Файл: Направление подготовки 09. 03. 04 Программная инженерия.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 29.10.2023
Просмотров: 233
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
о изменении сигнала со временем, однако подобная информация очень важна в контексте синхронной обработки аудиовизуальной информации.
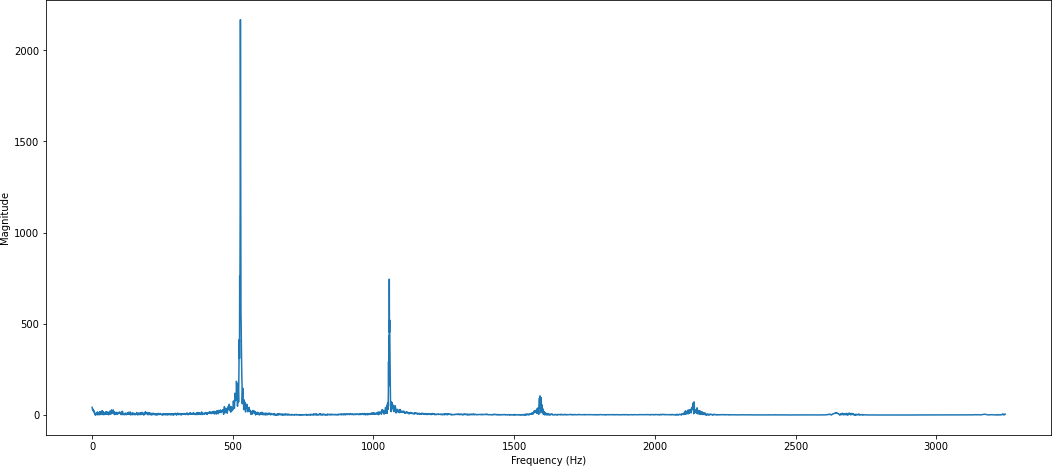
Рис. 1.8 – Аудиосигнал после применения дискретного преобразования Фурье
Для решения проблемы потери информации о зависимости сигнала от времени применя- ется оконное преобразование Фурье (1.6), основная идея которого заключается в разбиении ис- ходного сигнала на набор последовательных ”окон”, каждое из которых включает в себя опре- деленный промежуток времени, для каждого окна применяется дискретное преобразование Фурье [32].
∑
N−1
N
S(m,k) = x(n+ mH)ω(n) exp−i2πn k
(1.6)
n=0
где m- номер окна, k - частота, H- размер пересечения окон, ω - оконная функция. В качестве оконной функции чаще всего используется окно Ханна (1.7) [32].
ω(n) = 0.5(1 − cos(
2πn N− 1
)),n= 1 ...N(1.7)
Результатом применения оконного преобразования Фурье, является спектрограмма (рис.
1.9), описывающая частоту и амплитуду исходного сигнала в зависимости от времени.
Аудиосигнал после применения оконного преобразования Фурье уже пригоден для эффек- тивной обработки, тем не менее, аудиосигналы имеют специфику восприятия человеком - мы по-разному воспринимаем разницу частот на разных уровнях (разница, например, между 65 и 262 герцами гораздо более ощутима для человека, чем между 1568 и 1760 герцами). Для отоб- ражения подобного явления вводится понятие мел - психофизическая единица высоты звука [33]. На практике, для ”выравнивания” сигнала в соответствии с восприятием человека создает- ся определённый набор мел фильтров, каждый из которых содержит коэффициенты для опре-
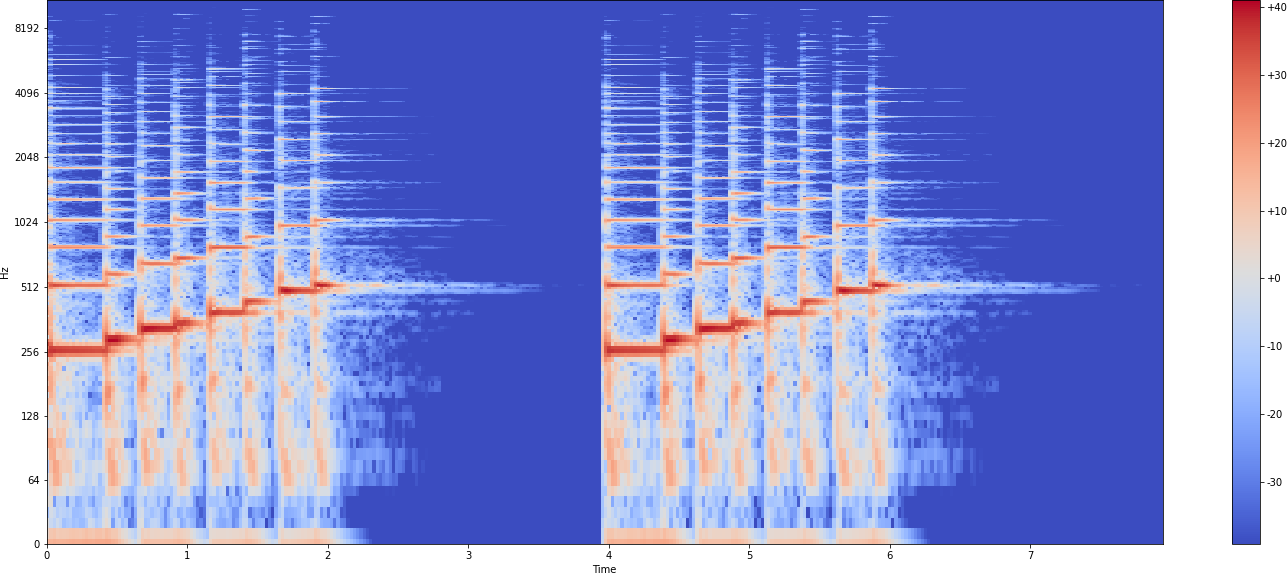
Рис. 1.9 – Аудиосигнал после применения оконного преобразования Фурье
деленной разницы частот входного сигнала, далее мел фильтры применяются к результатам оконного преобразования Фурье и создается мел-спектрограмма.
