Файл: Научное обоснование совершенствования разработки информационных систем сбора и анализа показателей здоровья населения и деятельности системы здравоохранения.docx
Добавлен: 24.10.2023
Просмотров: 326
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
опирающихся на научную составляющую работы, как на платформу для обеспечения трансформации процесса практического решения задач кодирования. Хотя научный дискурс не подразумевает решения практических задач, в данной работе получение практического результата непосредственно следовало из полученных научных заключений, что послужило основой для решения применить практические методы решения задач информатизации. Это были как совершенно рутинные методы обеспечения эффективного реляционного хранения данных, разработка пользовательского интерфейса, обеспечение технологически безопасного доступа к данным их изменения, так и такие наукоёмкие методы, как лексический и семантический анализ. Также отдельно была выполнена трудоёмкая работа по структуризации и сохранении в базе данных содержания третьего тома МКБ-10.
Таким образом, на этапе практической реализации удалось добиться существенного снижения роли т.н. "человеческого фактора" на этапе преобразования клинического диагноза, который, конечно, формируется врачом на основе его практического опыта, теоретических знаний, и уникальных особенностей конкретного клинического случая, в диагноз статистический, который является прежде всего формальным статистическим инструментом, позволяющим оценивать структуру заболеваемости в популяции.
Метод кодирования, реализованный в системе, предполагает следующий порядок взаимодействия с пользователем:
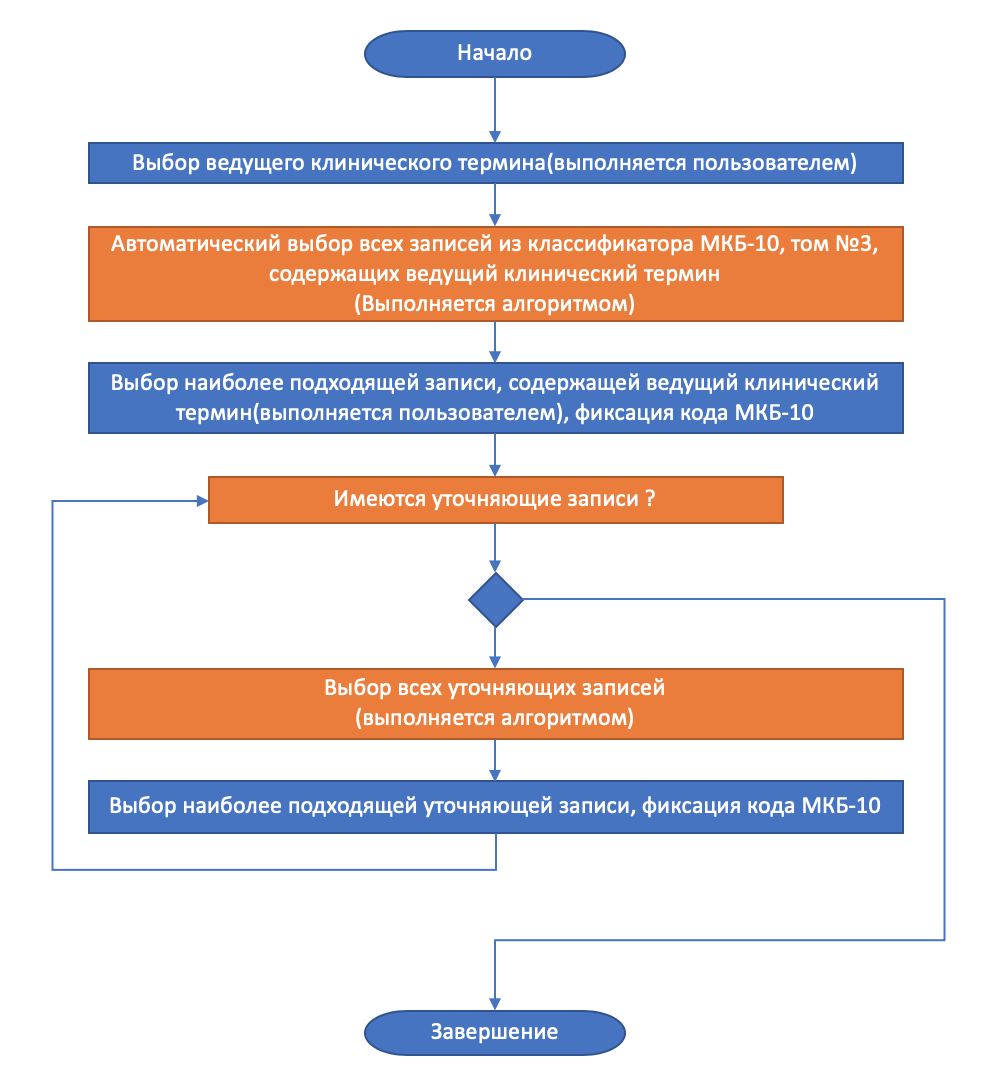
Рисунок 5 - Порядок работы системы при выборе кода с использованием системы лексического анализа
Следует заметить, что в случаях, когда промежуточное уточнение делает возможным выбор кода диагноза МКБ-10, отличного от выбранного ранее, этот выбор фиксируется, и предъявляется пользователю, что делает возможным последующий анализ процесса принятия решения о выборе кода, и, в случае необходимости внесение изменения начиная с любого шага уточнения без необходимости начинать кодирование с начала.
