Файл: Научное обоснование совершенствования разработки информационных систем сбора и анализа показателей здоровья населения и деятельности системы здравоохранения.docx
Добавлен: 24.10.2023
Просмотров: 329
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Использование облачной модели имеет следующие преимущества для потребителя:
-
высокая скорость и простота развертывания решения; -
гибкость и масштабируемость; -
независимость от поставщиков и возможность перехода на лучшее решение; -
операционный характер затрат и оплата по факту потребления; -
низкие риски пилотных проектов.
В облачной модели выделяют особый вид услуг – «программное обеспечение или приложение как услуга – Software/Application as a Service (SaaS/AaaS). Потребителю предоставляются программные средства (приложения), выполняемые на облачной инфраструктуре. Приложения доступны с различных клиентских устройств через интерфейс «тонкого» клиента, такой как браузер (например, электронная почта с web-интерфейсом). Потребитель не управляет и не контролирует саму облачную инфраструктуру, на которой выполняется приложение, будь то сети, серверы, операционные системы, системы хранения или даже некоторые специфичные для приложений возможности. В отдельных случаях потребителю может быть предоставлена возможность доступа к некоторым пользовательским конфигурационным настройкам» [58].
Преимущества облачной модели, особенно для сегментов государственной и муниципальной информатизации, делают ее основным вариантом тиражирования типовых программных решений в сфере электронного правительства и информационного общества в России. Кроме того, облачная модель открывает ранее невиданные возможности для разработчиков решений, снимая барьеры в организации сбыта решений и позволяя сосредоточиться на функциональные возможности и качестве решений, а также приводит к снижению стоимости решений для потребителей за счет конкуренции, в том числе со стороны небольших компаний с малыми издержками.
Таким образом, нами предлагается использовать облачную модель как при создании автоматизированной системы поддержки кодирования на основе лексического анализа, так и информационной системы мониторинга физического развития детей и подростков.
Также необходимо отметить, что при проектировании системы использованы федеральные законы и нормативные акты об информации,