Наборы данных или датасеты очень важны в целях обучения и оценки эффективности ней- росетевой модели. На данный момент в открытом доступе существует большое количество коллекций размеченных данных в области обработки аудиовизуальной информации, отметим некоторые из них.
YFCC100M — крупнейшая из когда-либо выпущенных общедоступных коллекций мульти- медиа, содержащая в общей сложности 100 миллионов медиаобъектов, из которых примерно 99,2 миллиона фотографий и 0,8 миллиона видео. Все они были загружены на Flickr в период с 2004 по 2014 год и опубликованы под коммерческой или некоммерческой лицензией CC. [34] В наборе данных содержатся 68 552 616 фотографий и 418 507 видео, которые пользователи аннотировали тегами или ключевыми словами. Теги создают богатый и разнообразный набор сущностей, связанных с людьми (ребенок, семья), животными (кошка, собака), местами (парк, пляж), путешествиями (природа, город) и многим другим. В общей сложности 3 343 487 фо- тографий и 7 281 видео содержат машинные метки, автоматически созданные и добавленные
камерой, компьютером, приложением или другой автоматизированной системой.
AudioSet состоит из постоянно расширяющейся онтологии из 632 классов аудиособытий и коллекции из 2 084 320 десятисекундных звуковых клипов, взятых из видео YouTube и разме- ченных вручную. Онтология представлена в виде иерархического графа категорий событий, охватывающего широкий спектр звуков человека, животных, музыкальных инструментов, а также обычных повседневных звуков окружающей среды
[35]. На данный момент набор дан-
ных содержит 527 классов видео с определенным звуком.
Как отдельный сегмент можно выделить датасеты, направленные на анализ человеческой речи и содержащие видео с различными ораторами.
The Audio-Visual Lombard Grid Speech Corpus [36] содержит записи монолога 54 людей (30 женщин и 24 мужчины), говорящие записывались в анфас и в профиль, половина монологов произносилось на ломбардском языке.
AVSpeech — крупномасштабный набор аудиовизуальных данных, содержащий речевые ви- деоклипы без фоновых шумов. Сегменты длятся от 3 до 10 секунд, и в каждом клипе слыши- мый звук в саундтреке принадлежит одному говорящему человеку, видимому на видео. В об- щей сложности набор данных содержит примерно 4700 часов видеофрагментов из 290 тысяч видео на YouTube, охватывающих самых разных людей, языки и позы лиц [37].
В процессе анализа существующих решений и в соответствии с целью работы - разработка метода и программных модулей генерации аудиоинформации на основе видеозаписи, были поставленны следующие задачи:
В данном разделе выполнен анализ существующих решений, моделей и методов генера- ции ауидоинформации из видеоинформации, а именно:
Единственным эффективным существующим решением, направленным на совместную обработку аудио- и видеопотоков информации, являются технологии машинного обуче- ния, в частности, нейронные сети.
Описаны технологии сверточных, рекуррентных и генеративно-состязательных нейрон- ных сетей.
ности дальнейшего взаимодействия с ней.
Одним из наиболее популярных и репрезентативных способов представления аудиоин- формации является мел-спектрограмма.
Все проанализированные подходы и методы будут применяться при разработке реше- ния, описанного в данной работе.
Рис. 1.8 – Аудиосигнал после применения дискретного преобразования Фурье
Для решения проблемы потери информации о зависимости сигнала от времени применя- ется оконное преобразование Фурье (1.6), основная идея которого заключается в разбиении ис- ходного сигнала на набор последовательных ”окон”, каждое из которых включает в себя опре- деленный промежуток времени, для каждого окна применяется дискретное преобразование Фурье [32].
∑
N−1
N
S(m,k) = x(n+ mH)ω(n) exp−i2πn k
(1.6)
n=0
где m- номер окна, k - частота, H- размер пересечения окон, ω - оконная функция. В качестве оконной функции чаще всего используется окно Ханна (1.7) [32].
ω(n) = 0.5(1 − cos(
2πn N− 1
)),n= 1 ...N(1.7)
Результатом применения оконного преобразования Фурье, является спектрограмма (рис.