Предложенный сценарий использования проиллюстрирован на рис.5.
При создании автоматизированной системы поддержки кодирования на основе лексического анализа принято решение использовать следующие технологические решения (рис. 6):
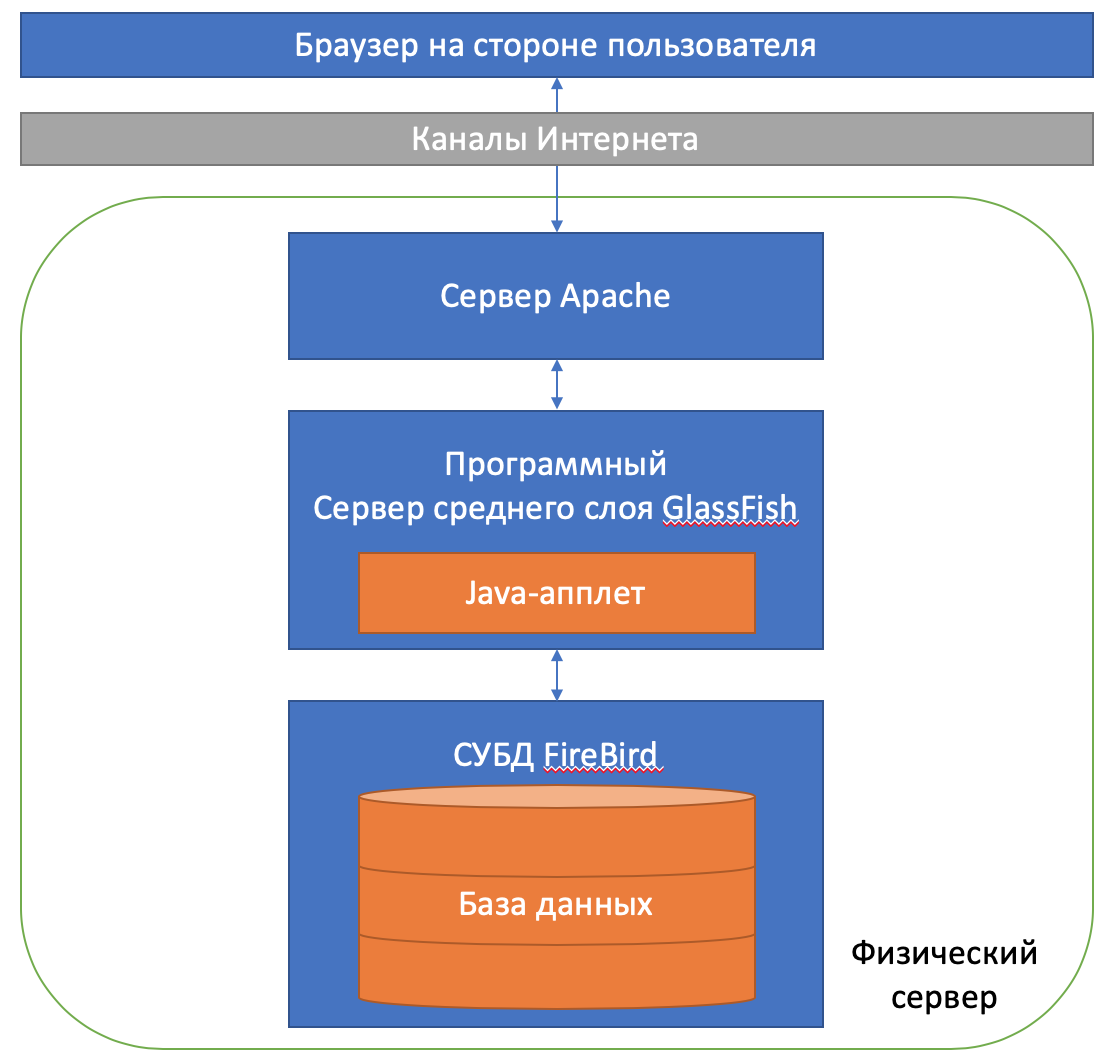
Рисунок 6 - Принципиальная схема технологических решений.
