Файл: Направление подготовки 09. 03. 04 Программная инженерия.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 228
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Пусть мы имеем видео I. Видео имеет вид тензора ранга 4 с размерами (T,H,W,3), где T- длительность видео, H- высота изображения, W- ширина изображения, 3 - отображает трехка- нальный способ кодирования цвета каждого пикселя изображения. Необходимым результатом является функция Φ : I→ M, где M - мел-спектрограмма, соответствующая видео I. мел- спектрограмма представляется в виде матрицы с размерами (B,F), где B - количество мел фильтров, F - количество временных окон.
Под мел-спектрограммой, соответствующей видео, мы понимаем мел-спектрограмму, опи- сывающую аудиосигнал, природа которого может быть подтверждена визуально (то есть собы- тие, которые вызвало данный звук, изображено на видео).
В качестве апроксиматора функции Φ может выступать нейронная сеть. Для её обучения будет использоваться визуальная и аудиоинформация из видео. Следует отметить, что посту- пающая аудиоинформация содержит Aˆ - аудиоинформация, не соответствующая видео, и A˜ -
аудиоинформация, соответствующая видео, при этом нейросетевая модель должна генериро- вать только A˜.
- 1 ... 4 5 6 7 8 9 10 11 ... 15
Нейросетевая модель генерации аудиоинформации на основе видеоин- формации
Для реализации поставленной задачи используется архитектура генеративно-состязательный нейронных сетей, то есть основными модулями будут выступать генератор - нейронная сеть, создающая мел-спектрограммы, и дискриминатор - нейронная сеть, оценивающая подлин- ность входной спектрограммы, и возвращающая оценку от нуля до единицы.
-
Тренировка и использование генератора
На этапе тренировки генератор использует видео- и аудиоинформацию, данный подход был выбран исходя из предположения, что для более эффективного сопоставления данных нейронная сеть должна анализировать оба источника информации одновременно.
Перед поступлением в генератор (или дискриминатор) данные проходят обработку в соот- ветствующих кодировщиках (тоже нейронные сети) AudioEncoder и VideoEncoder, и с исполь-
зованием генератора (или дискриминатора) декодируются в необходимый формат. Подобный подход к обработке данных изначально был представлен в архитектуре UNet и на практике доказал свою эффективность [38].
Ошибка для тренировки генератора (2.3) определяется путем комбинации оценки дискри- минатора (BCE 2.1) и расхождении сгенерированной и оригинальной спектрограммы (MSE 2.2). Данный подход был выбран исходя из гипотезы, что на начальных этапах мы будем получать большое расхождение сгенерированной и оригинальной спектрограммы, что побудит нейрон- ную сеть быстрее адаптировать под необходимый формат данных, а на поздних этапах обуче- ния главную роль будет играть оценка
дискриминатора, благодаря которой будут генериро- ваться более релевантные видео спектрограммы.
generator bce = −1 log(p) (2.1)
где p - оценка дискриминатора. В нашем случае бинарная кросс-энтропия принимает та- кой вид, потому что при тренировке генератора мы в качестве метки класса всегда передаем единицу (то есть мел-спектрограмма верна).
1 ∑
n
generator mse = (mi
n
i=1
где n- количество элементов в мел-спектрограмме.
— mˆ
i)2 (2.2)
generator loss = generator bce + α∗ generator mse (2.3)
где α - коэффициент, отвечающий за влияние среднего квадратичного отклонения в ошиб- ке генератора.
Полностью процесс тренировки генератора изображен на рисунке 2.1.
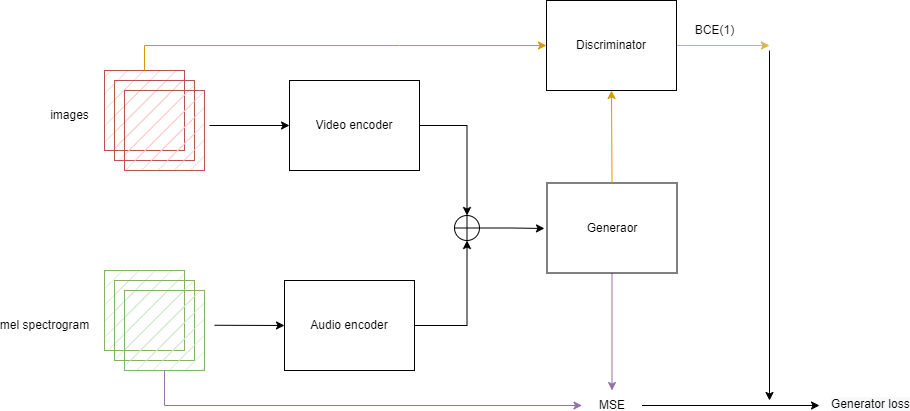
Рис. 2.1 – Процесс тренировки генератора
В процессе использование генератора вместо оригинальной мел-спектрограммы на вход будет подаваться матрица, соответствующая размерам оригинально спектрограммы, но состо- ящая из нулей.
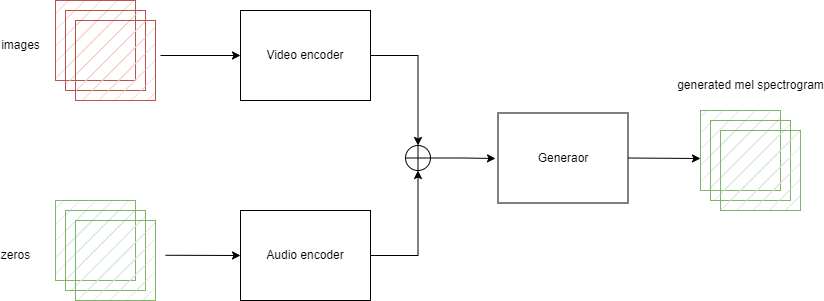
Рис. 2.2 – Процесс использования генератора
-
Тренировка и использование дискриминатора
Дискриминатор, аналогично генератору, на вход принимает видео- и аудиоинформацию, причем и в случае тренировки, и в случае использование.
