Файл: Исследование методов и средств моделирования систем управления проектами на предприятии.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 24.10.2023
Просмотров: 413
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Глава 1 АНАЛИЗ СИСТЕМЫ УПРАВЛЕНИЯ ПРОЕКТАМИ
Модели жизненных циклов проектов и методы управления проектами
Анализ инструментов управления проектами
Организация процесса исследовательской деятельности на предприятии ООО «Мастер Маинд Инк»
Модель системы управления проектами «As Is»
стратегию компании или будущий программный продукт предназначен для решения разовой проблемы. Также необходимо ответить на вопросы: планируется ли публикация результатов исследования по этому вопросу в академических изданиях; планирует ли исследователь стать экспертом команды по этой теме и т. п.
Например, проект предназначен для того, чтобы помочь отделу продажлучше прогнозировать отток клиентов и убытки от оттока. Для решенияпоставленной задачи требуется хорошее знание теории случайных процессов,на которойстроятсямногиеобщиерешенияподобныхпроблем.
Необходимая глубина понимания зависит от технических аспектов проблемы. Некоторые из аспектов могут быть предвидены заранее, а некоторые обнаружены только позже.
Например, если разрабатываемый продукт должен быть интегрирован вготовуюпрограммнуюсреду,написаннуюнаязыкахJavaиScala,топриходится использовать те технологии, которые применяются в готовомпродукте. И если разработчики не владеют этими языками, то их придетсяизучить.
При изучении литературы специалист Data Science должен подготовить для обсуждения в команде не только выбранные варианты решения проблемы, но сделать краткий обзор всей области и всех рассмотренных решений, объясняя преимущества и недостатки каждого решения и обосновать свой выбор.
После того, как найден подходящий математический аппарат, найденные направления решений необходимо оценить с точки зрения способа реализации и сложности этого способа в производстве.
Цели продукта и бизнес-требования к нему, а также
структура и характеристики предлагаемых вариантов решений служат обоснованием для выбора способа хранения и обработки данных, способность к масштабированию по горизонтали и вертикали (scalability) и приблизительную оценку стоимости проекта.
Это важная проверка, которую необходимо выполнить на этом этапе, поскольку обработка данных и разработка программного обеспечения могут начинаться параллельно с разработкой модели. Кроме того, предлагаемое решение может оказаться неадекватным или слишком дорогостоящим с технической точки зрения, и в этом случае это должно быть выявлено и устранено как можно скорее. Когда технические вопросы рассматриваются до начала разработки модели, знания, полученные на этапе исследования, могут затем использоваться для предложения альтернативного решения, которое могло бы лучше соответствовать техническим ограничениям. Это еще одна причина, по которой этап исследования должен закончиться выработкой спектра решений, а не ограничиваться одним.
Подготовка данных и выбор решения (синий и желтый цвет на рисунках 2.2, 2.3, 2.5);
На этом этапе проектная команда определяет набор данных, которые потребуются в дальнейшем для обучения нейронных сетей; сбор первичных данных, обработка их (очистка от мусорной информации), преобразование в требуемый формат. Хранятся подготовленные данные вместе с запросами в базах данных компании.
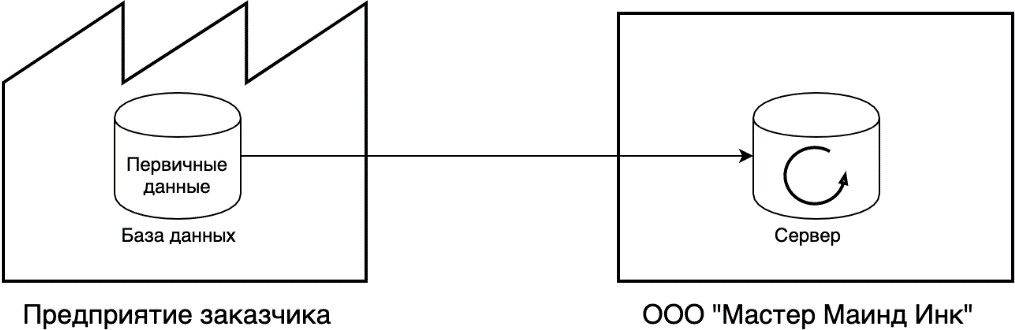
Рисунок 2.6 – Схема взаимодействия баз данных
Процесс подготовки данных часто сопровождается выгрузкой больших массивов данных (Big Data) из баз данных заказчика на сервер компании (если
позволяют условия конфиденциальности). В дальнейшем происходит обработка Big Data в формат, удобный для быстрых запросов и сложных вычислений. Эти действия необходимы для начала процесса исследования данных и иногда занимают больше времени, чем ожидалось.