В качестве перечня поименных сервисов пользовательского доступа было принято решение использовать следующие (см. рис.7):
Сервис №1 авторизации.
Входные параметры: логин, пароль
Выходные параметры: ответ системы «не авторизован», либо сессионный ключ, которые далее передаётся каждому вызываемому сервису
Сервис предоставления пользовательского интерфейса — используется для
Входные параметры: сессионный ключ
Выходные параметры: html-страница, содержащая все необходимые интерфейсные элементы, а так же код на языке javascript, пригодный к обработке в браузере
Сервис №2 запроса записей по ведущему клиническому термину
Входные параметры: сессионный ключ, слово либо словосочетание, которое должно присутствовать в ведущем клиническом термине.
Выходные параметры: набор вида «идентификатор»/«ведущий клинический термин в полной формулировке»/«Код по МКБ-10». Далее трансформируется в интерфейсе в элемент вида «выпадающий список с возможностью выбора».
Сервис №3 сохранения результата выбора кода МКБ-10 по ведущему клиническому термину
Входные параметры: сессионный ключ, идентификатор выбранного ведущего клинического термина.
Выходные параметры: ответ о сохранении записи
Сервис №4 поиска записей уточнения по выбранному ведущему клиническому термину
Входные параметры: сессионный ключ, идентификатор ведущего клинического термина, слово либо словосочетание, которое должно присутствовать в уточняющем клиническом термине.
Выходные параметры: набор вида «идентификатор»/«уточняющий клинический термин в полной формулировке»/«наличие дополнительных уточняющих терминов». Далее трансформируется в интерфейсе в элемент вида «выпадающий список с возможностью выбора». Поведение системы при выборе зависит от отметки «наличие дополнительных уточняющих терминов». В случае их наличия система при выборе не только вызывает сервис сохранения, но и создаёт интерфейсный элемент для ввода следующего термина.
Сервис №5 сохранения результата выбора кода МКБ-10 по уточняющему клиническому термину
Входные параметры: сессионный ключ, идентификатор выбранного уточняющего клинического термина.
Выходные параметры: ответ о сохранении записи.
Сервис №6 пословного разбора
Используется на этапе разработки, для подготовки данных тома № 3 МКБ-10 к использованию сервисами №№2,3,4,5.
Входные параметры: сессионный ключ, идентификатор клинического термина
Выходные параметры: ответ о выполненном пословном разборе.
Все указанные компоненты собраны в единый программный комплекс, и пригодны к развёртыванию и использованию конечными потребителями. На сегодняшний день реализован и апробируется в Клиническом госпитале МСЧ МВД России по г. Москве (начальник – к.м.н. Мендель С.А.), являющейся базой настоящего исследования в этой части.
