ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 11.04.2024
Просмотров: 177
Скачиваний: 0
СОДЕРЖАНИЕ
Тема 1. Предпосылки использования информационных технологий в управлении.
Тема 2. Информационные технологии как необходимое условие менеджмента
Тема 3. Информационные технологии на этапе принятия решений
Тема 4. Управляющие информационные системы и системы поддержки принятия решений.
Тема 5. Использование информационных технологий в стратегическом управлении
Тема 6. Использование информационных технологий в финансовом управлении
Тема 7. Использование информационных технологий в проектном управлении
•Объединение плохо совместимого. Например, не следует объединять в программах типа "Торговый дом" бухгалтерский и управленческий учет в рамках одной технологии разработки. Это будет долгий и трудный процесс, поскольку подходы к моделированию и проектированию этих частей существенно различаются. Реализовать их по отдельности и проще, и быстрее. Однако есть и другие примеры, когда для разработки используются концепции более высокого уровня абстракции. Удачны, например, решения в Baan или ROSS system, при разработке которых была отработана методология слияния транзакционной и аналитической частей в рамках единой КИС. Зато они и стоят дорого.
•Корректность его данных, полученных из разных источников. Данные перед загрузкой в хранилище должны быть либо "очищены от шума", либо обработаны методами нечеткой логики, допускающей наличие противоречивых фактов. Например, данные о предприятии-партнере могут быть получены от разных экспертов, чьи оценки порой бывают диаметрально противоположными.
Распределенные информационные ресурсы
Концепия хранилищ данных позволяет достаточно успешно решать проблемы интеграции распределенных информационных ресурсов в пределах одного предприятия. Но развитие интернет технологий поставило задачу нтеграции информацинных ресурос и создания распределенных баз данных более остро.
Одна из главных особенностей современных информационных систем - распределенный характер, информационные системы охватывают все более количество структурных единиц. Примером распределенной системы может послужить система резервирования билетов крупной авиакомпании, имеющей свои филиалы в различных частях Земли.
Главная проблема таких систем - организация обработки распределенных данных.
Данные находятся на компьютерах различных моделей и производителей, функционирующих под управлением различных операционных систем, а доступ к данным осуществляется разнородным программным обеспечением. Сами компьютеры территориально удалены друг от друга и находятся в различных географических точках планеты.
Ответом на задачи реальной жизни стали две технологии: технология распределенных баз данных (Distributed Database) и технология тиражирования данных (Data Replication).
Под распределенной базой данных подразумевают базу, включающую фрагменты из нескольких баз данных, которые располагаются на различных узлах сети компьютеров, и, возможно, управляются различными СУБД. Распределенная база данных выглядит с точки зрения пользователей и прикладных программ как обычная локальная база. В этом смысле слово "распределенная" отражает способ организации базы данных, но не внешнюю ее характеристику ("распределенность" базы не должна быть видна извне).
В отличие от распределенных баз, тиражирование данных предполагает отказ от их физического распределения и опирается на идею дублирования данных в различных узлах сети компьютеров. Ниже будут изложены детали, преимущества и недостатки каждой технологии.
Тема 3. Информационные технологии на этапе принятия решений
Выявление альтернатив для принятия управленческого решения - технологии OLAP и Data Mining. Интеллектуальный анализ данных. Визуализация данных. Тематические цифровые карты. Оценка альтернатив –сценарное моделирование «что-если».
Избыток информации вреден.
Ранее мы рассмотрели технологии, которые позволяют накапливать и обрабатывать большие объемы информации. При этом выявилась следующая проблема: чрезмерное количество данных в виде обширных таблиц затрудняет принятие управленческого решения –особенностью человеческого мышления является то, что для принятия решения человеку нужна компактная, сжатая информация, лучше в графическом виде. Стали возникать различные способы решения проблемы сжатия данных.
Практика использования и внедрения хранилищ данных показала, что анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами:
•разрозненностью данных, хранением их в форматах различных СУБД и в разных "уголках" корпоративной сети,
•даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), руководитель (аналитик) почти наверняка не разберется в их сложных, подчас запутанных структурах.
•задача технологии OLAP - предоставить "сырье" для анализа в одном месте и в простой, понятной структуре
•появление отдельного хранилища целесообразно потому, что сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Концепция OLAP
Централизация и удобное структурирование - это далеко не все, что нужно руководителю (аналитику). Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного - гибкости. Их нельзя "покрутить", "развернуть" или "свернуть", чтобы получить желаемое представление данных.
Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро - скажем, в течение часа (пишу и сам не верю - так быстро в жизни не бывает; давайте дадим ему часа три).
Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше "срезов" и "разрезов" данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых "срезов". Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP. OLAP - это Online Analytical Processing, т. е. оперативный анализ данных.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
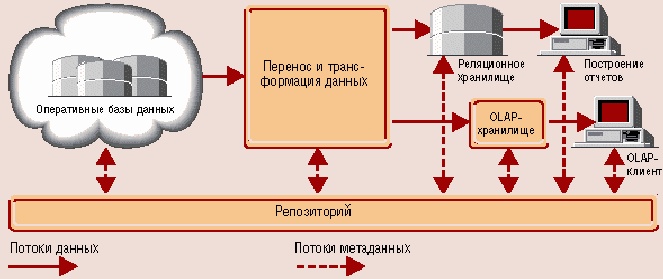
Рис. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Логическая структура OLAP данных
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации.
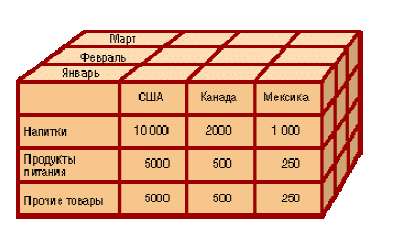
Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей - измерений (Dimensions) - находятся данные, количественно характеризующие процесс - меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п.
Пользователь, анализирующий информацию, может "разрезать" куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рисунке, использованы суммы продаж, а в качестве измерений - время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины - по странам, а данные о времени совершения операций - по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.
Пример куба
"Разрезание" куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех?
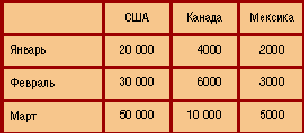
Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов. Двумерное представление куба можно получить, "разрезав" его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, - и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) - другое, а в ячейках таблицы - значения мер. При этом набор мер фактически рассматривается как одно из измерений - мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую - значения единственного "неразрезанного" измерения).
На первом рисунке изображен двумерный срез куба для одной меры - Unit Sales (продано штук) и двух "неразрезанных" измерений - Store (Магазин) и Время (Time).
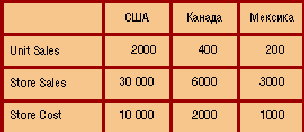
На следующем представлено лишь одно "неразрезанное" измерение - Store, но зато здесь отображаются значения нескольких мер - Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина). Двумерное представление куба возможно и тогда, когда "неразрезанными" остаются и более двух измерений.

При этом на осях среза (строках и столбцах) будут размещены два или более измерений "разрезаемого" куба.
Значения, "откладываемые" вдоль измерений, называются членами или метками (members). Метки используются как для "разрезания" куба, так и для ограничения (фильтрации) выбираемых данных - когда в измерении, остающемся "неразрезанным", нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется. Многомерность в OLAP-приложениях может быть разделена на три уровня: