ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 04.12.2023
Просмотров: 364
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
2.1. Основные цели и задачи прикладного корреляционно-регрессионного анализа
2.2. Постановка задачи регрессии
2.4. Коэффициент корреляции, коэффициент детерминации, корреляционное отношение
3. Классическая линейная модель множественной регрессии
3.2. Оценивание коэффициентов КЛММР
Полученное уравнение
Заметим, что ошибка прогноза ei фактически является оценкой значений ui. График ошибки ei представлен на рис. 2.2. Следует отметить факт равенства нулю суммы ei=0, что согласуется с первым ограничением модели парной регрессии - Eui=0, i=1,…,n.
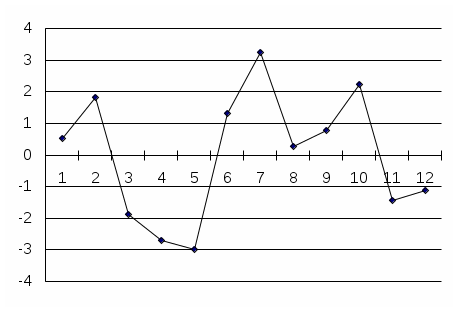
Рис. 2.2. График ошибки прогноза
В модели (2.2) функция f может быть и нелинейной. Причем выделяют два класса нелинейных регрессий:
-
регрессии, нелинейные относительно включенной объясняющей переменной, но линейные по параметрам, например полиномы разных степеней - Yi =a0 + a1Xi + a2Xi2+ ui, i=1,…,n или гипербола - Yi =a0 + a1/Xi + ui, i=1,…,n; -
регрессии нелинейные по оцениваемым параметрам, например степенная функция - Yi =a0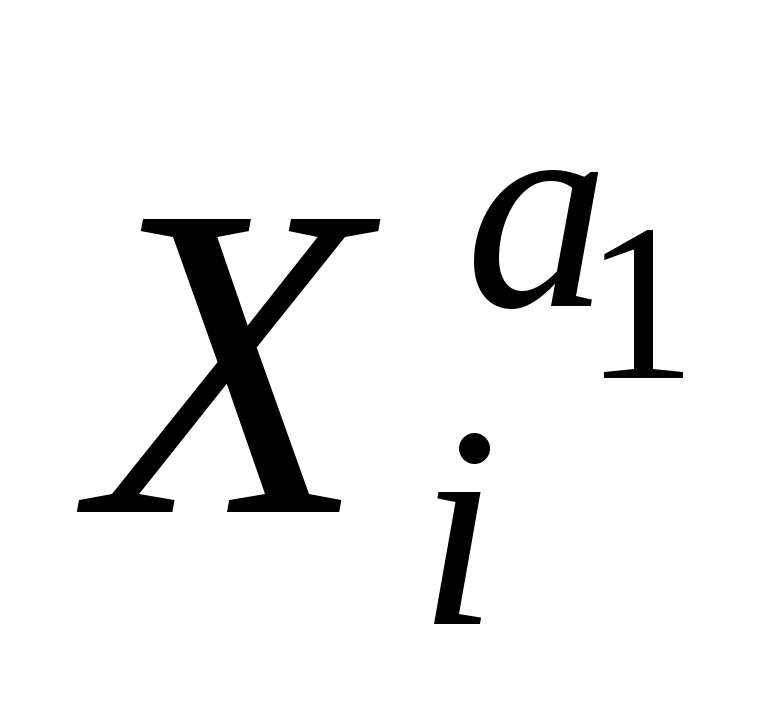 ui, i=1,…,n, или показательная функция - Yi =
ui, i=1,…,n, или показательная функция - Yi =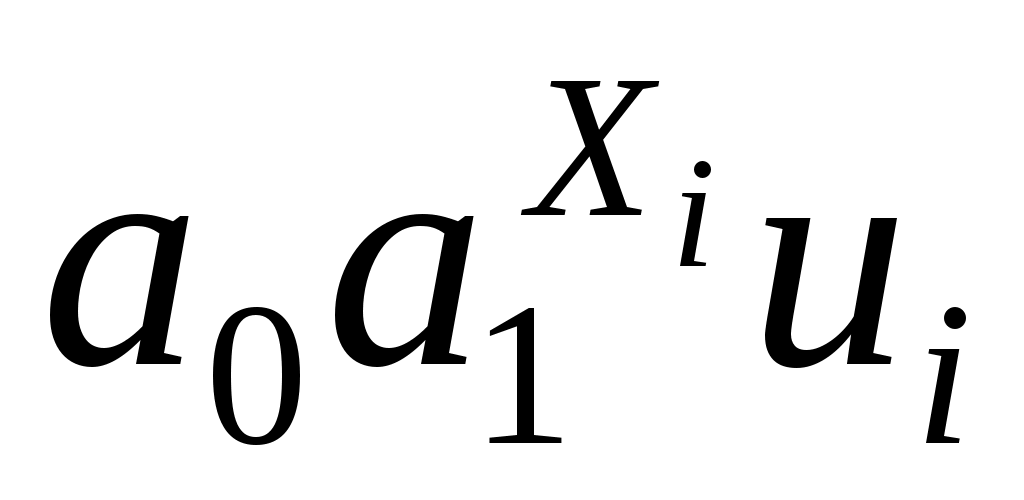 , i=1,…,n.
, i=1,…,n.
В первом случае МНК применяется так же, как и в линейной регрессии, поскольку после замены, например, в квадратичной параболе Yi =a0 + a1Xi + a2Xi2+ ui переменной Xi2 на X1i: Xi2=X1i, получаем линейное уравнение регрессии Yi =a0 + a1Xi + a2
X1i+ ui, i=1,…,n.
Во втором случае в зависимости от вида функции возможно применение линеаризующих преобразований, приводящих функцию к виду линейной. Например, для степенной функции Yi =a0
Однако для, например, модели Yi =a0+a2
2.4. Коэффициент корреляции, коэффициент детерминации, корреляционное отношение
Для трактовки линейной связи между двумя переменными акцентируют внимание на коэффициенте корреляции.
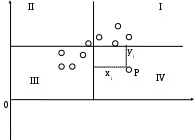
Пусть имеется выборка наблюдений (Xi, Yi), i=1,...,n, которая представлена на диаграмме рассеяния, именуемой также полем корреляции (рис. 2.3).
Y
X
Рис. 2.3. Диаграмма рассеяния
Разобьем диаграмму на четыре квадранта так, что для любой точки P(Xi, Yi) будут определены отклонения
Ясно, что для всех точек I квадранта xiyi>0; для всех точек II квадранта xiyi<0; для всех точек III квадранта xiyi>0; для всех точек IV квадранта xiyi<0. Следовательно, величина xiyi может служить мерой зависимости между переменными X и Y. Если большая часть точек лежит в первом и третьем квадрантах, то xiyi>0 и зависимость положительная, если большая часть точек лежит во втором и четвертом квадрантах, то xiyi<0 и зависимость отрицательная. Наконец, если точки рассеиваются по всем четырем квадрантам xiyi близка к нулю и между X и Y связи нет.
Указанная мера зависимости изменяется при выборе единиц измерения переменных X и Y. Выразив xiyi в единицах среднеквадратических отклонений, получим после усреднения выборочный коэффициент корреляции:
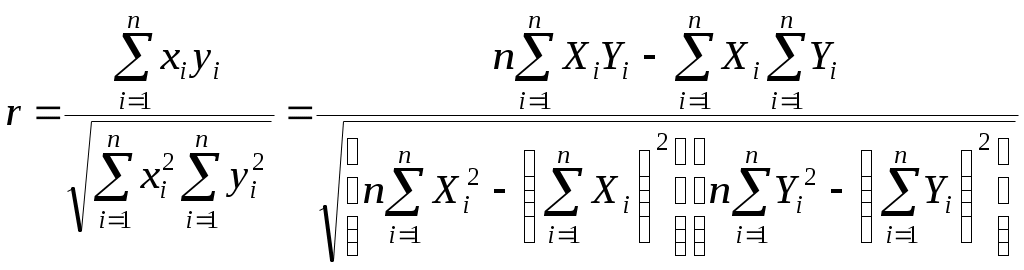 (2.9)
(2.9)Из последнего выражения можно после преобразований получить следующую формулу для квадрата коэффициента корреляции:
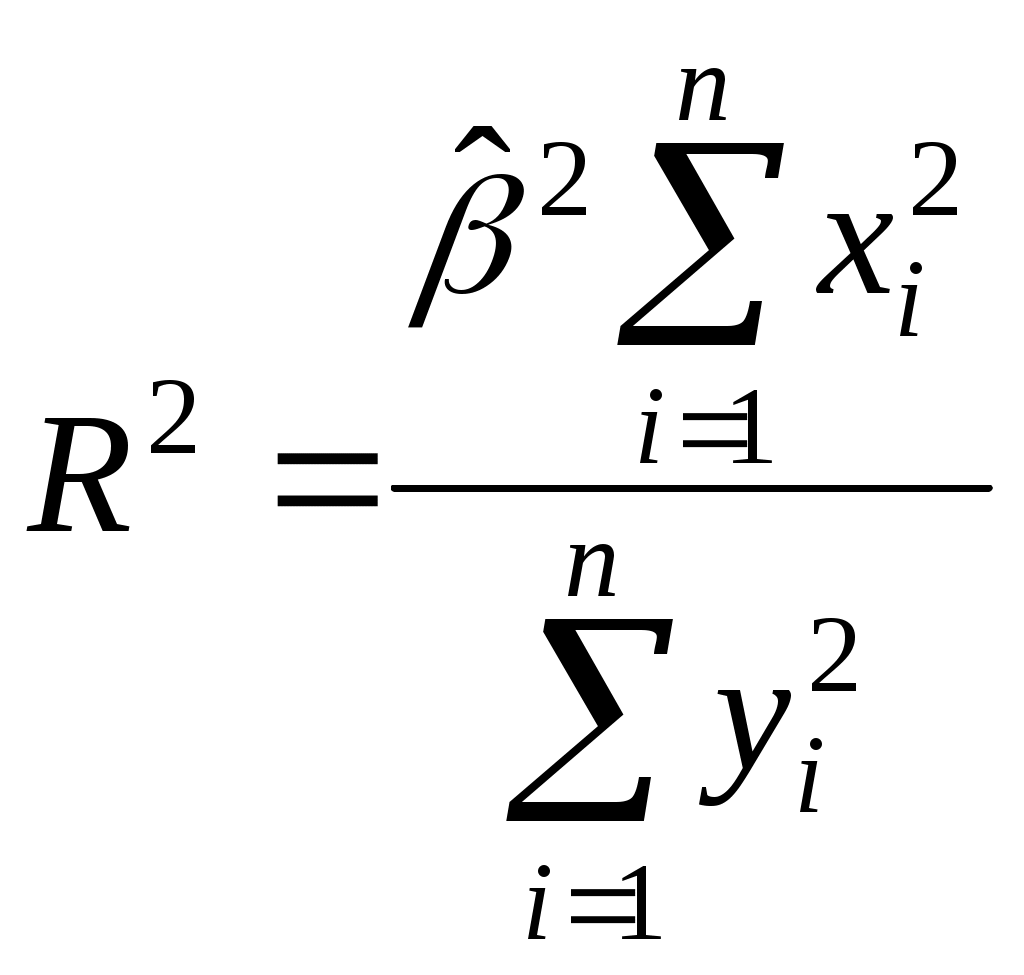 или
или 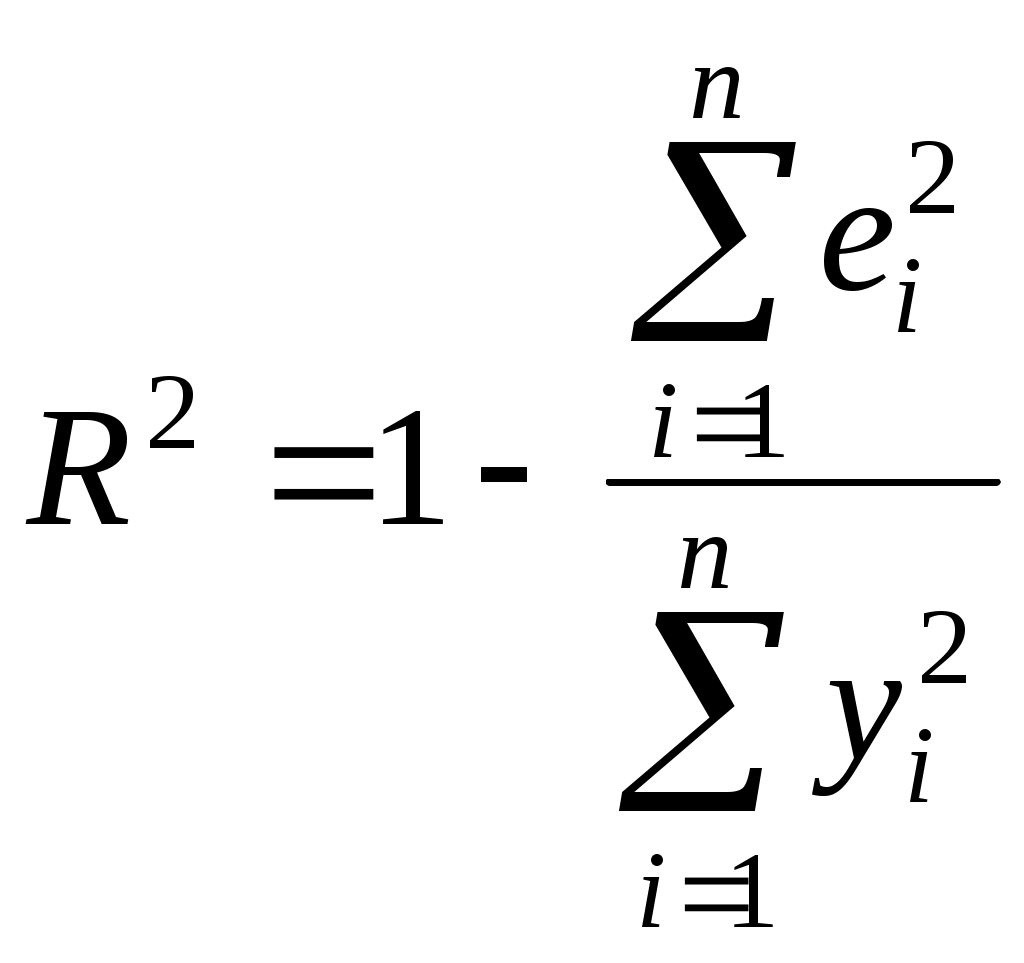 (2.10)
(2.10)Квадрат коэффициента корреляции называется коэффициентом детерминации. Согласно (2.10) значение коэффициента детерминации не может быть больше единицы, причем это максимальное значение будет достигнуто при
=0, т.е. когда все точки диаграммы рассеяния лежат в точности на прямой. Следовательно, значения коэффициента корреляции лежат в числовом промежутке от -1 до +1.
Кроме того, из (2.10) следует, что коэффициент детерминации равен доле дисперсии Y (знаменатель формулы), объясненной линейной зависимостью от X (числитель формулы). Это обстоятельство позволяет использовать R2 как обобщенную меру "качества" статистического подбора модели (2.6). Чем лучше регрессия соответствует наблюдениям, тем меньше
Поскольку коэффициент корреляции симметричен относительно X и Y, то есть rXY=rYX, то можно говорить о корреляции как о мере взаимозависимости переменных. Однако из того, что значения этого коэффициента близки по модулю к единице, нельзя сделать ни один из следующих выводов: Y является причиной X; X является причиной Y; X и Y совместно зависят от какой-то третьей переменной. Величина r ничего не говорит о причинно-следственных связях. Эти вопросы должны решаться, исходя из содержательного анализа задачи. Следует избегать и так называемых ложных корреляций, т.е. нельзя пытаться связать явления, между которыми отсутствуют реальные причинно-следственные связи. Например, корреляция между успехами местной футбольной команды и индексом Доу-Джонса. Классическим является пример ложной корреляции, приведенный в начале ХХ века известным российским статистиком А.А. Чупровым: если в качестве независимой переменной взять число пожарных команд в городе, а в качестве зависимой переменной – сумму убытков от пожаров за год, то между ними есть прямая корреляционная зависимость, т.е. чем больше пожарных команд, тем больше сумма убытков. На самом деле здесь нет причинно-следственной связи, а есть лишь следствия общей причины – величины города.