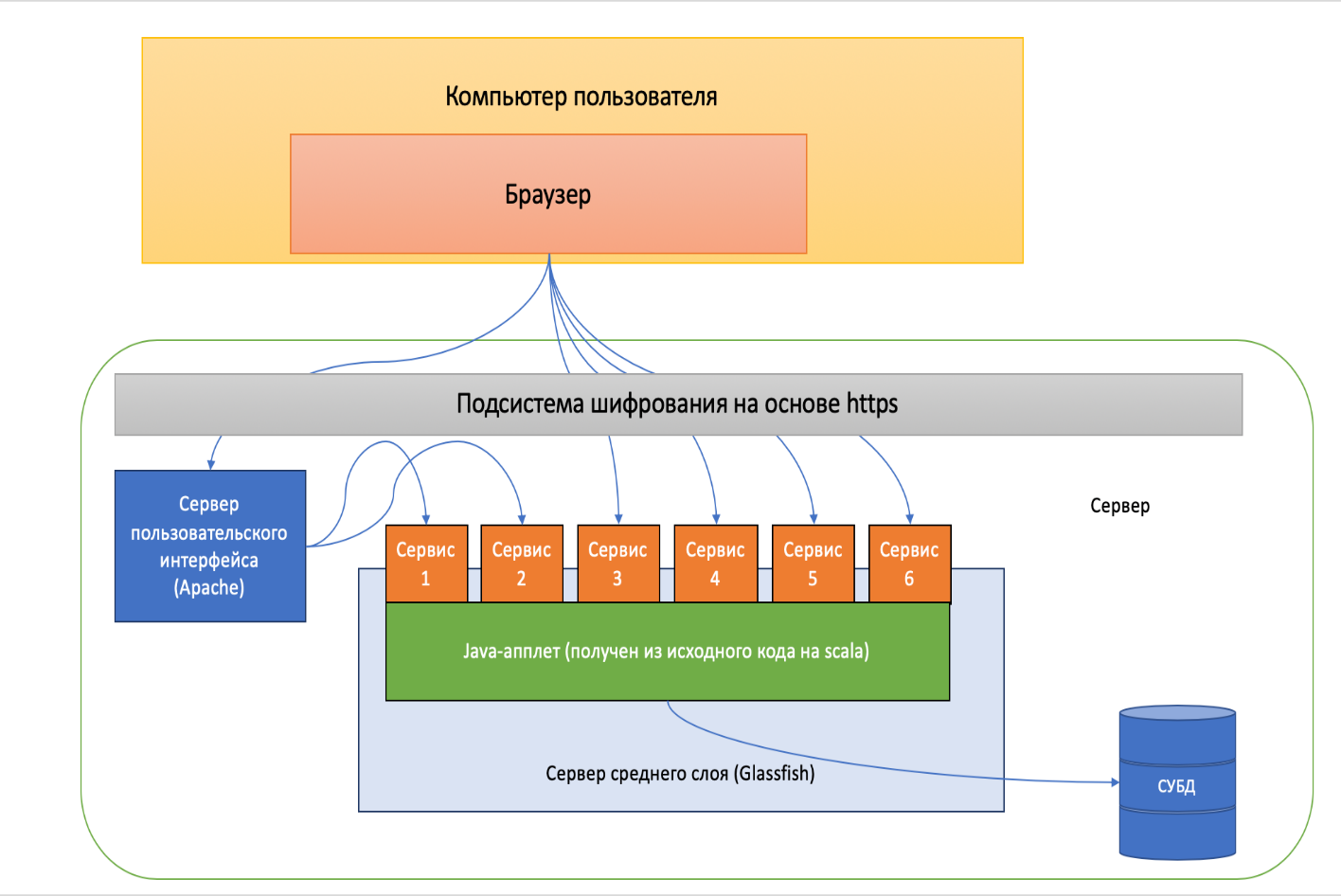
Рисунок 7 - Логическая схема создаваемой автоматизированной системы.
Для создания информационной система кодирование диагнозов и оформления свидетельств о смерти на основе международных классификаторов (автоматизированной системы поддержки кодирования по МКБ-10) с использованием лексического анализа были выбраны следующие технические характеристики:
Следует отметить, что при проектировании использован передовой международный опыт информатизации здравоохранения, зафиксированный в отечественных стандартах.
В государственной программе РФ "Информационное общество (2011 - 2020 годы)" к приоритетным задачам на период до 2015 года отнесено «создание национальной платформы распределенной обработки данных ("облачных вычислений"), включая разработку Интернет-платформы "облачных вычислений", обеспечивающей безопасную работу с типовыми программными приложениями в режиме "программа как услуга", разработку на базе национальной программной платформы набора типовых программных сервисов для использования в органах государственной власти».
В документе Open Cloud Principles некоммерческой организацией Open Cloud Initiative были сформулированы принципы построения открытых облачных систем:
Таким образом, на этапе практической реализации удалось добиться существенного снижения роли т.н. "человеческого фактора" на этапе преобразования клинического диагноза, который, конечно, формируется врачом на основе его практического опыта, теоретических знаний, и уникальных особенностей конкретного клинического случая, в диагноз статистический, который является прежде всего формальным статистическим инструментом, позволяющим оценивать структуру заболеваемости в популяции.
Метод кодирования, реализованный в системе, предполагает следующий порядок взаимодействия с пользователем:
-
Определяется ведущий термин, который вводится в соответствующее поле интерфейса информационной системы. -
Система осуществляет подбор всех записей по тому №3 МКБ-10, содержащих данный ведущий термин. При этом не рассматриваются элементы формулировок диагноза, содержащие данный термин в качестве уточняющего. -
Все найденные элементы предлагаются пользователю для выбора. -
После выбора ведущего термина фиксируется соответствующий ему код МКБ-10, и далее предлагается уточнить клиническую формулировку диагноза. Последовательное уточнение происходит до тех пор, пока имеются уточняющие записи в томе №3 МКБ-10.