На каждой итерации тренировки дискриминатору необходимо оценить оригинальную и поддельную мел-спектрограмму в комбинации
с оригинальным видео. Ошибка дискримина- тора (2.4) формируется путем комбинации его ошибок в случае определения оригинала и под- делки - таким образом мы стремимся ускорить тренировку дискриминатора в направлении двух решаемых им задач.
В данном случае ошибки считаются по классической формуле бинарной кросс-энтропии (2.5), где в одном случае в качестве метки выступает единица (спектрограмма подлинная) и ноль (спектрограмма поддельная).
Для создания поддельной спектрограммы мы используем наш генератор, таким образом придерживаясь оригинальной идеи генеративно-состязательных нейронных сетей о одновре- менной тренировке дискриминатора и генератора.
discriminator loss = fake bce + real bce (2.4)
bce = −y log(p) + (1 − y) log(1 − p) (2.5) где y - метка спектрограммы, p - оценка дискриминатора.
Процесс тренировки дискриминатора полностью изображен на рисунке 2.3.
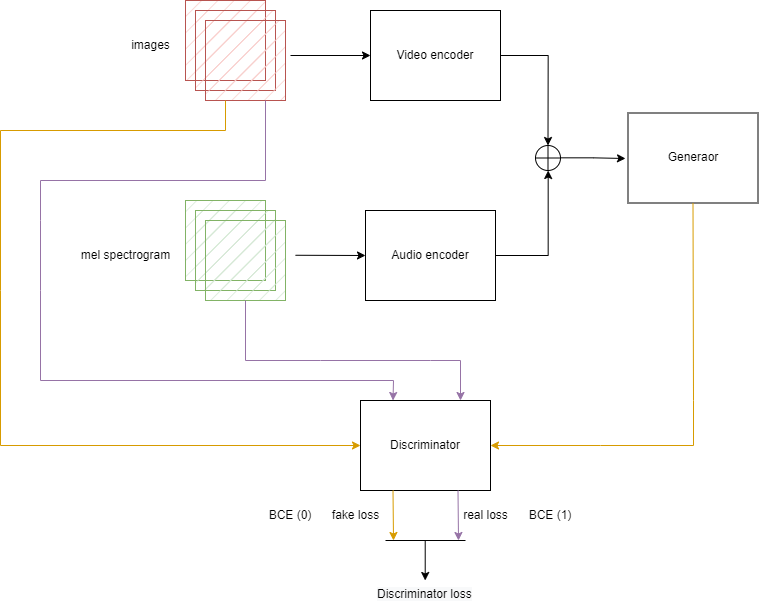
Рис. 2.3 – Процесс тренировки дискриминатора
- 1 ... 5 6 7 8 9 10 11 12 ... 15
Архитектура нейросетевых моделей используемых для генерации аудио- информации на основе видеоинформации
Основными моделями обработки данных являются кодировщики AudioEncoder и VideoEncoder, которые преобразуют входные данные в матрицы, в последствии используемые генератором.
-
VideoEncoder
VideoEncoder на вход принимает видео в формате последовательности изображений, каж- дое изображение обрабатывается слоями двумерной свертки в комбинации с LeakyReLU. Функ- ция активации ReLU представляет собой непрерывную функцию, состоящую из двух линейных сегментов (2.6). Её производная не непрерывна, но на практике это не создает проблемы. На самом деле, поскольку вычисление производной данной функции происходит немедленно, активация ReLU широко используется и позволяет процессам обучения сходиться значитель- но быстрее [39]. LeakyReLU (2.7) обладает теми же преимуществами, что и ReLU, но при этом избегает потерю информации.
ReLU(x) = x= 0,x≤ 0
(2.6)
x,otherwise
LeakyReLU(x) =
x,x≥ 0
(2.7)
negative slope × x,otherwise
где negative slope - угол наклона для отрицательных значений.
После преобразований изображение передается в рекуррентный слой. Таким образом, вход- ное изображение преобразуется в матрицу.
Архитектура VideoEncoder изображена на рисунке 2.4.
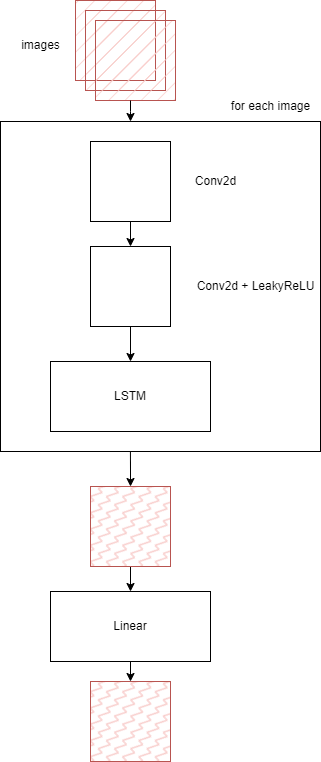
Рис. 2.4 – Архитектура VideoEncoder
-
AudioEncoder
AudioEncoder на вход принимает мел-спектрограмму, которая представляется из себя вре- менную последовательность. Последовательность целиком обрабатывается двумя рекуррент- ными слоями и проецируется. Результатом работы AudioEncoder является матрица, описыва- ющая аудиосоставляющую входного видео.
Архитектура VideoEncoder изображена на рисунке 2.5.