Далее начинается процесс исследования данных.
Теперь специалист Data Science может оперировать фактическими жесткими KPI и показателями модели.
Однако и здесь надо соблюдать динамическое равновесие между исследованием и разработкой; даже имея в виду четкие KPI, полезно не терять из виду некоторые, казалось бы, неподходящие направления решения.
Обработанные данные должны иметь формат, удобный для работы отдела Data Engineering. Однако могут быть выявлены некоторые недостатки сформированного рабочего массива данных (например, данных,
предоставленных заказчиком, может оказаться недостаточно). Data Engineer данных должен быть готов к такой ситуации, и искать дополнительный источник данных.
Следует заметить, что, хоть процесс подготовки данных и выглядит отделенным от процесса теоретического исследования и анализа вариантов решений, они обычно либо выполняются параллельно, либо чередуются между собой.
Подготовка к моделированию (зеленый цвет на рисунках 2.2, 2.3, 2.5).
Подготовка к началу разработки модели в значительной степени зависит от имеющегося технического обеспечения и объема технической поддержки, доступной Data Scientist. Возможно, что Data Scientist создаст новый репозиторий кода и запустит локальный сервер Jupyter Notebook или запросит
более мощную облачную машину для выполнения вычислений.
Также может быть, что сотрудники отдела Data Scienсе создадут код для управления версиями данных и моделей или для отслеживания и управления экспериментом. Возможно, что такая функциональность уже существует в используемых сервисах, то тогда потребуется создание некоторых настроек для распределения ресурсов или настройки пользовательских пакетов и т. д.
Этот этап связан не только с технической подготовкой, но и подготовкой ‘features’ и параметров для будущей нейросети.
Разработка и обучение модели (красный цвет на рисунках 2.2, 2.3, 2.5). Задачами этого этапа являются развертывание модели, обучение (Machine
Learning) и непрерывный мониторинг результатов обучения.
В подготовленной на предыдущем этапе среде с выбранными параметрами создается модель нейросети. Специалисты отдела Data Engineering передают в отдел Data Science наборы данных и созданные к ним запросы, подготовленные в соответствии с набором ‘features’. Отдел Data Science загружает эти данные в обучающую среду, которая использует эти данные для обучения модели. Специалисты отдела Data science осуществляют мониторинг
результатов обучения, используя функциональность сервисов. После того, как модель считается обученной, можно переходить к модельному тесту.
При разработке и обучении модели различные ее версии (и обслуживающий массив данных) должны постоянно проверяться на соответствие заранее установленным KPI.
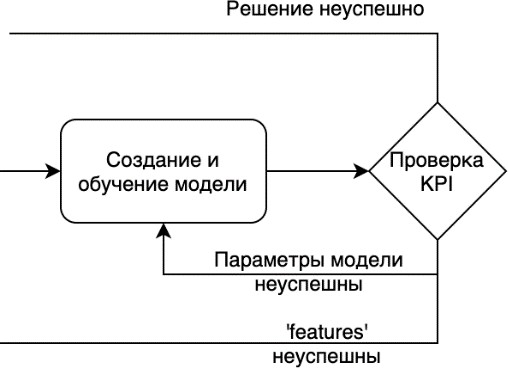 Это дает возможность оценить степень продвижения в обучении, а также позволяет отделу Data Science решить, когда модель работает достаточно хорошо, чтобы гарантировать
Это дает возможность оценить степень продвижения в обучении, а также позволяет отделу Data Science решить, когда модель работает достаточно хорошо, чтобы гарантировать
полное соответствие выработанным на начальном этапе KPI.
Рисунок 2.7 - Алгоритм принятия решения об успешности модели Если результаты обучения модели не соответствуют ожидаемым
показателям, то существует несколько причин такого исхода.
Специалист отдела Data Science анализирует результаты обучения нейронной сети и принимает решение о дальнейших действиях: изменить параметры, изменить «features», или данный вариант модели не пригоден для решения задачи и надо переходить к выбору следующего варианта модели.
Другим возможным результатом неудачного обучения является пересмотр цели продукта. В редких случаях изменение цели влечет за собой незначительные изменения в технической реализации проекта. Но в общем, это означает, что мы возвращаемся на фазу анализа предметной области.
 Не исключен наиболее экстремальный вариант - отмена проекта; если специалист по данным уверен, что все направления исследований были
Не исключен наиболее экстремальный вариант - отмена проекта; если специалист по данным уверен, что все направления исследований были
изучены, а проектный менеджер уверен, что продукт исчерпал свой потенциал, возможно, пришло время перейти к другому проекту.
Если обучение модели прошло успешно и она реализует заданные KPI, то этап R&D можно считать успешно законченным и переходить в разработке алгоритмической части конечного продукта, а также созданию интерфейса пользователя.
В ситуациях, когда расхождение между полученными и заданными значениями KPI не является критичным, требуется более тщательный их пересмотр и согласование с Product Owner.
Необходимо убедиться, что текущее значение показателя находится в интервале приемлемого разброса. При этом необходимо учитывать требования к продукту и интересы
Например, проект предназначен для того, чтобы помочь отделу продажлучше прогнозировать отток клиентов и убытки от оттока. Для решенияпоставленной задачи требуется хорошее знание теории случайных процессов,на которойстроятсямногиеобщиерешенияподобныхпроблем.
Необходимая глубина понимания зависит от технических аспектов проблемы. Некоторые из аспектов могут быть предвидены заранее, а некоторые обнаружены только позже.
Например, если разрабатываемый продукт должен быть интегрирован вготовуюпрограммнуюсреду,написаннуюнаязыкахJavaиScala,топриходится использовать те технологии, которые применяются в готовомпродукте. И если разработчики не владеют этими языками, то их придетсяизучить.
При изучении литературы специалист Data Science должен подготовить для обсуждения в команде не только выбранные варианты решения проблемы, но сделать краткий обзор всей области и всех рассмотренных решений, объясняя преимущества и недостатки каждого решения и обосновать свой выбор.
После того, как найден подходящий математический аппарат, найденные направления решений необходимо оценить с точки зрения способа реализации и сложности этого способа в производстве.
Цели продукта и бизнес-требования к нему, а также
структура и характеристики предлагаемых вариантов решений служат обоснованием для выбора способа хранения и обработки данных, способность к масштабированию по горизонтали и вертикали (scalability) и приблизительную оценку стоимости проекта.
Это важная проверка, которую необходимо выполнить на этом этапе, поскольку обработка данных и разработка программного обеспечения могут начинаться параллельно с разработкой модели. Кроме того, предлагаемое решение может оказаться неадекватным или слишком дорогостоящим с технической точки зрения, и в этом случае это должно быть выявлено и устранено как можно скорее. Когда технические вопросы рассматриваются до начала разработки модели, знания, полученные на этапе исследования, могут затем использоваться для предложения альтернативного решения, которое могло бы лучше соответствовать техническим ограничениям. Это еще одна причина, по которой этап исследования должен закончиться выработкой спектра решений, а не ограничиваться одним.
Подготовка данных и выбор решения (синий и желтый цвет на рисунках 2.2, 2.3, 2.5);
На этом этапе проектная команда определяет набор данных, которые потребуются в дальнейшем для обучения нейронных сетей; сбор первичных данных, обработка их (очистка от мусорной информации), преобразование в требуемый формат. Хранятся подготовленные данные вместе с запросами в базах данных компании.
Рисунок 2.6 – Схема взаимодействия баз данных
Процесс подготовки данных часто сопровождается выгрузкой больших массивов данных (Big Data) из баз данных заказчика на сервер компании (если
позволяют условия конфиденциальности). В дальнейшем происходит обработка Big Data в формат, удобный для быстрых запросов и сложных вычислений. Эти действия необходимы для начала процесса исследования данных и иногда занимают больше времени, чем ожидалось.