Рисунок 5 - Порядок работы системы при выборе кода с использованием системы лексического анализа
Следует заметить, что в случаях, когда промежуточное уточнение делает возможным выбор кода диагноза МКБ-10, отличного от выбранного ранее, этот выбор фиксируется, и предъявляется пользователю, что делает возможным последующий анализ процесса принятия решения о выборе кода, и, в случае необходимости внесение изменения начиная с любого шага уточнения без необходимости начинать кодирование с начала.
Предложенный сценарий использования проиллюстрирован на рис.5.
- 1 2 3 4 5 6 7 8 9 ... 15
Технологические решения, положенные в основу реализации лексического анализа в автоматизированной системе поддержки кодирования по МКБ-10
При создании автоматизированной системы поддержки кодирования на основе лексического анализа принято решение использовать следующие технологические решения (рис. 6):
-
Операционная система семейства Linux -
База данных FireBird -
Сервер среднего слоя GlassFish -
Сервер веб-интерферйса Apache -
Алгоритмизация производится на языке Scala, с последующим превращением в Java -апплет -
В качестве интерфейсного(клиентского) решения используется любой браузер на основе ядра «Хромиум». Взаимодействие между клиентской частью системы и сервером реализуется по сервис-ориентированной модели, путём вызова поименованных сервисов.
Рисунок 6 - Принципиальная схема технологических решений.
В качестве перечня поименных сервисов пользовательского доступа было принято решение использовать следующие (см. рис.7):
Сервис №1 авторизации.
Входные параметры: логин, пароль
Выходные параметры: ответ системы «не авторизован», либо сессионный ключ, которые далее передаётся каждому вызываемому сервису
Сервис предоставления пользовательского интерфейса — используется для
Входные параметры: сессионный ключ
Выходные параметры: html-страница, содержащая все необходимые интерфейсные элементы, а так же код на языке javascript, пригодный к обработке в браузере
Сервис №2 запроса записей по ведущему клиническому термину
Входные параметры: сессионный ключ, слово либо словосочетание, которое должно присутствовать в ведущем клиническом термине.
Выходные параметры: набор вида «идентификатор»/«ведущий клинический термин в полной формулировке»/«Код по МКБ-10». Далее трансформируется в интерфейсе в элемент вида «выпадающий список с возможностью выбора».
Сервис №3 сохранения результата выбора кода МКБ-10 по ведущему клиническому термину
Входные параметры: сессионный ключ, идентификатор выбранного ведущего клинического термина.
Выходные параметры: ответ о сохранении записи
Сервис №4 поиска записей уточнения по выбранному ведущему клиническому термину
Входные параметры: сессионный ключ, идентификатор ведущего клинического термина, слово либо словосочетание, которое должно присутствовать в уточняющем клиническом термине.
Выходные параметры: набор вида «идентификатор»/«уточняющий клинический термин в полной формулировке»/«наличие дополнительных уточняющих терминов». Далее трансформируется в интерфейсе в элемент вида «выпадающий список с возможностью выбора». Поведение системы при выборе зависит от отметки «наличие дополнительных уточняющих терминов». В случае их наличия система при выборе не только вызывает сервис сохранения, но и создаёт интерфейсный элемент для ввода следующего термина.
Сервис №5 сохранения результата выбора кода МКБ-10 по уточняющему клиническому термину
Входные параметры: сессионный ключ, идентификатор выбранного уточняющего клинического термина.
Выходные параметры: ответ о сохранении записи.
Сервис №6 пословного разбора
Используется на этапе разработки, для подготовки данных тома № 3 МКБ-10 к использованию сервисами №№2,3,4,5.
Входные параметры: сессионный ключ, идентификатор клинического термина
Выходные параметры: ответ о выполненном пословном разборе.
Все указанные компоненты собраны в единый программный комплекс, и пригодны к развёртыванию и использованию конечными потребителями. На сегодняшний день реализован и апробируется в Клиническом госпитале МСЧ МВД России по г. Москве (начальник – к.м.н. Мендель С.А.), являющейся базой настоящего исследования в этой части.
Рисунок 7 - Логическая схема создаваемой автоматизированной системы.