Проверка гипотезы о значимости выборочного коэффициента корреляции эквивалентна проверке гипотезы о =0 (см. ниже) и, следовательно, равносильна проверке основной гипотезы об отсутствии линейной связи между Y и X. Вычисляя значение t-статистики
вывод о значимости r делается при t>t, где t - соответствующее табличное значение t-распределения с (n-2) степенями свободы и уровнем значимости .
Пример. Вычислим коэффициент корреляции и проверим его значимость для нашего примера табл. 2.1.
По (2.9) r=43145/(4651040068,25)0,5=0,9994. R2=0,998. Значение t-статистики t=0,9994[10/(1-0,998)]0,5=70,67. Поскольку t0,05;10=2,228, то t>t0,05;10 и коэффициент корреляции значим. Следовательно, можно считать, что линейная связь между переменными Y и X в примере существует.
Если между переменными имеет место нелинейная зависимость, то коэффициент корреляции теряет смысл как характеристика степени тесноты связи. В этом случае используется наряду с расчетом коэффициента детерминации расчет корреляционного отношения.
Предположим, что выборочные данные могут быть сгруппированы по оси объясняющей переменной X. Обозначим s – число интервалов группирования,
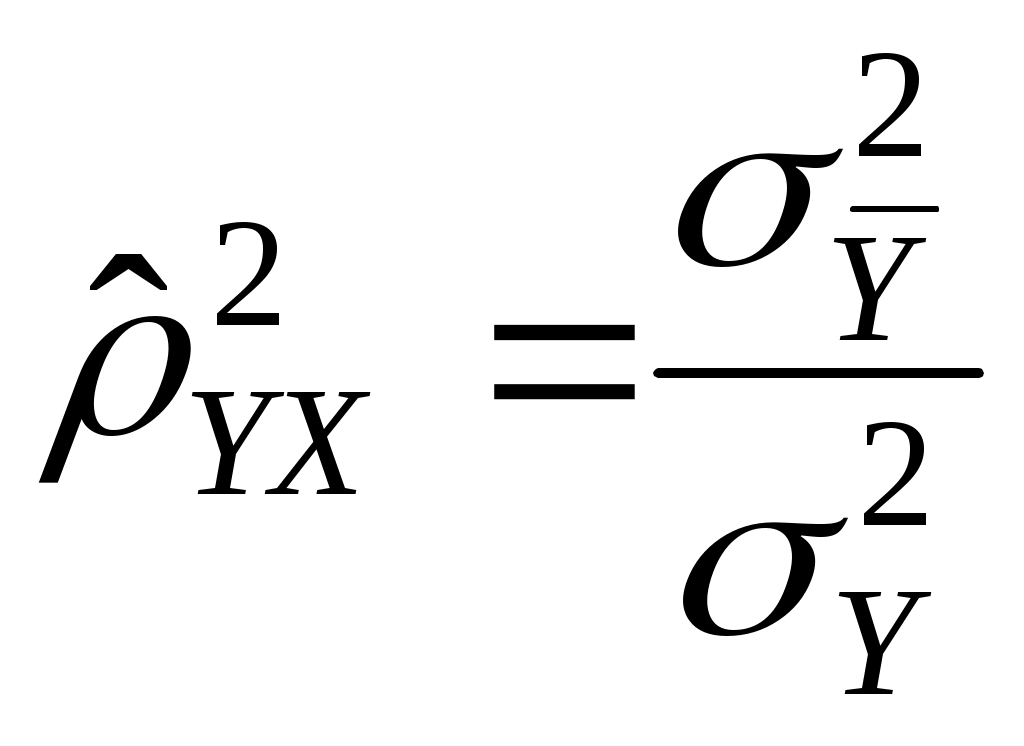 . (2.11)
. (2.11)Величину
Величина