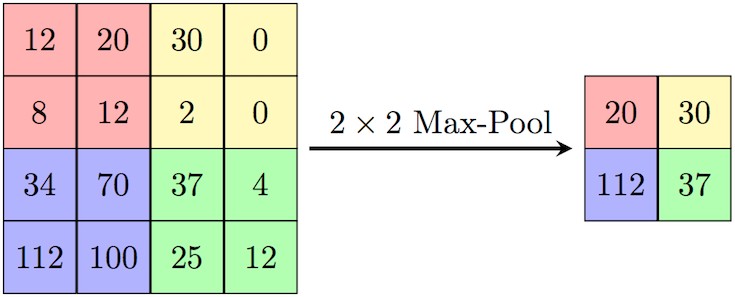
Рис. 1.2 – Выбор максимума из области размером 2 × 2 с шагом 2
Несмотря на то, что подобные методы чаще всего относят к направлению компьютерного зрения, операция свертки применима к любым типам данных, которые могут быть представ- лены в числовом виде, при этом сохраняя свои преимущества.
В контексте обработки звука применима ”одномерная” свертка, где ядро скользит только по направлению одной оси.
- 1 2 3 4 5 6 7 8 9 ... 15
Рекуррентные нейронные сети
Говоря о аудиовизуальной информации, мы имеем в виду последовательность данных (изоб- ражений в контексте видео и частот в случае аудио). Для обработки последовательностей при- менимы рекуррентные нейронные сети.
Рекуррентные нейронные сети (англ. Recurrent neural network; RNN) — вид нейронных се- тей, где связи между элементами образуют направленную последовательность. Благодаря это- му появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети мо- гут использовать свою внутреннюю память для обработки последовательностей произвольной длины [25].
На рис. 1.3 представлена последовательность процессов в рекуррентных нейронных сетях. Участок нейронной сети A получает некие данные xtна вход и подает на выход некоторое значение ht, при этом информация передается от одного шага к другому.
Классическая архитектура, подразумевающая использование функции tanhв элементе A, применима для малых последовательность, так как в случае относительно больших последо- вательностей данных необходимо хранить долгосрочную информацию - при использовании
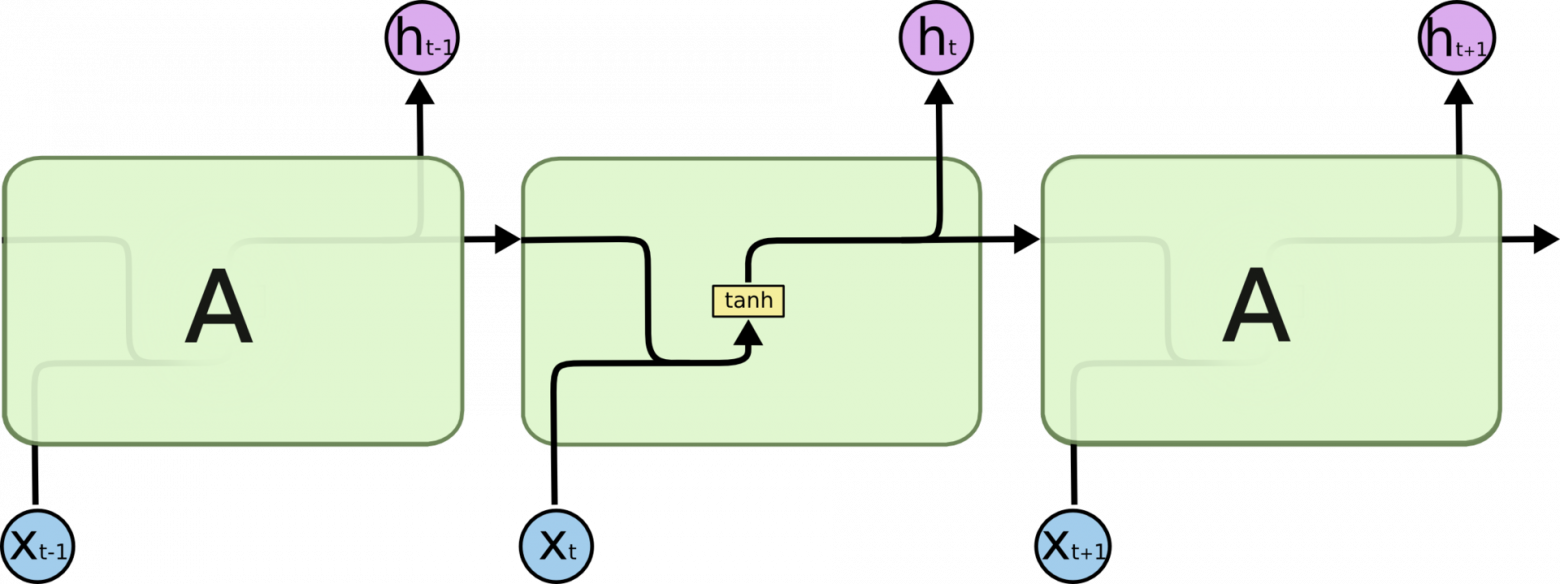
Рис. 1.3 – Рекуррентная нейронная сеть
классической рекуррентной сети долгосрочная информация должна последовательно пройти через все ячейки, прежде чем попасть в текущую обрабатываемую ячейку. Это означает, что ее можно легко повредить, многократно умножая на малые числа близкие к 0, что является причиной исчезновения градиента.