1.9), описывающая частоту и амплитуду исходного сигнала в зависимости от времени.
Аудиосигнал после применения оконного преобразования Фурье уже пригоден для эффек- тивной обработки, тем не менее, аудиосигналы имеют специфику восприятия человеком - мы по-разному воспринимаем разницу частот на разных уровнях (разница, например, между 65 и 262 герцами гораздо более ощутима для человека, чем между 1568 и 1760 герцами). Для отоб- ражения подобного явления вводится понятие мел - психофизическая единица высоты звука [33]. На практике, для ”выравнивания” сигнала в соответствии с восприятием человека создает- ся определённый набор мел фильтров, каждый из которых содержит коэффициенты для опре-
Рис. 1.9 – Аудиосигнал после применения оконного преобразования Фурье
деленной разницы частот входного сигнала, далее мел фильтры применяются к результатам оконного преобразования Фурье и создается мел-спектрограмма.
- 1 2 3 4 5 6 7 8 9 ... 15
Существующие наборы данных в области обработки аудиовизуальной информации
Наборы данных или датасеты очень важны в целях обучения и оценки эффективности ней- росетевой модели. На данный момент в открытом доступе существует большое количество коллекций размеченных данных в области обработки аудиовизуальной информации, отметим некоторые из них.
YFCC100M — крупнейшая из когда-либо выпущенных общедоступных коллекций мульти- медиа, содержащая в общей сложности 100 миллионов медиаобъектов, из которых примерно 99,2 миллиона фотографий и 0,8 миллиона видео. Все они были загружены на Flickr в период с 2004 по 2014 год и опубликованы под коммерческой или некоммерческой лицензией CC. [34] В наборе данных содержатся 68 552 616 фотографий и 418 507 видео, которые пользователи аннотировали тегами или ключевыми словами. Теги создают богатый и разнообразный набор сущностей, связанных с людьми (ребенок, семья), животными (кошка, собака), местами (парк, пляж), путешествиями (природа, город) и многим другим. В общей сложности 3 343 487 фо- тографий и 7 281 видео содержат машинные метки, автоматически созданные и добавленные
камерой, компьютером, приложением или другой автоматизированной системой.
AudioSet состоит из постоянно расширяющейся онтологии из 632 классов аудиособытий и коллекции из 2 084 320 десятисекундных звуковых клипов, взятых из видео YouTube и разме- ченных вручную. Онтология представлена в виде иерархического графа категорий событий, охватывающего широкий спектр звуков человека, животных, музыкальных инструментов, а также обычных повседневных звуков окружающей среды
[35]. На данный момент набор дан-
ных содержит 527 классов видео с определенным звуком.
Как отдельный сегмент можно выделить датасеты, направленные на анализ человеческой речи и содержащие видео с различными ораторами.
The Audio-Visual Lombard Grid Speech Corpus [36] содержит записи монолога 54 людей (30 женщин и 24 мужчины), говорящие записывались в анфас и в профиль, половина монологов произносилось на ломбардском языке.
AVSpeech — крупномасштабный набор аудиовизуальных данных, содержащий речевые ви- деоклипы без фоновых шумов. Сегменты длятся от 3 до 10 секунд, и в каждом клипе слыши- мый звук в саундтреке принадлежит одному говорящему человеку, видимому на видео. В об- щей сложности набор данных содержит примерно 4700 часов видеофрагментов из 290 тысяч видео на YouTube, охватывающих самых разных людей, языки и позы лиц [37].
- 1 2 3 4 5 6 7 8 9 10 ... 15
Цели и задачи учебно-исследовательской работы
В процессе анализа существующих решений и в соответствии с целью работы - разработка метода и программных модулей генерации аудиоинформации на основе видеозаписи, были поставленны следующие задачи:
-
Разработка метода генерации аудиоинформации на основе видеозаписи, основанного на нейросетевом подходе. -
Построение и разработка модуля генерации аудиоинформации на основе видеозаписи. -
Экспериментальная проверка эффективности разработанного метода и модуля.
-
Выводы
В данном разделе выполнен анализ существующих решений, моделей и методов генера- ции ауидоинформации из видеоинформации, а именно:
-
Проанализированы современные работы в направлении обработки аудио- и видеоинфор- мации.
Единственным эффективным существующим решением, направленным на совместную обработку аудио- и видеопотоков информации, являются технологии машинного обуче- ния, в частности, нейронные сети.
-
Обозначены и описаны основные инструменты, применяемые для обработки аудио- и видеоинформации.
Описаны технологии сверточных, рекуррентных и генеративно-состязательных нейрон- ных сетей.
-
Описаны методы обработки аудиоинформации, направленные на увеличение эффектив-
ности дальнейшего взаимодействия с ней.
Одним из наиболее популярных и репрезентативных способов представления аудиоин- формации является мел-спектрограмма.
Все проанализированные подходы и методы будут применяться при разработке реше- ния, описанного в данной работе.
-
Метод генерации аудиоинформации на основе видеозаписи
-
Постановка задачи