Файл: Направление подготовки 09. 03. 04 Программная инженерия.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 212
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
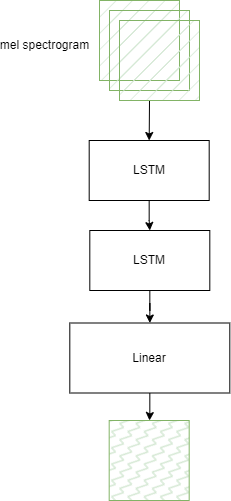
Рис. 2.5 – Архитектура AudioEncoder
В качестве рекуррентного слоя в обоих кодировщиках применяется LSTM, которая может эффективно применятся для обработки аудио- и видеоинформации [39; 40]. Возможность вос- принимать набор частей данных как единую последовательность в нашем случае (в случае VideoEncoder) реализуется при помощи переноса краткосрочной и долгосрочной памяти от одной итерации слоя к другой.
-
Дискриминатор
Дискриминатор в качестве входных принимает отдельно мел-спектрограмму и видео в фор- мате последовательности изображений. Видеоинформация имеет вид тензора ранга 4 и про- ходит обработку двумя слоями одномерной свертки в комбинации с ReLU; мел-спектрограмма обрабатывается одним слоем одномерной свертки. Полученные матрицы конкатенируются по принципу увеличения количества столбцов, и результат обрабатывается пятью слоями дву- мерной свертки в комбинации с ReLU.
Далее применяeтся слой Sigmoid (реализует логистическую функцию) - таким образом вы- ходными данными дискриминатора является число в диапазоне от нуля до единицы.
Архитектура дискриминатора изображена на рисунке 2.6.
-
Генератор
Генератор в качестве входных данных принимает конкатенацию матриц, построенных ко- дировщиками. Матрицы соединяются по принципу увеличения количества столбцов (рис. 2.7).
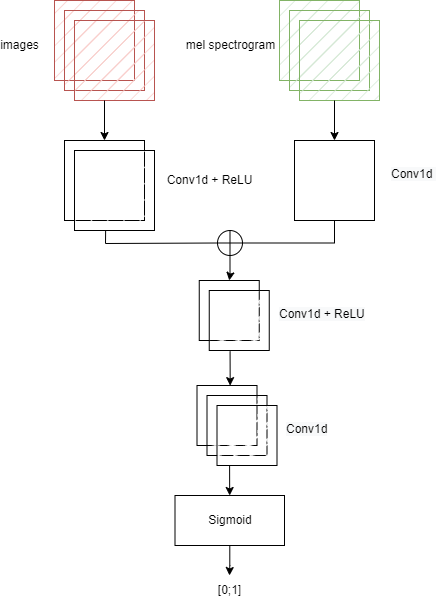
Рис. 2.6 – Архитектура дискриминатора
Она проходит обработку пятью слоями одномерной свертки (ядро движется в двумерном про- странстве) в комбинации с LeakyReLU (2.7) и BatchNorm (2.8). В итоге создается матрица, опи- сывающая мел-спектрограмму.
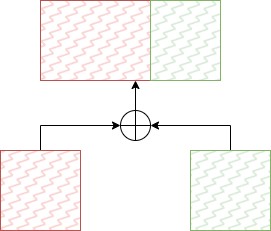
Рис. 2.7 – Конкатенация матриц
BatchNorm (2.8) осуществеляет нормализацию данных внутри нейронной сети путем све- дения математического ожидания к
нулю, а дисперсии к единице. Данный метод направлен на повышение производительности и стабилизацию работы нейросетевой модели.
√ (2.8)
x − E(x)
 BatchNorm(x) = Var(x)
BatchNorm(x) = Var(x)где E- математическое ожидание, Var - дисперсия. Архитектура генератора изображена на рисунке 2.8.
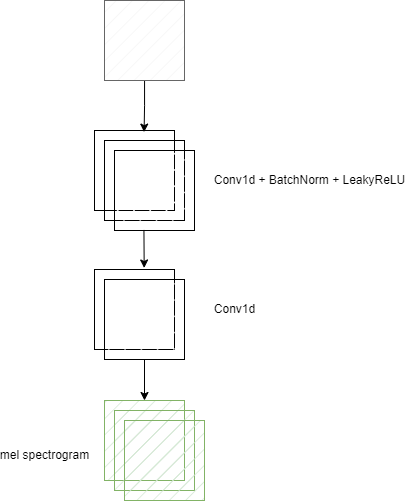
Рис. 2.8 – Архитектура генератора
- 1 ... 7 8 9 10 11 12 13 14 15
Выводы
В рамках данного раздела была описана теоретическая подготовка к построению программ- ного модуля генерации звука по видео, а именно:
-
Представлена нейросетевая модель генерации звука по видео. -
Описана архитектура реализуемых нейросетевых моделей.