Для решения данной проблемы были
разработаны сети долгой краткосрочной памяти (ан- гл: Long short-term memory; LSTM) [26]. Архитектура данной сети изображена на рис. 1.4. В LSTM вводится ячейка C(рис. 1.5), отвечающая за хранение долгосрочной информации, и вли- яющей на итоговый результат работы сети. Для управления долгосрочной памятью вводится три фильтра: ”фильтр забывания”, определяющий, какую информацию можно убрать из состо- яния ячейки, ”входной фильтр”, определяющий, какую информацию следует добавить в ячей- ку и ”выходной фильтр”, определяющий выход сети на базе долгосрочной и краткосрочной памяти - все фильтры последовательно изображены на архитектуре сети в элементе A.
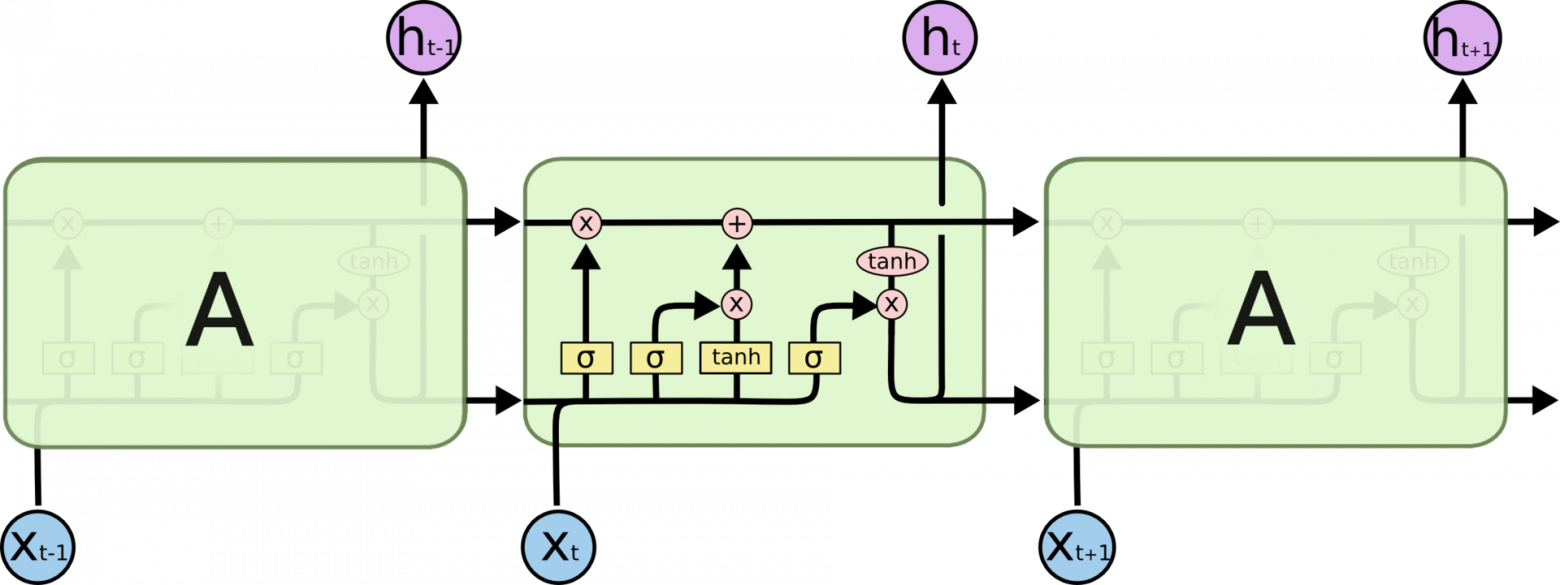
Рис. 1.4 – Cеть долгой краткосрочной памяти
Тем не менее, LSTM окончательно не решает проблемы долгосрочной памяти, и имеют ана- логичную проблему ”исчезающего градиента” [27], но способны эффективно обрабатывать го- раздо более большие последовательности данных, чем классические рекуррентные нейронные сети.