информационных технологиях и о защите информации, а также нормативно-технические документы национальной системы стандартизации Российской Федерации:
-
стандарты информатизации здоровья; -
комплекс стандартов на автоматизированные системы; -
стандарты единой системы программной документации; -
стандарты защиты информации.
- 1 2 3 4 5 6 7 8 9 ... 15
Функциональная декомпозиция системы лексического анализа при автоматизированной поддержке кодирования
Функционально система состоит из следующих подсистем, которые являются унифицированными как для МКБ-10, так и для МКБ-11 (подсистемы и их взаимодействие приведены на рис.8):
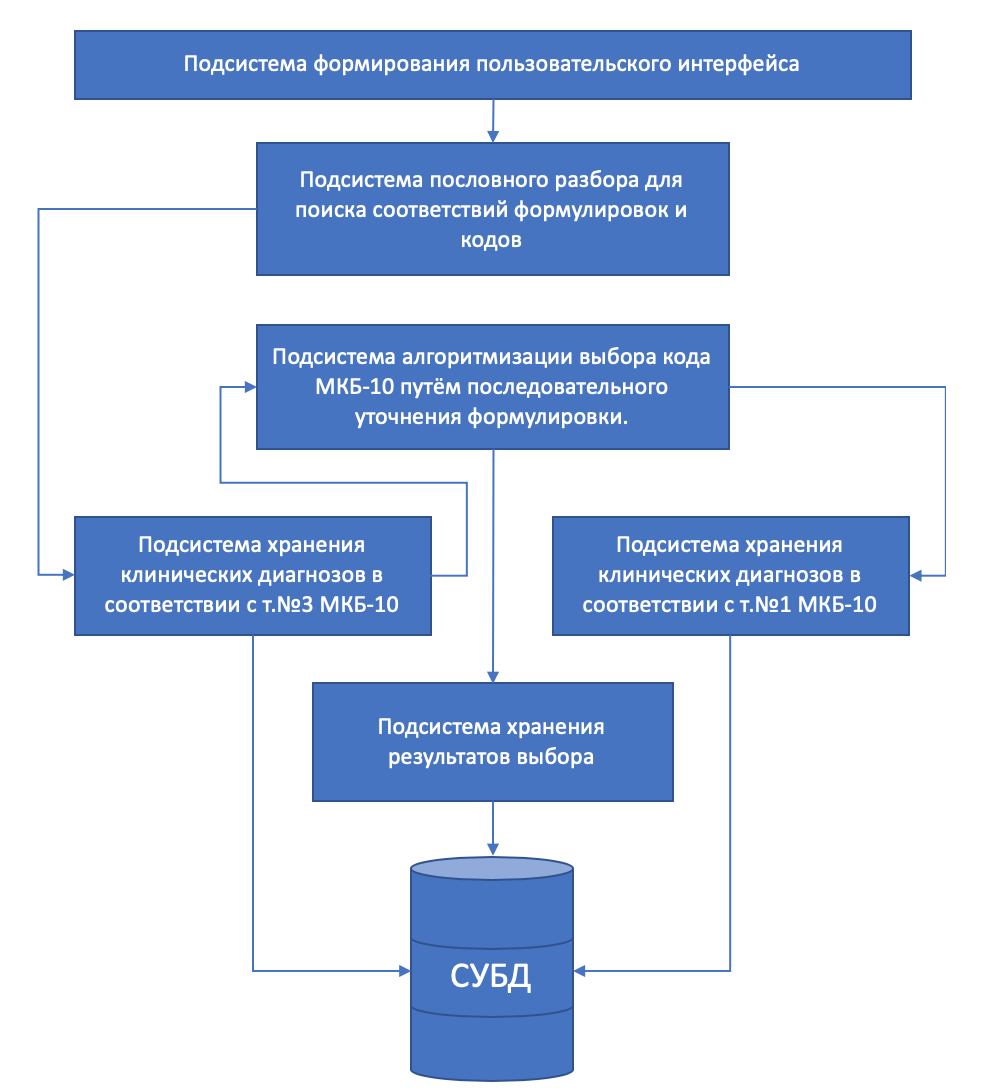
Рисунок 8 - Взаимодействие подсистем.
-
Подсистема хранения клинических диагнозов в соответствии с т.№3 МКБ-10. -
Данная подсистема представляет собой совокупность таблиц базы данных, обеспечивающих хранение структурированной информации в соответствии содержанием т.№3 МКБ-10, в которую внесены фактические данные, а так же средства доступа к ним, позволяющие получать эти данные по сервис-ориентированной модели. При переходе на МКБ-11 требуется заменить данную таблицу или дополнить таблицей перехода с МКБ-10 на МКБ-11 (которая должна выйти одномоментно с выходом МКБ-11). -
Подсистема хранения клинических диагнозов в соответствии с т.№1 МКБ-10. -
Данная подсистема представляет собой совокупность таблиц базы данных, обеспечивающее хранение структурированной информации в соответствии содержанием т.№1 МКБ-10, в которую внесены фактические данные, а так же средства доступа к ним, позволяющие получать эти данные по сервис-ориентированной модели. При переходе на МКБ-11 требуется заменить данную таблицу или дополнить таблицей перехода с МКБ-10 на МКБ-11 (которая должна выйти одномоментно с выходом МКБ-11). -
Подсистема пословного разбора для поиска соответствий формулировок и кодов. -
Данная подсистема представляет собой совокупность таблиц в базе данных, предназначенных для хранения результатов пословного разбора, и алгоритмов, выполняющих пословный разбор. Алгоритмы реализованы на языке scala с последующей трансформаций в Java-апплет и размещением на сервере приложений. Хранимые процедуры СУБД не используются. Доступ к данной подсистеме осуществляется под правами администратора системы. Вызов осуществляется только при инициализации системы. После завершения работы данной подсистемы создаются данные, необходимые для работы остальных прикладных подсистем. -
Подсистема алгоритмизации выбора кода МКБ-10 путём последовательного уточнения формулировки. -
Данная подсистема непосредственно осуществляет последовательный выбор элементов формулировки диагноза от ведущего термина. Представляет собой совокупность алгоритмов, осуществляющих поиск и выдачу ответа пользователю по частичному совпадению, алгоритма приёма ответа пользователя о выбранном элементе и алгоритма последовательного движения по структуре клинического диагноза. Последний алгоритм обеспечивает последовательный вызов двух предыдущих на каждом шаге выбора, а так же принимает решение о осуществлении или не осуществлении последующего шага спуска. -
Подсистема хранения результатов выбора представляет собой совокупность таблиц в базе данных, и алгоритмов на языке scala с последующей трансформаций в Java-апплет и размещением на сервере приложений. Выполняет задачу сохранения результатов выбора пользователя. Вызывается для каждого шага «спуска» по структуре диагноза. -
Подсистема формирования пользовательского интерфейса представляет собой совокупность технологических алгоритмов на языке scala с последующей трансформаций в Java-апплет и размещением на сервере приложений, отвечающих за публикацию сервисов обмена данными, и HTML-страниц, размещаемых на сервере Apache, позволяющих выполнение javascript-кода на стороне браузера пользовательского компьютера с целью осуществления взаимодействия с сервером и формирования пользовательского интерфейса.
-
Область использования системы лексического анализа при автоматизированной поддержке кодирования
Можно выделить несколько областей применения системы. В зависимости от места применения функционала системы следует ожидать различных результатов её использования.
Прежде всего, это собственно решение задач кодирования диагнозов в лечебно-диагностическом процессе. В данном сценарии система используется на этапе формулирования клинического диагноза. Такой подход позволяет получить не только точное соответствие клинического и статистического диагноза, но и унифицировать формулировки клинического диагноза, сведя к минимуму произвольные отклонения от рекомендаций тома №3 МКБ-10. Наряду с наиболее полным эффектом такой подход создаёт препятствие, состоящее в необходимости отказа от сложившейся практики формулирования клинического диагноза, что требует от врача клинициста дополнительного времени на адаптации к предлагаемому порядку формулирования диагноза.
Другой сценарий — анализ формулировки, полученной из другой информационной системы (рис.9). В данном сценарии система работает с полностью сформулированным клиническим диагнозом и лишь выполняет подбор наиболее подходящих кодов МКБ-10. При этом упрощается порядок внедрения практики кодирования. Однако, не имея возможности влиять на процесс формулирования клинического диагноза, система вынуждена предложить несколько «наиболее соответствующих» кодов, что, несомненно снижает эффективность использования.
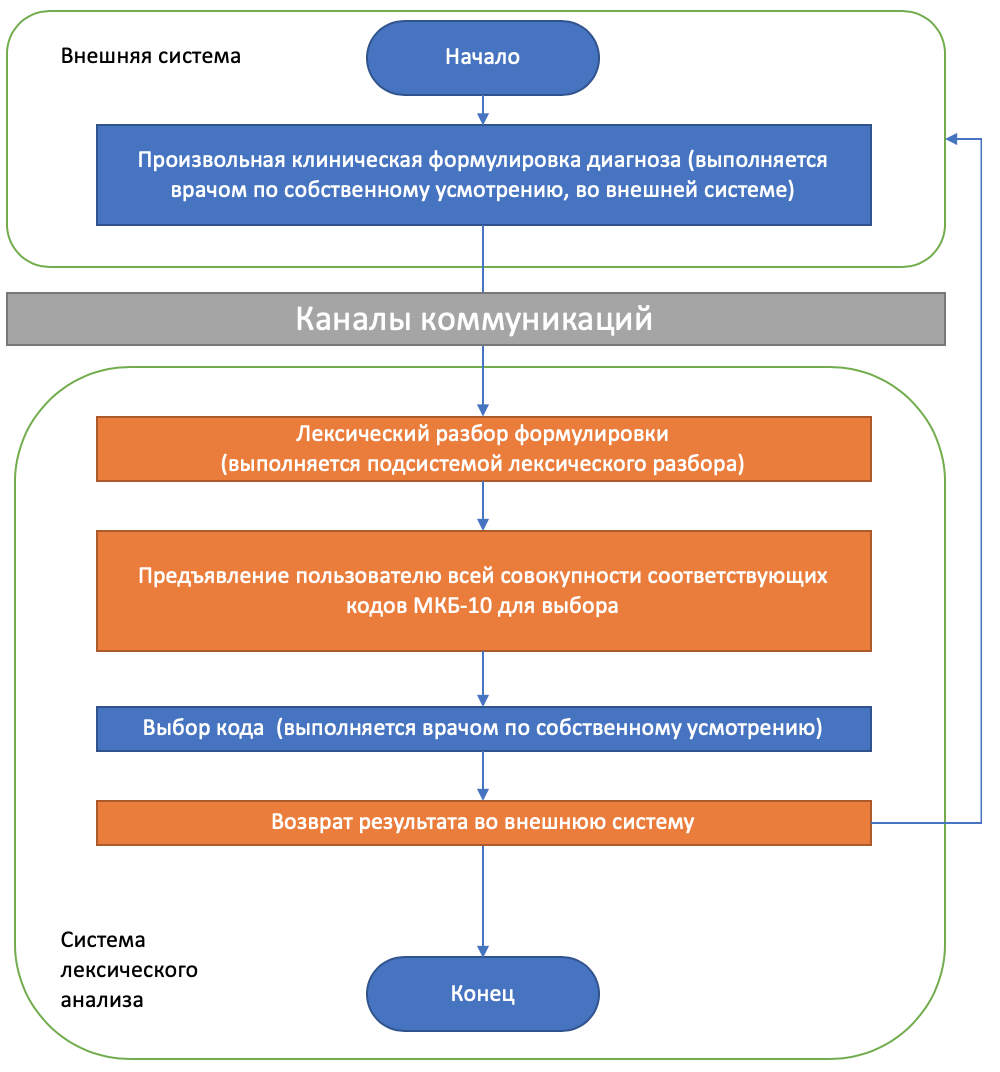
Рисунок 9 - Подход к использованию системы без изменения порядка клинической формулировки диагноза.
По нашему мнению, наиболее эффективным является первый подход, который должен быть адаптирован к реалиям использования информационных систем. Это, несомненно, означает необходимость интеграции предлагаемого решения с имеющимися медицинскими информационными системами (МИС) на уровне включения системы кодирования диагноза в интерфейс МИС.
- 1 2 3 4 5 6 7 8 9 ... 15
Создание промышленного прототипа
Решения, которые были положены в основу создания исследовательского прототипа модуля лексического анализа в составе автоматизированной информационной системы поддержки кодирования были апробированы в ходе опытной эксплуатации. По итогам проведения опытной эксплуатации исследовательского прототипа была отработаны основные решения, которые были положены в основу создания промышленного прототипа.
По итогам опытной эксплуатации все алгоритмы системы были разделены на три группы: алгоритмы проверки, алгоритмы поддержки заполнения, алгоритмы контроля сроков наступления событий.
В итоге был создан промышленный прототип, реализующий следующие алгоритмы:
-
Алгоритмы проверки; -
Алгоритмы поддержки заполнения; -
Алгоритмы контроля сроков наступления событий.
-
Алгоритмы проверки
Алгоритмы проверки на требования, предъявляемые к пунктам свидетельства в соответствии с Письмом от 19 января 2009 г. N 14-6/10/2-178, за исключением п.№19.
На рис. 10 приводится общий алгоритм проверки. Примеры проверок приводятся в таблице 2.