Для создания информационной система кодирование диагнозов и оформления свидетельств о смерти на основе международных классификаторов (автоматизированной системы поддержки кодирования по МКБ-10) с использованием лексического анализа были выбраны следующие технические характеристики:
-
Создание на основе свободно распространяемого ПО (Linux, FireBird, Glasfish) — в свете тенденции по замене проприетарного программного обеспечения; -
Трёхзвенная архитектура — в соответствии с требованиями концепции информатизации здравоохранения; -
Территориально распределенная база данных — для возможности развёртывания в нескольких регионах одновременно; -
Работа обособленных подразделений в отдельных базах данных с единой точкой входа — что позволяет контролировать процесс на уровне органов управления здравоохранения; -
Web-интерфейс — избавляет от необходимости устанавливать программное обеспечение на рабочие места пользователей; -
Наличие средств агрегации любых имеющихся в системе данных — используется для построения отчётов произвольного формата; -
Поддержка средств визуализации агрегатов; -
Собственная система обмена сообщениями — используется для передачи уведомлений организационного характера; -
Механизмы лексического анализа — используются для обеспечения эффективной работы с классификаторами.
Следует отметить, что при проектировании использован передовой международный опыт информатизации здравоохранения, зафиксированный в отечественных стандартах.
В государственной программе РФ "Информационное общество (2011 - 2020 годы)" к приоритетным задачам на период до 2015 года отнесено «создание национальной платформы распределенной обработки данных ("облачных вычислений"), включая разработку Интернет-платформы "облачных вычислений", обеспечивающей безопасную работу с типовыми программными приложениями в режиме "программа как услуга", разработку на базе национальной программной платформы набора типовых программных сервисов для использования в органах государственной власти».
В документе Open Cloud Principles некоммерческой организацией Open Cloud Initiative были сформулированы принципы построения открытых облачных систем:
-
«обеспечение переносимости (возможности обмена и использования информации) между различными облачными продуктами и сервисами. Переносимость способствует здоровой конкуренции поставщиков и предоставляет пользователям возможность выбора; -
пользователь должен иметь возможность беспрепятственно подключиться к сервису и прекратить его использование, без дополнительных проблем с импортом и экспортом данных, без дискриминации и независимо от типа используемых систем (технологический нейтралитет); -
для представления всех пользовательских данных и мета-данных должны использоваться только форматы, соответствующие открытым стандартам; -
все функциональные возможности должны предоставляться через интерфейсы, соответствующие открытым стандартам». -
«Облачной модели присущи пять основных свойств: -
самообслуживание по требованию – потребитель в одностороннем порядке (при необходимости в автоматическом режиме) может запрашивать требуемые ему вычислительные ресурсы (например, серверное машинное время или ресурсы сетевого хранения), не вступая в непосредственные контакты с представителями поставщика услуг; -
широкополосный сетевой доступ – доступ к сетевым ресурсам осуществляется с помощью стандартных механизмов, позволяющих использовать неоднородные платформы «тонкого» или «толстого» клиента (мобильные телефоны, портативные компьютеры, и т.п.); -
пулы ресурсов – вычислительные ресурсы поставщика услуг объединяются в пулы с использованием модели множественной аренды. Разнообразные физические и виртуальные ресурсы динамически выделяются и перераспределяются в соответствии с запросами клиентов. У пользователей при этом создается ощущение независимости от конкретного местоположения. О точном местонахождении выделяемых ресурсов им ничего неизвестно, однако местоположение можно определять на более высоком уровне абстракции (с указанием, например, страны, региона или центра обработки данных (ЦОД)). К выделяемым ресурсам могут относиться ресурсы хранения, процессорные мощности, память, пропускная способность сети и виртуальные машины; -
быстрая реакция – поддерживается быстрое и эластичное распределение необходимых ресурсов (в некоторых случаях все осуществляется автоматически), их оперативное выделение и освобождение. Клиенты, как правило, не ограничены в своих запросах и могут приобретать нужные им ресурсы в любом количестве и в любое время; -
контроль над потреблением – облачные модели автоматически контролируют и оптимизируют использование ресурсов, регистрируя их потребление в соответствии с типом предоставляемых услуг (ресурсы хранения, вычислительные мощности, пропускная способность, учетные записи активных пользователей). Управление потребляемыми ресурсами и контроль данного процесса с выдачей необходимых отчетов обеспечивают требуемую прозрачность, как для поставщика услуг, так и для его клиентов».