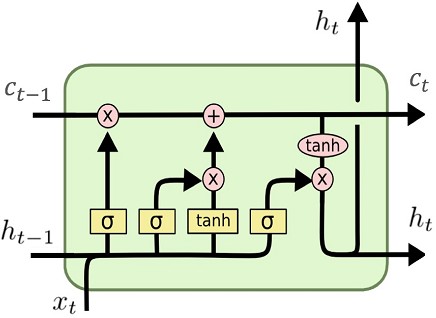
Рис. 1.5 – Элемент Aв сети долгой краткосрочной памяти
- 1 2 3 4 5 6 7 8 9 ... 15
Генеративно-состязательные нейронные сети
Генеративно-состязательные нейронные (англ. Generative adversarial network; GAN) сети бы- ли созданы для решения задач генерации данных наподобие других данных (сознательно не добиваясь точного совпадения) или для генерации данных на основе данных другого типа - это может быть, например, создание изображений, содержащих определенный объект [28], или создания изображений по текстовому описанию [29], или, в нашем случае, генерация звука из видео.
Идея генеративно-соcтязательных нейронных сетей заключается в использовании двух се- тей: генератора и дискриминатора [30]. Назначение дискриминатора - отличить оригинальные данные от ”подделки”, которую создает генератор. Сети обучаются одновременно - дискри- минатор стремится точнее отличать оригинальные данные от сгенерированных, а генератор ”обмануть” дискриминатор (рис. 1.6).
Архитектуры генератора и дискриминатора не имеют определенных ограничений и созда- ются для решений каждой отдельно взятой задачи.
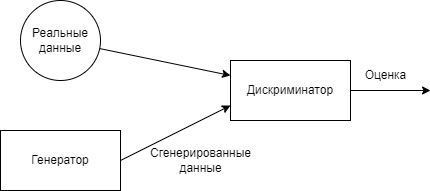
Рис. 1.6 – Архитектура GAN
-
Методы представления аудиоинформации
С точки зрения визуальной информации не возникает проблем при представлении в чис- ленном виде - каждый пиксель изображения кодируется при помощи набора чисел, определя- ющего его цвет.
Но, когда мы взаимодействуем с аудиоинформацией, нам необходимо выполнить ряд пре- образований для корректного представления в численном виде.
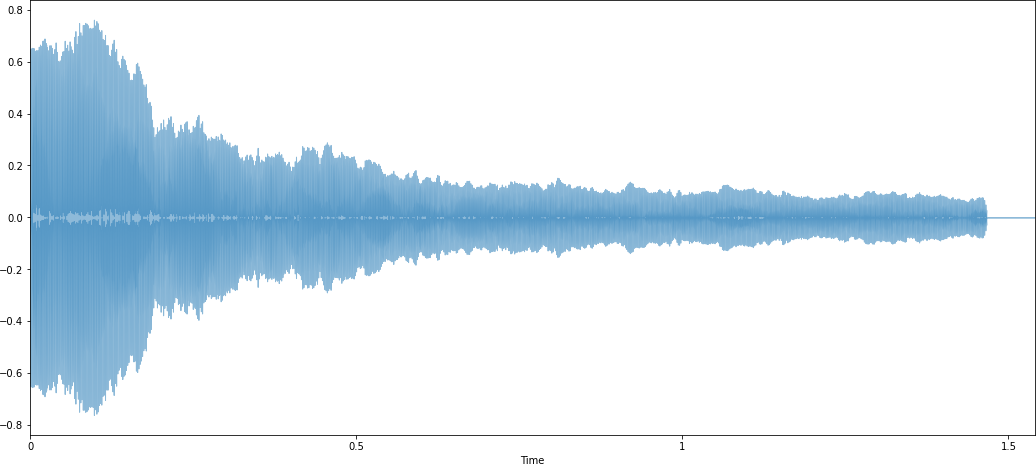
Рис. 1.7 – Аудиосигнал в виде зависимости интесивности от времени Изначально мы имеем представление о
зависимости интенсивности от времени, но по-
добное представление неэффективно для последующего анализа, в данном случае применимо преобразование Фурье [31].
где f- частота, t- время
gˆ(f) = ∫ g(t) exp−i2πftdt(1.4)
При помощи данного преобразование мы переходим от временной шкалы к шкале частот и получаем аудиосигнал в формате зависимости коэффициента Фурье от частоты, при это мо- дуль коэффициента Фурье является амплитудой - таким образом мы получаем данные о ча- стоте и амплитуде гармонических колебаний, из которых состоит изначальный сигнал [31].
Так как мы не можем работать с непрерывными числами, нам необходимо использовать дискретное преобразование Фурье, для этого будем считать, что сигнал имеет ненулевую ин- тенсивность на конечном промежутке времени и раздели данный промежуток на Nучастков:
xˆ(k) = ∑ x(n) exp−i2πn
N−1
kN
(1.5)
где k- частота
n=0
Изучив результаты применения дискретного преобразования Фурье (рис. 1.8), можно сде- лать вывод, что мы теряем информацию