Далее начинается процесс исследования данных.
Теперь специалист Data Science может оперировать фактическими жесткими KPI и показателями модели.
Однако и здесь надо соблюдать динамическое равновесие между исследованием и разработкой; даже имея в виду четкие KPI, полезно не терять из виду некоторые, казалось бы, неподходящие направления решения.
Обработанные данные должны иметь формат, удобный для работы отдела Data Engineering. Однако могут быть выявлены некоторые недостатки сформированного рабочего массива данных (например, данных,
предоставленных заказчиком, может оказаться недостаточно). Data Engineer данных должен быть готов к такой ситуации, и искать дополнительный источник данных.
Следует заметить, что, хоть процесс подготовки данных и выглядит отделенным от процесса теоретического исследования и анализа вариантов решений, они обычно либо выполняются параллельно, либо чередуются между собой.
Подготовка к моделированию (зеленый цвет на рисунках 2.2, 2.3, 2.5).
Подготовка к началу разработки модели в значительной степени зависит от имеющегося технического обеспечения и объема технической поддержки, доступной Data Scientist. Возможно, что Data Scientist создаст новый репозиторий кода и запустит локальный сервер Jupyter Notebook или запросит
более мощную облачную машину для выполнения вычислений.
Также может быть, что сотрудники отдела Data Scienсе создадут код для управления версиями данных и моделей или для отслеживания и управления экспериментом. Возможно, что такая функциональность уже существует в используемых сервисах, то тогда потребуется создание некоторых настроек для распределения ресурсов или настройки пользовательских пакетов и т. д.
Этот этап связан не только с технической подготовкой, но и подготовкой ‘features’ и параметров для будущей нейросети.
Разработка и обучение модели (красный цвет на рисунках 2.2, 2.3, 2.5). Задачами этого этапа являются развертывание модели, обучение (Machine
Learning) и непрерывный мониторинг результатов обучения.
В подготовленной на предыдущем этапе среде с выбранными параметрами создается модель нейросети. Специалисты отдела Data Engineering передают в отдел Data Science наборы данных и созданные к ним запросы, подготовленные в соответствии с набором ‘features’. Отдел Data Science загружает эти данные в обучающую среду, которая использует эти данные для обучения модели. Специалисты отдела Data science осуществляют мониторинг
результатов обучения, используя функциональность сервисов. После того, как модель считается обученной, можно переходить к модельному тесту.
При разработке и обучении модели различные ее версии (и обслуживающий массив данных) должны постоянно проверяться на соответствие заранее установленным KPI.
Это дает возможность оценить степень продвижения в обучении, а также позволяет отделу Data Science решить, когда модель работает достаточно хорошо, чтобы гарантировать
полное соответствие выработанным на начальном этапе KPI.
Рисунок 2.7 - Алгоритм принятия решения об успешности модели Если результаты обучения модели не соответствуют ожидаемым
показателям, то существует несколько причин такого исхода.
Специалист отдела Data Science анализирует результаты обучения нейронной сети и принимает решение о дальнейших действиях: изменить параметры, изменить «features», или данный вариант модели не пригоден для решения задачи и надо переходить к выбору следующего варианта модели.
Другим возможным результатом неудачного обучения является пересмотр цели продукта. В редких случаях изменение цели влечет за собой незначительные изменения в технической реализации проекта. Но в общем, это означает, что мы возвращаемся на фазу анализа предметной области.
Не исключен наиболее экстремальный вариант - отмена проекта; если специалист по данным уверен, что все направления исследований былиизучены, а проектный менеджер уверен, что продукт исчерпал свой потенциал, возможно, пришло время перейти к другому проекту.
Если обучение модели прошло успешно и она реализует заданные KPI, то этап R&D можно считать успешно законченным и переходить в разработке алгоритмической части конечного продукта, а также созданию интерфейса пользователя.
В ситуациях, когда расхождение между полученными и заданными значениями KPI не является критичным, требуется более тщательный их пересмотр и согласование с Product Owner.
Необходимо убедиться, что текущее значение показателя находится в интервале приемлемого разброса. При этом необходимо учитывать требования к продукту и интересы