-
Построение модуля генерации аудиоинформации на основе видеозаписи
-
Требования к модулю генерации аудиоинформации на основе видеоза- писи
Разрабатываемый модуль должен предоставлять набор методов для обработки видеозапи- сей. Входными данными для модуля является видео длительностью не более десяти секунд, содержащее или не содержащее звук, в формате mp4. Выходными данными является мел- спектрограмма в виде матрицы чисел с плавающей запятой, которая может быть выведена в консоль, записана в файл или изображена в виде спектрограммы.
Модуль должен иметь возможность быть запущен на операционных системах, использую- щий ядра Windows NT и UNIX. Для работы модуля предполагается наличие GPU, количество используемой модулей видеопамяти - не более 12 Гб.
-
Выбор инструментальных средств для разработки модуля генерации аудио- информации на основе видеозаписи
Для разработки модуля генерации аудиоинформации на основе видеозаписи в качестве основного языка программирования был выбран Python, в качестве альтернатив рассматрива- лись Matlab и С++. Python обладает рядом преимуществ: высокая скорость разработки, возмож- ность простой интеграции с клиент-серверными приложениями, большое количеством биб- лиотек, позволяющих высокоуровневое выполнения математических операций. На данный момент существует два основных фреймворка для работы с нейроннными сетями - PyTorch и TensorFlow от компании Google, оба из них опираются на понятия тензоров и графов
, по которым данные тензоры ”перемещаются”. Фреймворк PyTorch является более удобным при кроссплатформенном использовании, а также является более эффективным (с точки зрения скорости проведения вычислений) и в процессе тренировки, и в процессе инференса при ис- пользовании GPU. Таким образом, для разработки данного модуля был выбран PyTorch.
Все математические операции с тензорами выполняются с помощью математического ап- парата PyTorch. Вычисления за пределами модели предполагается выполнять при помощи библиотеки NumPy, реализующей комплексные математические функции, генераторы случай- ных чисел, процедуры линейной алгебры, преобразования Фурье и многое другое. Для обра-
ботки аудиоинформации была использована библиотека librosa. Для предобработки видео и визуальной информации был использован набор библиотек FFmpeg и библиотека алгоритмов компьютерного зрения OpenCV.
-
Реализация программного модуля генерации аудиоинформации на ос- нове видеозаписи
В модуле определены два компоненты - нейросетевой и обрабатывающий. Первый из них выполняет функции генерации мел-спектрограмм. Обрабатывающий - реализует обработку входных данных в формат, необходимый для нейросетевого компонента.

Рис. 3.1 – Взаимодействие компонентов
-
Обрабатывающий компонент
Задача обрабатывающего компонента состоит в том, чтобы преобразовать видео в формат данных принимаемый нейросетевым компонентов во время обучения или использования.
При помощи набора библиотек FFmpeg видео, если данные нужны для тренировки нейро- сетевого компонента,
приводится к длительности десять секунд путем повторения и обрезки. Далее разделяются на аудио- и видеоинформацию, видеоинформация преобразуется путем из- менения частоты кадров (21.5 fps), частота дискретизации аудиоинформации конвертируется в значение 220500.
# change audio sample rate
sr_audio_dir = P.join(output_dir, f”audio_{duration_target}s_{sr}hz”) os.makedirs(sr_audio_dir, exist_ok=True)
os.system(”ffmpeg −i {} −loglevel error −ac 1 −ab 16k −ar {} −y {}”.format( P.join(cut_audio_dir, audio_name), sr, P.join(sr_audio_dir, audio_name)))
# change video fps
fps_audio_dir = P.join(output_dir, f”videos_{duration_target}s_{fps}fps”) os.makedirs(fps_audio_dir, exist_ok=True)
os.system(”ffmpeg −y −i {} −loglevel error −r {} −c:v libx264 −strict −2 {}”.format( P.join(cut_video_dir, video_name), fps, P.join(fps_audio_dir, video_name)))
При помощи библиотеки OpenCV конвертированное видео разделяется на кадры, так как длительность видео и частота кадров фиксирована, то для каждого видео мы получаем одина- ковое количество кадров - 215. Каждый кадр подвергается изменению размеров и конвертиру- ется в черно-белый формат.
while video.isOpened(): reg, img = video.read() if not reg:
break
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) img = cv2.resize(img, (width, height))
cv2.imwrite(P.join(save_dir, f”img_{num:05d}.jpg”), img)
При помощи библиотеки librosa аудиоинформация конвертируется в мел-спектрограмму. Выбранные нами параметры конвертации: размер окна - 2048, размер пересечения окон - 512 (применяются для оконного преобразования Фурье), количество мел-фильтров - 80. Так как частота дискретизации и длительность аудиоинформации фиксирована, мы получаем мел- спектрограммы одинакового формата в виде матрицы (80, 430). Полученные мел-спектрограммы нормализуются методом минимакс