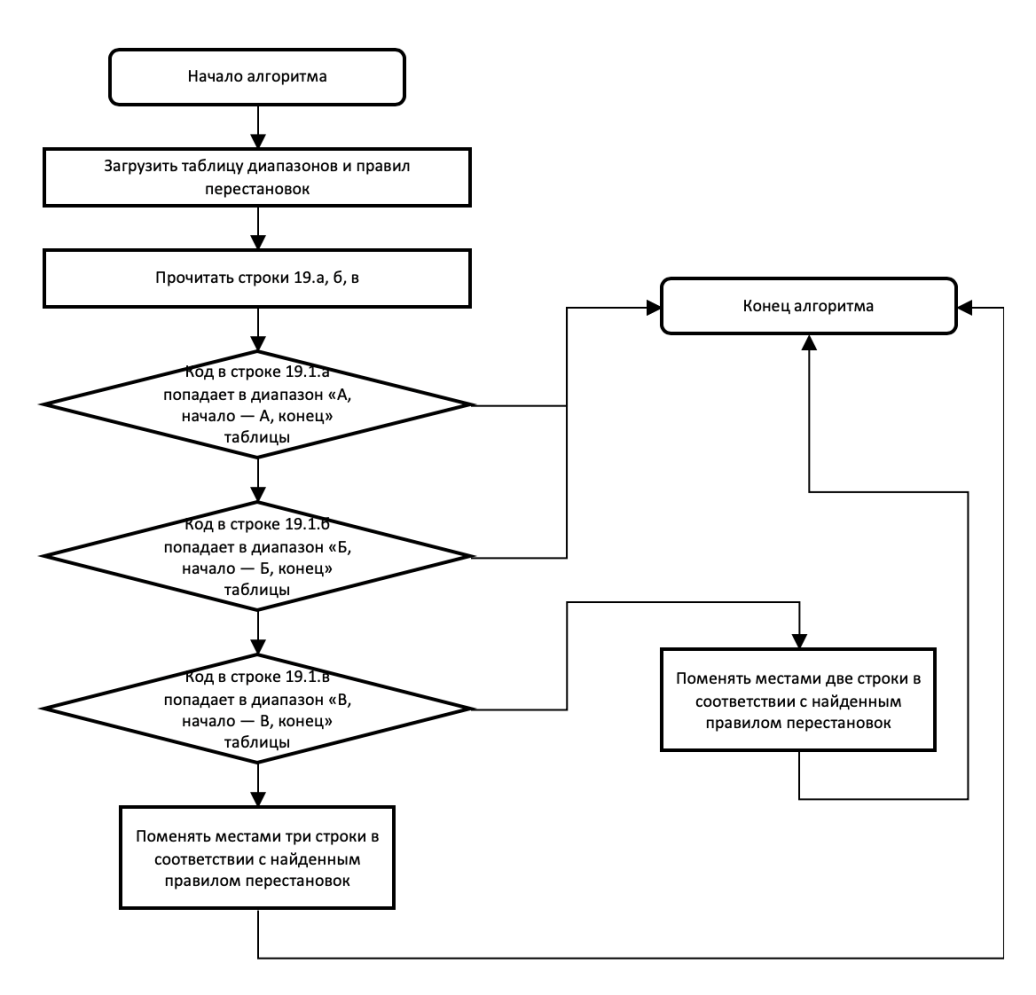
Рисунок 10 - Общий алгоритм проверки.
Таблица 2.
Примеры проверок
| Если поле «Серия» пустое то Зарегистрировать ошибку «Укажите серию свидетельства» |
| Если поле «Номер» пустое то Зарегистрировать ошибку «Укажите номер свидетельства» |
| Если поле «Дата выдачи» пустое Укажите дату выдачи свидетельства |
| Если поле «Вид свидетельства» пустое то Зарегистрировать ошибку «Укажите вид свидетельства» |
| Если поле «Фамилия» пустое или не равно «Неизвестно» то Зарегистрировать ошибку «Фамилия должна быть указана или введено – Неизвестно» |
| Если поле «Пол» пустое то Зарегистрировать ошибку «Укажите пол» |
| Если поле «Область жительства» пустое то Зарегистрировать ошибку «Область (республика, край) места жительства обязательно должна быть заполнена» |